






按照书中的源码 输入,遇到 引入 爆红线
from custom_gestures.gesture_box import GestureBox
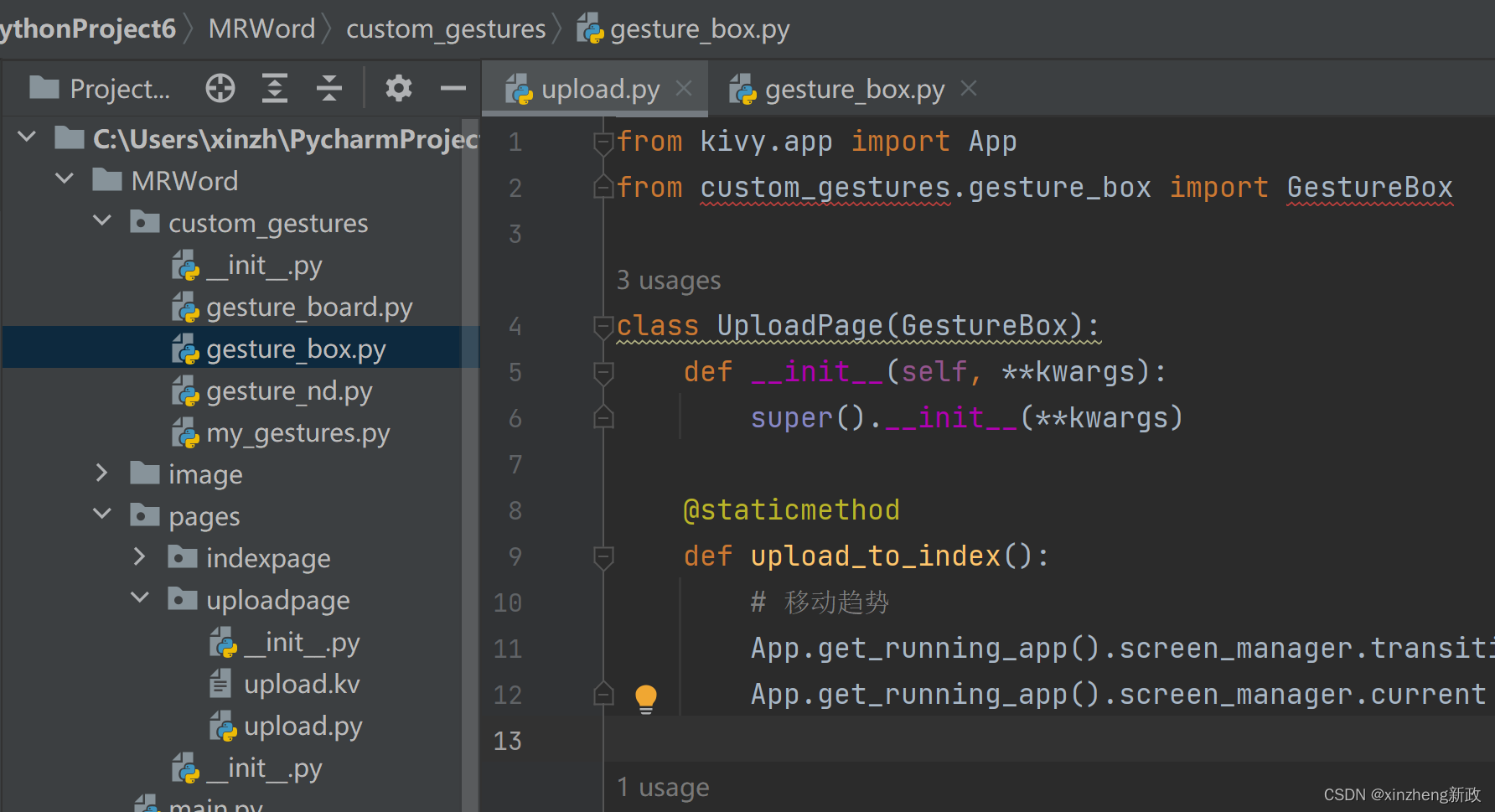
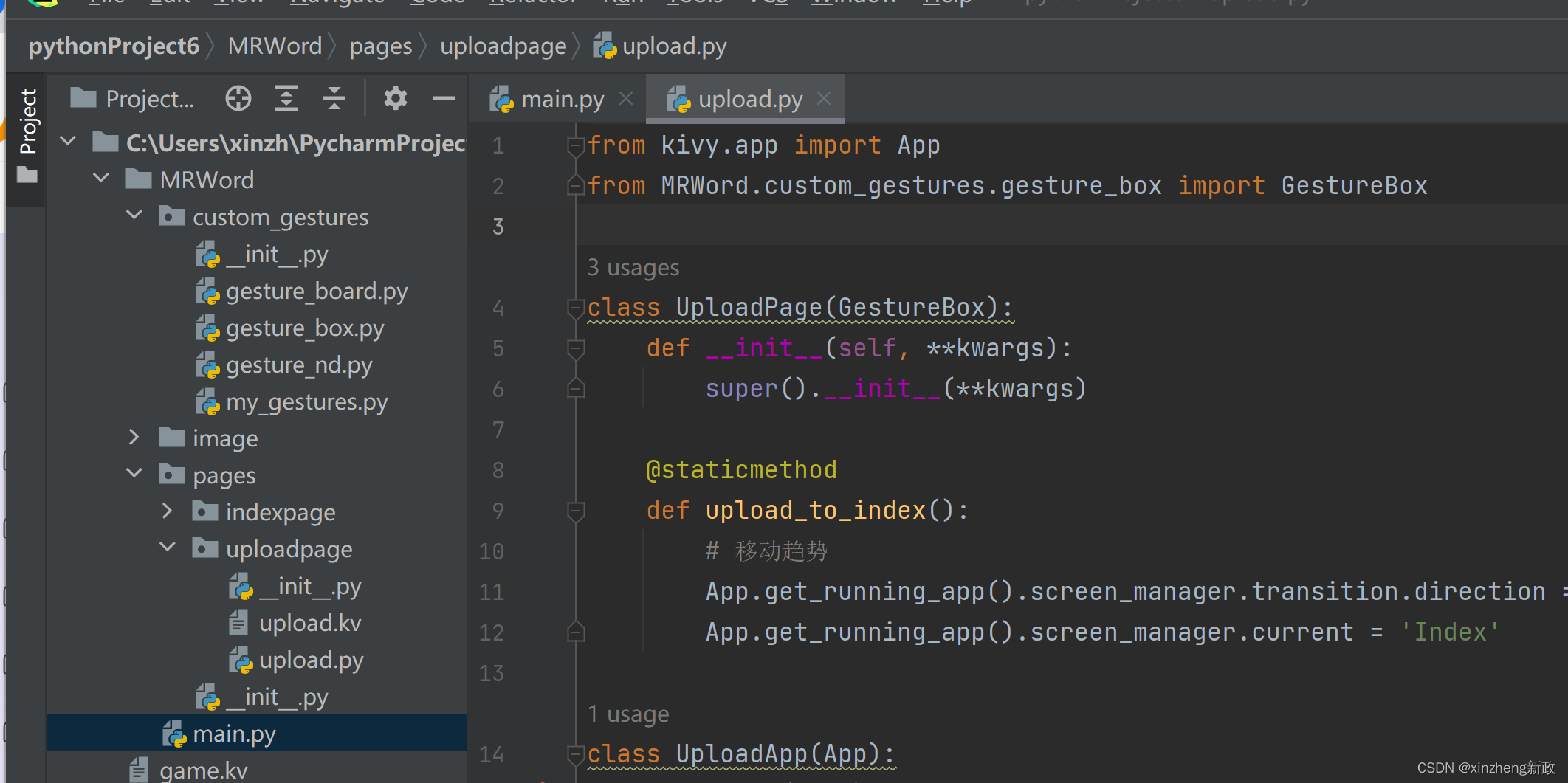
加上总目录文件夹名称搞定。
MRWord/importfile/import_much.py
import os
import re
import datetime
import logging
def add_word(word):
""" 添加有效单词 """
pass # 具体内容 将在2.5.10小节介绍
def sub_cn(content):
""" 通过正则表达式替换中文字符为, """
# 替换中文
pattern_cn = re.compile(r'[\u4e00-\u9fa5]')
english = re.sub(pattern_cn, ',', content)
# 替换数字
pattern_num = re.compile(r'[0-9]')
english = re.sub(pattern_num, ',', english)
# 替换特殊字母
r = ['n.','a.','adj.','adv.','vi.','vt.','prep.','ad.']
