







1.spring框架,原理,机制
1.Spring是一个开源的轻量级框架,他的核心主要有两部分组成IOC(Inversion of control)控制反转和AOP(Aspect oriented programming)面向切面编程.
什么是IOC:调用类中的方法不是通过new它的对象来实现,而是通过spring配置来创建类对象,而IOC又有两种操作方式(配置文件方式和注解方式),IOC底层运用的技术包括dom4j解析xml,工厂设计模式,反射,这三种技术
什么是Aop
系统中非核心的业务提取出来,进行单独处理
一个程序当需要扩展功能时不通过修改源代码,仅仅修改配置文件就能达到目的.aop才去横向抽取机制取代了传统纵向继承体系重复性的代码;那么它的原理是什么? 底层使用动态代理的方式实现
aop的相关术语
pointcut(切入点) :在类里面有很多的方法被增强(加功能的逻辑),真正操作的那个方法叫做切入点
Advice(通知/增强):增强的逻辑 eg:加逻辑的操作
Aspect(切面):把增强的逻辑应用到具体的方法上,这个过程叫做切面 ed:加功能到add方法的这一过程
另外Aspect本身不是Spring的一部分,只是经常个spring一起搭配使用
https://blog.csdn.net/czcnuonuo/article/details/83150858
https://www.cnblogs.com/zhaozihan/p/5953063.html
2.struts框架,原理,机制
1.概念:轻量级的MVC框架,主要解决了请求分发的问题,重心在控制层和表现层。低侵入性,与业务代码的耦合度很低。Struts2实现了MVC,并提供了一系列API,采用模式化方式简化业务开发过程。
2.与Servlet对比
优点:业务代码解耦,提高开发效率
缺点:执行效率偏低,需要使用反射、解析XML等技术手段,结构复杂
3.不同框架实现MVC的方式
Servlet:

Spring:

Struts2:

