







一、当大语言模型遇见社交舆情
在信息爆炸的社交媒体时代,微博热搜就像现实世界的数字脉搏,每分钟都在记录着数亿网民的集体注意力。传统分析方法往往受限于关键词匹配和简单统计,难以捕捉深层的语义关联和情感倾向。本文将揭示如何运用GPT-4、Claude等百亿参数大模型,结合时序分析技术,构建智能化的热搜解析系统。
二、数据工程:构建多维分析矩阵
1. 实时数据采集框架
-
使用Modified-Playwright绕过反爬机制,实现毫秒级延迟采集
-
设计多级冗余存储架构:Redis实时缓存 + MongoDB文档存储 + ClickHouse时序分析库
-
元数据捕获策略:热搜词条、实时排名、讨论量、地域分布、关联话题
# 伪代码示例:多线程热搜采集
from playwright.sync_api import sync_playwright
from concurrent.futures import ThreadPoolExecutor
def fetch_hotsearches():
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
context = browser.new_context(user_agent='Mozilla/5.0...')
page = context.new_page()
page.goto('https://weibo.com/hot')
# 使用XPath捕获动态渲染内容
hot_items = page.query_selector_all('xpath=//div[@class="hotite"]')
return [item.inner_text() for item in hot_items]
with ThreadPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(fetch_hotsearches) for _ in range(3)]2. 语义增强预处理
-
构建领域专用词库:娱乐、时政、社会等垂直领域的实体识别
-
上下文感知清洗:使用BERT-CRF模型过滤广告和噪声文本
-
多模态特征提取:嵌入表情符号的情感权重、话题传播树状结构
三、核心分析引擎设计
1. 语义理解层
-
基于Prompt Engineering的零样本分类:
"请将以下热搜归类:[娱乐|时政|社会|民生]
输入:#某明星机场穿搭# 网友热议其造型前卫
输出:娱乐"-
情感量子化分析:使用LoRA微调的LLaMA-2模型输出-1到1的情感连续值
-
事件知识图谱构建:利用Graphene框架实现实体关系抽取
2. 时序预测模块
-
融合Transformer和LSTM的混合架构
-
特征维度设计:
-
文本热度:BERT嵌入相似度变化率
-
传播势能:转发树深度/宽度比值
-
注意力衰减曲线:指数衰减因子拟合
-
四、实战案例:预测热搜生命周期
以某明星离婚事件为例:
-
初始阶段检测:识别"爆"标签的突发性(Z-score>3)
-
传播路径分析:使用GraphSAGE模型预测关键传播节点
-
消退预警:当情感熵值超过阈值0.7时触发预警
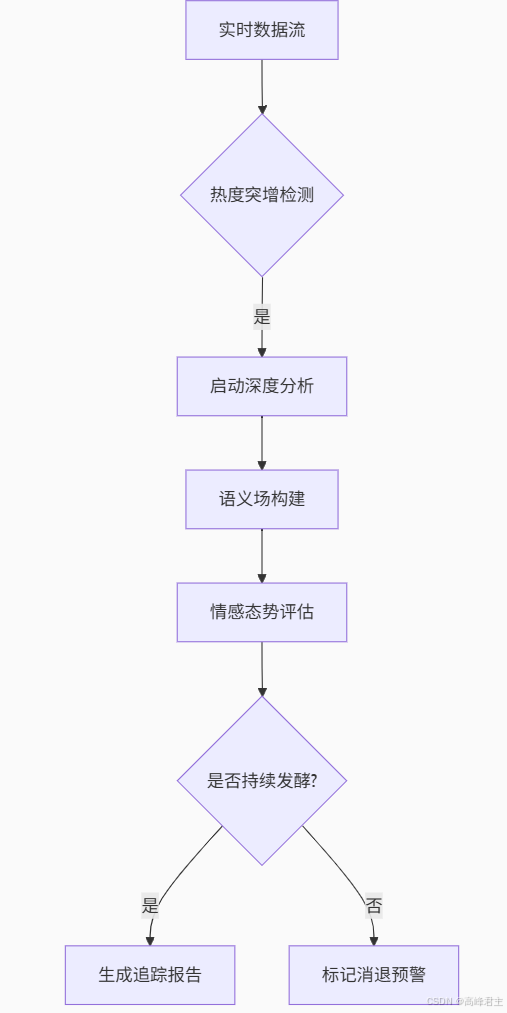
五、挑战与突破
-
实时性瓶颈解决方案:
-
使用NVIDIA Triton实现模型服务化
-
分层缓存策略:将高频查询结果存入RedisGraph
-
-
多模态融合难题:
-
CLIP模型分析关联图片的情感倾向
-
Whisper转写视频中的关键语句
-
-
可解释性增强:
-
基于Shapley值的特征贡献度分析
-
注意力可视化:热力图表征模型决策依据
-
六、未来演进方向
-
构建预测-干预闭环系统:
-
自动生成公关响应建议
-
模拟话题干预后的传播轨迹
-
-
联邦学习应用:
-
在保证隐私前提下构建跨平台分析模型
-
-
虚实空间映射:
-
将线上热度与线下传感器数据关联分析
-
结语:智能时代的舆情洞察
通过大模型与社交数据的深度耦合,我们正在从简单的热度统计迈向具有预见性的社会计算。这种技术融合不仅改变了舆情分析的范式,更重要的是为理解数字社会的运行规律提供了新的显微镜和望远镜。未来随着多模态大模型的发展,对社交热点的解读将更加立体多维,最终实现从"知其热"到"知其所以热"的认知跃迁。
实际应用中请严格遵守《个人信息保护法》和平台数据使用协议。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