for r_r in r:
english = english.replace(r_r, '')
# 替换符号
r = ']”“。,‘’——{}【】、|《》?·~!@#¥%……&*()/\\><()^_!,-.;:>+="\'['
english = re.sub(r'[{}]+'.format(r), ',', english)
# 替换换行
english = english.replace("\r\n", ",")
# 替换空格
english = english.lower().replace(" ","").strip()
return english
def common_handle(content):
""" 各种文件共同的处理方法,传入str字符串 """
content = str(content)
logging.info('content:' + content)
# 去除多余字符
file_content = sub_cn(content)
# 按','拆分
str_list = file_content.split(',')
logging.info('we are ready to add_word()')
for s in str_list:
# 添加有效单词
add_word(s)
def pdf_read(file):
""" 读取PDF文件 """
# pip install pdfminer3k
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
fp = open(file, 'rb')
# 用文件对象创建一个PDF文档分析器
parser = PDFParser(fp)
# 创建一个PDF文档
doc = PDFDocument()
# 连接分析器与文档对象
parser.set_document(doc)
doc.set_parser(parser)
# 提供初始化密码,如果没有密码就创建一个空的字符串
doc.initialize()
# 检测文档是否提供txt转换, 不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建PDF资源管理器来共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释其对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 遍历列表,每次处理一个page内容
# doc.get_pages()获取page列表
for page in doc.get_pages():
interpreter.process_page(page)
# j接受该页面的LTPage对象
layout =device.get_result()
# 这里layout是一个LTPage对象里面存放着这个page解析出的各种对象
# 一般包括LTTextBox、 LTFigure、 LTImage、 LTTextBoxHorizontal等
# 通过对象的text属性获取文本
for x in layout:
if isinstance(x, LTTextBoxHorizontal):
results = x.get_text()
common_handle(results)
def excel_read(file):
""" 读取.xlsx文件 """
# pip install xlrd
import xlrd
workbook = xlrd.open_workbook(file)
for sheet in workbook.sheets():
row = sheet.nrows # sheet行数
col = sheet.ncols # sheet列数
for i in range(row):
for j in range(col):
value = str(sheet.cell_value(i, j))
# 调用公共的处理方法
common_handle(value)
def txt_read(file):
""" 读取.txt文件 """
logging.info('txt_read will run')
import chardet
logging.info('txt_read is running')
with open(file, "rb") as f:
logging.info('file has opened')
file_data = f.read()
result = chardet.detect(file_data)
# 解码
file_content = file_data.decode(encoding=result['encoding'])
# 调用公共的处理方法
logging.info('is ready to run common_handle')
common_handle(file_content)
def docx_read(file):
""" 读取.docx文件 """
logging.info('docx_read is running')
# pip install python_docx
from docx import Document
logging.info('Document has been imported')
doc = Document(file)
logging.info('Document finish')
# 读取每一行文本,一个换行符算一行
for paragraph in doc.paragraphs:
# 调用公共的处理方法
common_handle(paragraph.text)
# d读取表格的方法, 按需添加
# for table in doc.tables:
# for row in table.rows:
# for cell in row.cells:
# print(cell.text)
def import_file(file):
""" 导入文件 """
logging.info('start import file!!!')