3.ibatis框架,原理,机制
iBATIS 通过 SQL Map 将 Java 对象映射成 SQL 语句和将结果集再转化成 Java 对象,与其他 ORM 框架相比,既解决了 Java 对象与输入参数和结果集的映射,又能够让用户方便的手写使用 SQL 语句。
iBATIS 框架主要的类层次结构
总体来说 iBATIS 的系统结构还是比较简单的,它主要完成两件事情:
-
根据 JDBC 规范建立与数据库的连接;
-
通过反射打通 Java 对象与数据库参数交互之间相互转化关系。
4.springmvc与struts的区别
1. 机制:
spring mvc的入口是servlet,而struts2是filter,这样就导致了二者的机制不同。
2. 性能:
spring会稍微比struts快。spring mvc是基于方法的设计,
而sturts是基于类,每次发一次请求都会实例一个action,每个action都会被注入属性,
而spring基于方法,粒度更细,但要小心把握像在servlet控制数据一样。
spring3 mvc是方法级别的拦截,拦截到方法后根据参数上的注解,把request数据注入进去,在spring3 mvc中,一个方法对应一个request上下文。
而struts2框架是类级别的拦截,每次来了请求就创建一个Action,然后调用setter getter方法把request中的数据注入;
struts2实际上是通 setter getter方法与request打交道的;struts2中,一个Action对象对应一个request上下文。
3. 参数传递:
struts是在接受参数的时候,可以用属性来接受参数,这就说明参数是让多个方法共享的。
4. 设计思想上:
struts更加符合oop(面向对象编程)的编程思想, spring就比较谨慎,在servlet上扩展。
5. intercepter的实现机制:
struts有自己的interceptor机制,spring mvc用的是独立的AOP方式。
这样导致struts的配置文件量还是比spring mvc大,虽然struts的配置能继承,所以我觉得论使用上来讲,spring mvc使用更加简洁,开发效率Spring MVC确实比struts2高。spring mvc是方法级别的拦截,一个方法对应一个request上下文,而方法同时又跟一个url对应,所以说从架构本身上spring3 mvc就容易实现restful url。
struts2是类级别的拦截,一个类对应一个request上下文;实现restful url要费劲,因为struts2 action的一个方法可以对应一个url;而其类属性却被所有方法共享,这也就无法用注解或其他方式标识其所属方法了。
spring3 mvc的方法之间基本上独立的,独享request response数据,请求数据通过参数获取,处理结果通过ModelMap交回给框架方法之间不共享变量,而struts2搞的就比较乱,虽然方法之间也是独立的,
但其所有Action变量是共享的,这不会影响程序运行,却给我们编码,读程序时带来麻烦。
6. 另外,spring3 mvc的验证也是一个亮点,支持JSR303,处理ajax的请求更是方便,只需一个注解@ResponseBody ,然后直接返回响应文本即可。
5.什么是分布式
分布式系统背景
说分布式系统必须要说集中式系统,集中式系统中整个项目就是一个独立的应用,整个应用也就是整个项目,所有的东西都在一个应用里面。
如下图所示
如一个网站就是一个应用,最后是多个增加多台服务器或者多个容器来达到负载均衡的避免单点故障的目的,当然,数据库是可以分开部署的。
集中式很明显的优点就是开发测试运维会比较方便,不用为考虑复杂的分布式环境。
集中式很明显的弊端就是不易扩展,每次更新都必须更新所有的应用。而且,一个有问题意味着所有的应用都有问题。当系统越来越大,集中式将是系统最大的瓶颈。
什么是分布式系统?
分布式系统是若干独立计算机的集合,这计算机对用户来说就像单个相关系统。
以上定义摘自<<分布式系统原理与范型>>一书。
也就是说分布式系统背后是由一系列的计算机组成的,但用户感知不到背后的逻辑,就像访问单个计算机一样。
说的有点绕,我们可以来简单看下分布式系统图。
分布式系统利弊
在分布式系统中:
1、应用可以按业务类型拆分成多个应用,再按结构分成接口层、服务层;我们也可以按访问入口分,如移动端、PC端等定义不同的接口应用;
2、数据库可以按业务类型拆分成多个实例,还可以对单表进行分库分表;
3、增加分布式缓存、搜索、文件、消息队列、非关系型数据库等中间件;
很明显,分布式系统可以解决集中式不便扩展的弊端,我们可以很方便的在任何一个环节扩展应用,就算一个应用出现问题也不会影响到别的应用。
