








在上一篇文章中,我们研究了Cho et al. (2014) 和Pytorch实现的Seq2Seq模型。在这篇文章中,让我们看看如何用准备好的数据训练模型,并定性地评估它。
创建编码器/解码器模型
首先,让我们分别创建编码器和解码器模型。尽管它们是共同训练和评估的,但为了使代码具有更好的可读性和可理解性,我们分别定义和创建它们。

仅仅作为参考,我们在前面的帖子中设置了超参数,如下所示。
-
MAX_SENT_LEN: 源(英文)句子的最大句子长度
-
ENG_VOCAB_SIZE, DEU_VOCAB_SIZE: 分别用英语和德语表示的唯一标记(单词)的数量
-
NUM_EPOCHS: 训练Seq2Seq模型的轮数
-
HIDDEN_SIZE: LSTM(或任意RNN变体)中隐藏空间的维数
-
EMBEDDING_DIM: 词嵌入空间的维数

训练模型
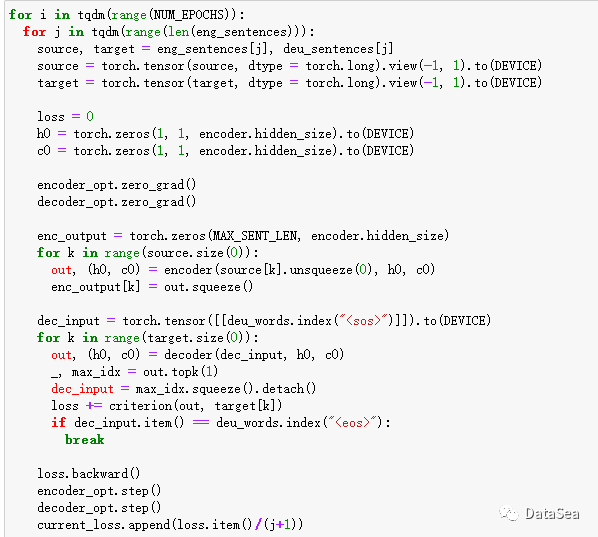
在训练模型之前,我们创建优化器并定义损失函数。编码器/解码器的优化器的定义类似于其他深度学习模型,使用Adam优化器。我们将损失函数定义为负对数似然损失,它是用于多类分类的对数函数之一。请记住,我们将每个目标词按照德语中可能的唯一词进行分类。负对数似然损失可以用torch.nn中的NLLLoss()实现。最后,将损失的追踪过程记录在current_loss列表中。

现在,我们终于准备好实际训练编码器和解码器了!
-
获取源句和目标句,并将它们转换为Pytorch张量。由于句子长度不同,我们就一个一个地训练它们。
-
初始化隐藏状态(如果使用LSTM,则初始化神经元状态)。
-
训练编码器。我们保留源句中最后输入的隐藏状态和神经元状态,并将它们传递给解码器。
-
训练解码器。解码器与编码器进行类似的训练,不同之处在于当我们遇到语句结束令牌<eos>时,记录损失和终止循环。
评估
通过查看每个实例及其输出,我们可以了解Seq2Seq模型是如何训练的。在这个例子中,让我们测试第106个句子。评估与训练非常相似,但是我们不计算梯度和更新权重。这可以通过with torch.no_grad():语句实现。
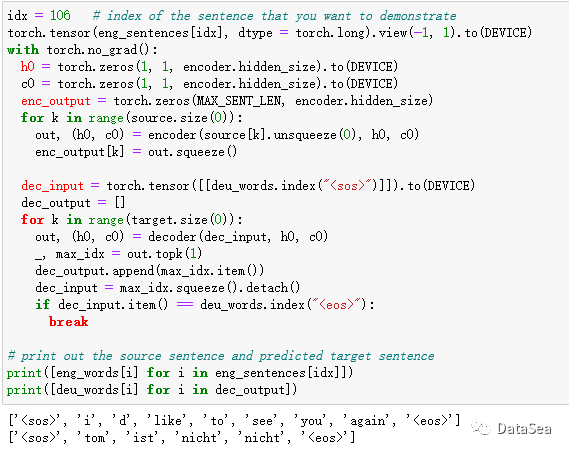
注意,这个模型训练得很差。我们只采样了50,000个实例,只训练了一个纪元,没有任何超参数调优。您可以在您的机器中尝试使用扩展数据进行各种设置。
在这篇文章中,我们研究了使用Pytorch训练和评估Seq2Seq模型。在下一篇文章中,让我们看看Cho et al. (2014)提出的RNN编码器-解码器网络的变体。感谢您的阅读。
参考文献
-
NLP FROM SCRATCH: TRANSLATION WITH A SEQUENCE TO SEQUENCE NETWORK AND ATTENTION
-
Cho et al. (2014)
更多的文章,请订阅下面的公众号。
















 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