# 获取文件后缀
postfix = os.path.splitext(file)[-1][1:]
logging.info('postfix:' +postfix)
if postfix == 'txt':
logging.info('It\'s ready to read txt')
txt_read(file)
elif postfix == 'docx':
logging.info('It\'s ready to read docx')
docx_read(file)
elif postfix == 'xlsx':
excel_read(file)
elif postfix == 'pdf':
pdf_read(file)
else:
logging.info('Can\'t import %s file' % postfix)
if __name__ == '__main__':
# docx_read()
# txt_read()
# excel_read()
# sub_cn()
# pdf_read()
# check_word('hello')
import_file('test.tqt')
def sub_cn(content):
re.compile
re.compile是Python标准库中的一个函数,它用于将正则表达式编译成模式对象,从而可以使用这个模式对象对文本进行匹配。使用re.compile编译正则表达式可以提高程序的效率,因为它可以缓存已编译的模式对象,避免了重复编译同一个正则表达式的开销。
下面是re.compile函数的基本用法:
import re
pattern = re.compile(r'\d+') # 将正则表达式编译成模式对象
result = pattern.findall('hello 123 world 456') # 使用模式对象进行匹配
print(result)输出结果为:
['123', '456']re.sub
re.sub()是Python中的一个正则表达式函数,用于在字符串中执行正则表达式的替换操作。该函数可以在指定的字符串中查找与正则表达式匹配的子字符串,并将其替换为指定的字符串。
re.sub()函数的语法如下: re.sub(pattern, repl, string, count=0, flags=0)
其中,pattern表示要匹配的正则表达式;repl表示替换的字符串;string表示要进行替换操作的字符串;count表示替换的次数,如果为0,则表示替换所有匹配项;flags表示匹配模式,如是否区分大小写等。
例如,以下代码使用re.sub()函数将字符串中的所有数字替换为“#”:
import re
string = "there are 123 cats and 456 dogs"
new_string = re.sub(r'\d+', '#', string)
print(new_string)输出结果为:“there are ### cats and ### dogs”
.replace()
.replace()是Python中字符串对象的一个方法,它的作用是将一个指定的子字符串替换为另一个字符串,并返回新的字符串。replace()方法的语法如下:
str.replace(old, new[, count])其中,old表示要被替换的子字符串,new表示用来替换的新字符串,count是可选参数,表示替换的次数。如果不指定count,则默认替换所有出现的子字符串。
例如,假设我们有一个字符串s=“hello world”,我们想要将其中的"world"替换为"python",可以使用如下代码:
s = "hello world"
new_s = s.replace("world", "python")
print(new_s)输出结果为:“hello python”
.strip()
strip()是Python字符串对象的方法,用于去除字符串首尾的空白字符(包括空格、制表符、换行符等)。如果不指定参数,则默认去除字符串首尾的空白字符,如果指定参数,则去除字符串首尾指定的字符。例如:
str = " hello world "
print(str.strip()) # 输出 "hello world"
str = "----hello world++++"
print(str.strip('-+')) # 输出 "hello world"def common_handle(content):
logging.info()
logging.info() 是 Python 的 logging 模块提供的一个函数,它用于将一条信息以 INFO 级别记录到日志中。logging 模块是 Python 标准库中的一个模块,它提供了强大的日志功能,可以用来记录应用程序的运行状态和错误信息等。