随着微服务Spring Cloud & Docker的大热,及国内开源分布式Dubbo框架的重生,分布式技术发展非常迅速。
分布式系统虽好,也带来了系统的复杂性,如分布式事务、分布式锁、分布式session、数据一致性等都是现在分布式系统中需要解决的难题,虽然已经有很多成熟的方案,但都不完美。分布式系统也增加了开发测试运维成本,工作量增加,分布式系统管理不好反而会变成一种负担。
原文:https://blog.csdn.net/youanyyou/article/details/79406507
6.io理解
应用程序的IO操作分为两种动作:IO调用和IO执行。IO调用是由进程发起,IO执行是操作系统的工作。
以一个进程的输入类型的IO调用为例,它将完成或引起如下工作内容:
- 进程向操作系统请求外部数据
- 操作系统将外部数据加载到内核缓冲区
- 操作系统将数据从内核缓冲区拷贝到进程缓冲区
- 进程读取数据继续后面的工作
阻塞和非阻塞IO
阻塞和非阻塞强调的是进程对于操作系统IO是否处于就绪状态的处理方式。
从编程的角度讲述了程序员应该如何去理解IO编程的一些概念。其关键点是要将应用程序的IO操作分为两个步骤来理解:IO调用和IO执行。IO调用才是应用程序干的事情,而IO执行是操作系统的工作。在IO调用时,对待操作系统IO就绪状态的不同方式,决定了其是阻塞或非阻塞模式;在IO执行时,线程或进程是否挂起等待IO执行决定了其是否为同步或异步IO。
https://blog.csdn.net/INK_FUNC/article/details/79588565
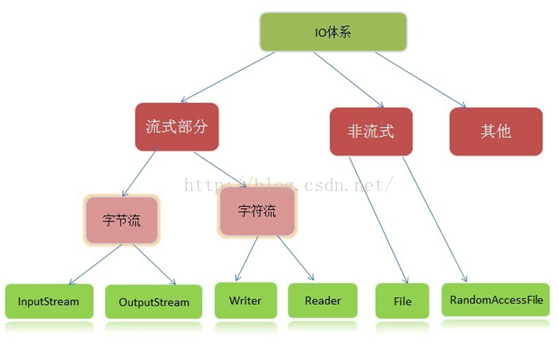
在整个Java.io包中最重要的就是5个类和一个接口。5个类指的是File、OutputStream、InputStream、Writer、Reader;一个接口指的是Serializable.掌握了这些IO的核心操作那么对于Java中的IO体系也就有了一个初步的认识了
Java I/O主要包括如下几个层次,包含三个部分:
1.流式部分――IO的主体部分;
2.非流式部分――主要包含一些辅助流式部分的类,如:File类、RandomAccessFile类和FileDescriptor等类;
3.其他类--文件读取部分的与安全相关的类,如:SerializablePermission类,以及与本地操作系统相关的文件系统的类,如:FileSystem类和Win32FileSystem类和WinNTFileSystem类。
主要的类如下:
1. File(文件特征与管理):用于文件或者目录的描述信息,例如生成新目录,修改文件名,删除文件,判断文件所在路径等。
2. InputStream(二进制格式操作):抽象类,基于字节的输入操作,是所有输入流的父类。定义了所有输入流都具有的共同特征。
3. OutputStream(二进制格式操作):抽象类。基于字节的输出操作。是所有输出流的父类。定义了所有输出流都具有的共同特征。
4.Reader(文件格式操作):抽象类,基于字符的输入操作。
5. Writer(文件格式操作):抽象类,基于字符的输出操作。
6. RandomAccessFile(随机文件操作):一个独立的类,直接继承至Object.它的功能丰富,可以从文件的任意位置进行存取(输入输出)操作。
Java中IO流的体系结构如图:
b、Java流类的类结构图:
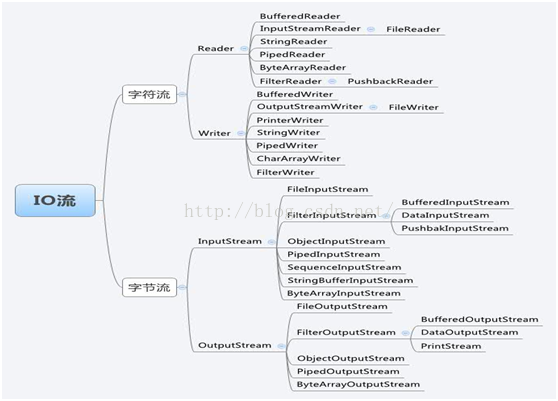
字节流和字符流的区别(重点)
字节流和字符流的区别:(详细可以参见http://blog.csdn.net/qq_25184739/article/details/51203733)
节流没有缓冲区,是直接输出的,而字符流是输出到缓冲区的。因此在输出时,字节流不调用colse()方法时,信息已经输出了,而字符流只有在调用close()方法关闭缓冲区时,信息才输出。要想字符流在未关闭时输出信息,则需要手动调用flush()方法。
读写单位不同:字节流以字节(8bit)为单位,字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
· 处理对象不同:字节流能处理所有类型的数据(如图片、avi等),而字符流只能处理字符类型的数据。
结论:只要是处理纯文本数据,就优先考虑使用字符流。除此之外都使用字节流。
https://www.cnblogs.com/ylspace/p/8128112.html
7.多线程理解
8.集合理解
9.JVM原理
10.性能调优
11.数据库mysql,Oracle的区别















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









