






1、大数据
1.大数据:是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合
1.主要解决海量的数据存储和分析计算的问题
2.数据单位
1.按大小:bit Byte KB MB GB TB PB EB ZB YB BB NB DB
3、大数据的四个特征
1. Volume(⼤数据量):90% 的数据是过去两年产生
Velocity(速度快):数据增长速度快,时效性⾼
Variety(多样化):数据种类和来源多样化 结构化数据、半结构化数据、⾮结构化数据
Value(价值密度低):需挖掘获取数据价值
4、固有的属性
1. 时效性
2. 不可变性
5、⼤数据部门的组织结构
1. 平台组
1. Hadoop,Flume,Kafka,Hbase,Spark,Hive 等框架的平台搭建
2. 集群性能监控
3. 集群性能调优
2. 数据仓库组
1. ETL⼯程师 (数据清洗)
2. 数据分析(数据仓库建模)
3. 实时组
1. 实时的指标分析,性能调优
4. 数据挖掘组
1. 算法⼯程师
2. 推荐系统
3. ⽤户画像⼯程师
6、Hadoop
1. Hadoop是⼀个开源分布式系统架构,解决海量数据存储和海量 数据计算的问题
2. 创始⼈:Doug Cutting
3. 2008年 - 成为Apache顶级项⽬
4. Hadoop发⾏版本
社区版:Apache Hadoop
Cloudera发⾏版:CDH
Hortonworks发⾏版:HDP
7、为什么使⽤Hadoop
1. ⾼扩展性
在集群间分配任务数据,可⽅便的扩展数以千计的节点
⾼可靠性
Hadoop底层维护多个数据副本
⾼容错性
Hadoop框架能够⾃动将失败的任务重新分配
低成本
Hadoop架构允许部署在廉价的机器上
灵活,可存储任意类型数据
开源,社区活跃
8、Hadoop的组成
1. hadoop 1.x
1. MapReduce(计算+资源调度)
2. HDFS (数据存储)
3. Common (辅助⼯具)
2. hadoop 2.x
1. MapReduce(计算)
2. Yarn (资源调度)
3. HDFS (数据存储)
4. Common (辅助⼯具)
9、HDFS (架构概述)
1. nn NameNode 存储⽂件的元数据, 如 ⽂件名,⽂件⽬录结构,⽂ 件属性(⽣成时间 ,副本数,⽂件权限),以及每个⽂件的块列表和块 所在的DataNode等
2. dn DataNode 在本地⽂件系统存储⽂件块数据,以及块数据的检验和
3. 2nn Secondary NameNode 每隔⼀段时间 对NameNode元数据备份
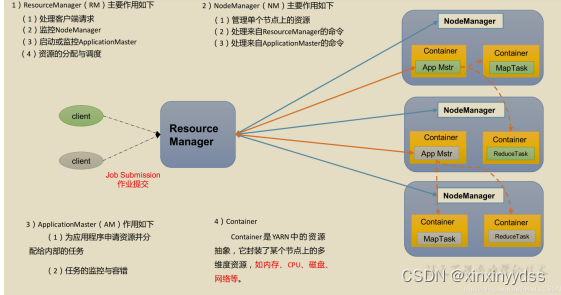
10. Yarn 架构概述
11. MapReduce 架构
1. Map 阶段并⾏处理输⼊数据
2. Reduce 阶段对Map结果进⾏汇总
12. ⼤数据的⽣态体系
1. 数据来源层
1. 数据库(结构化的数据) ⽂件⽇志(半结构化数据) 视频PPT 等(⾮结构化的数据)
2. 数据传输层
1. sqoop 数据传递 Flume⽇志收集 Kafka 消息队列
3. 数据存储层
1. HDFS存储
4. 资源管理层
1. Yarn资源管理
5. 数据计算层
1. MapReduce离线计算 -> Hive 数据查询
2. Spark Core 内存计算
1. 数据挖掘SparkMilib
2. 数据查询 Spark sql
3. 实时计算 Spark Streaming
3. Storm 实时计算
1. Flink
6. 任务调度层
1. Azkaban任务调度
7. 数据模型层
1. 数据可视化,业务应⽤
13. Hadoop运⾏环境搭建(重点)
1. 启动虚拟机hadoop101
2. 检查jdk是否已安装:java -version
4. 切换到安装包路径:cd /opt/software/并上传hadoop2.6.0.tar.gz
5. 解压安装包⽂件:tar -zxvf hadoop-2.6.0.tar.gz -C /opt/install/
6. 创建软链接:切换到install⽬录cd /opt/install 然后再创建软件 链接 ln -s hadoop-2.6.0/ hadoop 7. 添加环境变量:vi /etc/profile,并在最后添加以下两⾏
export HADOOP_HOME=/opt/install/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
8. 使配置⽂件⽣效:source /etc/profile
9. 测试试是否安装成功:hadoop version
10. 测试本地运⾏模式:当前在/opt/install/hadoop/⽬录下,创建 输⼊⽬录:mkdir wcinput
11. 创建wc.input⽂件:cd wcinput/;vi wc.input,并在⽂件中输⼊ 任意单词,然后保存退出
12. 切换到/opt/install/hadoop⽬录:cd /opt/install/hadoop
13. 执⾏程序:hadoop jar share/hadoop/mapreduce/hadoopmapreduce-examples-2.6.0.jar wordcount wcinput wcoutput
14. 查看输出⽂件:cat wcoutput/*
15. 清理测试⽂件并停机做快照















 3808
3808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