使用 logging.info() 函数可以将一条信息记录到日志中,以便后续分析和排查问题。在调试和开发过程中,我们可以通过修改日志级别来控制输出信息的多少,以便更好地进行调试和排查问题。
例如,我们可以将日志级别设置为 DEBUG,这样就可以输出更详细的信息。而如果将日志级别设置为 ERROR,则只会输出错误信息。通过灵活地控制日志级别,我们可以在开发和测试中更好地使用 logging 模块。
.split()
.split()是Python中的一个字符串方法,它可以按照指定的分隔符将一个字符串分割成多个子字符串,并将这些子字符串存储到一个列表中返回。例如,如果我们有一个字符串"hello world",我们可以使用split方法按照空格分割这个字符串,并将"hello"和"world"存储到一个列表中返回。该方法的基本语法如下:string.split(separator, maxsplit)。其中,separator参数是一个字符串,用于指定分隔符,默认为所有空字符(包括空格、换行符等);maxsplit参数是一个整数,用于指定最大分割次数,默认值为-1,表示所有可能的分割。如果指定了maxsplit,则分割次数不超过maxsplit次。例如:“hello world”.split()会返回[‘hello’, ‘world’],而"hello-world".split(‘-’)会返回[‘hello’, ‘world’]。
pdfminer3k
pdfminer
PDFMiner是一个用于解析PDF文档的Python库。它可以将PDF文档转换为纯文本或HTML格式,也可以获取PDF文档中的元数据信息、图像和矢量图形。PDFMiner支持几乎所有的PDF版本,包括PDF 1.7和Acrobat 8.0及以上版本。PDFMiner的主要特点包括解析速度快、易于使用、可定制性强等。
PDFMiner的安装非常简单,只需要使用pip命令即可进行安装。安装完成后,你可以使用PDFMiner中的命令行工具或Python脚本来解析PDF文档。
pdfminer.pdfparser
pdfminer.pdfparser是Python中的一个PDF解析器,可以用来提取PDF文档中的数据和元数据。它包含了PDF解析器的主要功能,包括解析PDF文档中的所有对象、读取和解析页面内容、提取文本、图像和路径等。它还可以读取和解析加密的PDF文件,支持多种加密算法和安全策略。此外,pdfminer.pdfparser还具有可扩展性,用户可以自定义特定的处理程序来解析PDF文档中的特定对象或元数据。总之,pdfminer.pdfparser是一个强大的PDF解析器,可以方便地提取PDF文档中的信息。
PDFParser
pdfminer.pdfparser中的PDFParser是一个用于解析PDF文件的类,主要功能是将PDF文件中的内容提取出来并转化成Python中的数据结构。常用的方法如下:
-
init(fp, password=‘’, decompress=True):构造函数,用于初始化PDFParser对象。
-
set_document(doc):设置解析的PDF文档。
-
parse_dict(d, objid):解析一个字典对象。
-
parse_stream(stream, d):解析一个流对象。
-
resolve(objid):根据对象ID获取对象。
-
getpos():获取当前位置信息。
-
flush():刷新当前位置信息。
PDFDocument
PDFDocument是pdfminer库中的一个类,它用于表示PDF文档。该类包含了文档的元数据、页面信息、目录等等信息,并提供了一些方法用于获取和修改这些信息。
PDFDocument类的常用方法包括:
- set_parser(parser):设置解析器。
- set_parser_method(parser, methodname):设置解析器使用的方法名。
- initialize(password=“”):初始化文档。
- get_outlines():获取文档的目录结构。
- get_destinations():获取文档内的所有目标。
- get_nameddestinations():获取文档内所有命名目标。
- get_pages():获取文档中所有页面。
- get_page_layout(page_number):获取指定页面的页面布局。
如果你需要从PDF文件中提取信息或者操作PDF文件,可以使用pdfminer库中的PDFDocument类进行处理。
pdfminer.pdfinterp
pdfminer.pdfinterp是Python PDF解析器库pdfminer的一个子模块,它提供了PDF解析器的核心功能。该模块主要负责解析PDF文件中的内容,包括文本、图像、字体、颜色等,并将其转换为Python可处理的格式。pdfinterp中最重要的类是PDFInterpreter,它是解析PDF文件的核心类,可以执行PDF文件中的操作,例如渲染页面、解码图像、解析文本等。此外,pdfinterp还包括一些辅助类和函数,用于处理和转换PDF文件中的各种对象。如果您需要从PDF文件中提取文本或图像等信息,pdfminer.pdfinterp将是一个非常有用的工具。
interpreter 美/ɪnˈtɜːrprətər/ n.口译者,译员;演奏者,表演者;解释程序
PDFResourceManager
在PDF解析过程中,PDFResourceManager主要用于管理各种资源,比如字体、图片等,而PDFPageInterpreter则是用于解释PDF文件中的页面内容,进行渲染和呈现。一般而言,PDFResourceManager和PDFPageInterpreter是一对配合使用的类,它们能够协同完成PDF文件的解析、渲染和呈现。
具体来说,PDFResourceManager提供了各种资源的管理方法,比如获取字体、图片等资源,同时也可以将资源缓存起来以便后续使用。
PDFPageInterpreter
PDFPageInterpreter则提供了解析PDF页面的方法,包括获取页面内容、解析页面内容并进行渲染和呈现等操作。它可以通过调用PDFDevice中的方法将页面内容呈现到各种输出设备上,比如屏幕、打印机等。
PDFPageInterpreter是pdfminer中的一个类,它用于解析PDF页面内容。以下是PDFPageInterpreter的一些常用方法:
-
process_page(page) 该方法将给定的页面对象page解析为文本并输出。例如:
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
interpreter = PDFPageInterpreter(resource_manager, device)
for page in PDFPage.get_pages(fp):
interpreter.process_page(page)2. render_page(page, device) 该方法将给定的页面对象page渲染到设备上,并返回渲染后的结果。例如:
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
interpreter = PDFPageInterpreter(resource_manager, device)
for page in PDFPage.get_pages(fp):
interpreter.render_page(page, device)3. run_stream(stream, device, params=None) 该方法将给定的流对象stream解析为文本,并输出到设备上。例如:
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
interpreter = PDFPageInterpreter(resource_manager, device)
interpreter.run_stream(stream, device)4. reset() 该方法重置解释器状态,以便重新解析PDF文档。
PDFTextExtractionNotAllowed
pdfminer.pdfinterp中的PDFTextExtractionNotAllowed是一个异常类,表示PDF文档中的文本提取操作不被允许。当我们尝试使用pdfminer提取PDF文档中的文本时,如果该PDF文档设置了禁止文本提取权限,那么就会抛出该异常。
在PDF中,有时候会设置文本提取权限来保护PDF的内容,这种权限可以通过密码或数字签名来实现。如果我们没有正确的密码或数字签名,就无法提取PDF文档中的文本内容。在这种情况下,如果我们尝试使用pdfminer提取PDF文档中的文本,就会抛出PDFTextExtractionNotAllowed异常。
如果我们想要使用pdfminer提取受保护的PDF文档中的文本,我们需要先获取正确的密码或数字签名,并将其传递给pdfminer,以便正确地解除文本提取权限。
pdfminer.converter
converte 美/kənˈvɜːrtər/ n.使转变的人(或物);转换器;整流器;变频器;转换程序;变焦镜
pdfminer.converter是Python中一个用于PDF解析的工具库,它可以将PDF文档转换为纯文本、HTML、XML和其他格式。它是pdfminer库的一部分,pdfminer库是一个完整的PDF解析工具,提供了从PDF中提取文本、元数据和嵌入式图像的功能。pdfminer.converter库通过使用pdfminer库中的解析器来解析PDF文档,并将其转换为指定格式的输出。
pdfminer.converter支持多种不同的输出格式,包括纯文本、HTML、XML、JSON和其他自定义格式。用户可以根据自己的需求选择合适的输出格式。同时,pdfminer.converter还提供了一些参数,可以用于控制输出格式的一些细节,例如字体、行距和缩进等。
如果你需要从PDF文档中提取文本或其他信息,pdfminer.converter是一个非常有用的工具库。
PDFPageAggregator
aggregator 美/ˈæɡrɪɡeɪtər/ n.聚合器,整合者;汇集者,聚合
PDFPageAggregator是pdfminer.converter模块中的一个类,它是用来处理PDF页面内容的。在解析PDF页面的时候,PDFPageAggregator会将PDF页面中的各个元素(例如文字、图片、矩形等)进行聚合,然后按照它们在页面上出现的顺序进行排序,最终生成一个包含所有元素的列表。这个列表可以用于进一步的处理和分析,比如进行文本识别或者图像提取等。
具体来说,PDFPageAggregator类中的process_page方法会接收一个PDF页面作为输入,然后返回一个包含所有元素的列表。在这个过程中,PDFPageAggregator会将页面中的所有元素遍历一遍,并将它们添加到一个列表中。当遍历完成之后,PDFPageAggregator会按照元素在页面上出现的顺序对它们进行排序,并返回最终的列表。
PDFPageAggregator是pdfminer.converter模块中的一个类,它用于将PDF页面解析为LTPage对象列表。常用的方法包括:
pdfminer3k/pdfminer/converter.py at master · canserhat77/pdfminer3k · GitHub
- init_page(self, page): 初始化一个新页面。
- receive_layout(self, ltpage): 接收页面布局,将其添加到页面列表中。
- get_result(self): 获取所有解析出的页面的LTPage对象列表。
在PDF解析中,LT表示Line Text,即线段文本。 LTPage对象列表是PDF解析后每一页的文本内容的列表,其中包含了多个LT对象,每个LT对象表示一页中的一个文本块,它们包含了文本内容、坐标信息、字体信息等属性。通常,可以将这些LT对象组合起来形成完整的文本内容。
pdfminer.layout
pdfminer.layout是Python中一个用于解析PDF文档中文本和布局信息的库。它可以从PDF文件中提取文本和字体信息,并将其组织成页面和布局的结构化对象,使得我们可以方便地处理、分析和提取PDF文档中的信息。
pdfminer.layout库主要包含以下几个模块:
- LTPage:表示PDF文档中的一页,包含多个LTTextBox、LTFigure等对象。
- LTTextBox:表示PDF文档中的一个文本框,包含多个LTTextLine对象。
- LTTextLine:表示PDF文档中的一行文本,包含多个LTChar对象。
- LTChar:表示PDF文档中的一个字符,包含字符的位置、字体、大小等信息。
使用pdfminer.layout库可以方便地提取PDF文档中的文本信息,并进行格式化处理,例如排除页眉页脚、分列等。同时,由于pdfminer.layout提供了字符级别的信息,因此也可以方便地进行关键词搜索、文本分析等操作。
LTTextBoxHorizontal
pdfminer.layout 是一个Python库,用于从PDF文件中提取文本和其它布局信息。其中,LTTextBoxHorizontal 是 PDF 中的一个文本块,表示在同一水平线上的一行文本。它包含一系列的 LTTextLineHorizontal 对象,每个对象代表该行中的一段文本。
LAParams
LAParams 是 pdfminer.layout 中的一个类,用于定义 PDF 解析器如何解析文档。它可以包含多个参数,包括:
- char_margin:字符边距,用于控制字符之间的最小间距。
- line_margin:行边距,用于控制行之间的最小间距。
- word_margin:单词边距,用于控制单词之间的最小间距。
- boxes_flow:是否按照字框的顺序来解析文本。
- detect_vertical:是否检测垂直文本。
- all_texts:是否输出所有文本(包括隐藏文本)。
LTTextBoxHorizontal 和 LAParams 是 pdfminer.layout 中的两个重要概念,它们可以帮助我们更好地理解和处理 PDF 中的文本信息。
extractable 美/ɪkˈstræktəbl/ adj.可抽出的,可榨出的;可推断出的
isinstance
isinstance()是Python中的一个内置函数,用于检查一个对象是否是一个特定类或其子类的实例。isinstance()函数的语法为:
isinstance(object, classinfo)其中,object表示要检查的对象,classinfo表示要检查的类或类型,可以是一个类对象、类型对象或由它们组成的元组。
如果object是classinfo的一个实例或者是其子类的实例,则返回True;否则返回False。这个函数常用于判断某个对象是否属于特定的类型或类。
举个例子,判断一个变量是否是字符串类型的方法如下:
if isinstance(my_var, str):
print("my_var是字符串类型")
else:
print("my_var不是字符串类型")get_text()
get_text() 方法通常用于从 pdfminer 的布局对象中提取文本内容。
假设 x 是一个 pdfminer 的布局对象,比如 LTTextBoxHorizontal 或 LTTextLine 等,get_text() 方法将返回该对象表示的文本字符串。
def excel_read(file):
pip install xlrdxlrd
xlrd是Python中一个常用的第三方库,主要用于读取Excel文件。以下是xlrd的一些常用方法:
1.打开Excel文件:xlrd.open_workbook(filename)
2.获取sheet数量:workbook.nsheets
3.获取sheet名称:workbook.sheet_names()
4.获取指定sheet:workbook.sheet_by_name(sheet_name)或者workbook.sheet_by_index(sheet_index)
5.获取行数和列数:sheet.nrows和sheet.ncols
6.获取某个单元格的值:sheet.cell_value(row, col)
7.获取某个单元格的数据类型:sheet.cell_type(row, col)
8.获取某个单元格的格式:sheet.cell_xf_index(row, col)
9.获取日期格式的值:xlrd.xldate_as_tuple(cell_value, datemode)
10. workbook.sheets 文件的页面们
def txt_read():
chardet
Chardet是一个Python库,用于自动检测给定文本的编码类型。它可以自动检测多种编码类型,如UTF-8、GBK、ISO-8859-1等等。Chardet可以通过分析文本中的字符集来推断文本的编码类型,该库基于统计分析算法实现。Chardet已经被广泛使用在许多Python应用程序中,尤其是在爬虫、文本处理和数据分析方面。
chardet是一个用于字符编码识别的Python第三方库。它能够自动检测给定文本的字符编码类型,从而避免了在处理文本时出现编码不匹配的问题。
常用的chardet方法如下:
detect 美/dɪˈtekt/ v.查明,察觉;测出,检测,识别
- detect方法:用于检测给定文本的字符编码类型,返回一个字典类型的结果,包含了编码名称、编码置信度等信息。
- UniversalDetector类:可用于逐行读取文本文件,并自动检测文件编码类型。
- detect_all方法:可用于批量检测多个文本文件的编码类型,返回一个包含了文件名称、编码名称、编码置信度等信息的列表。
file_content = file_data.decode(encoding=result[‘encoding’])这段代码将一个二进制文件数据解码成字符串,其中file_data是二进制的文件数据,result是对该文件进行编码检测后的结果,其包含了该文件的编码方式。通过result['encoding']可以获取到该文件的编码方式,然后使用该编码方式对二进制数据进行解码,得到字符串形式的文件内容。最终,file_content变量中存储的是字符串形式的文件内容。
.decode()
.decode() 是 Python 中用于解码字节数据(bytes 类型)到字符串(str 类型)的方法。这个方法通常用于将字节数据转换成人类可读的字符串形式。
例如,如果你有一个包含字节数据的变量 byte_data,你可以这样解码它:
byte_data = b'This is a byte string'
decoded_str = byte_data.decode()
print(decoded_str) # 输出: This is a byte string .decode() 方法还可以接受一个参数,即编码的名称,用于指定字节数据的编码方式。例如,如果你知道字节数据是用 UTF-8 编码的,你可以明确地指定编码:
utf8_data = b'This is a byte string'.decode('utf-8')
print(utf8_data) # 输出: This is a byte string 在处理网络数据、文件读写或者跨不同编码边界的数据时,.decode() 方法非常有用。例如,在读取以特定编码保存的文本文件时,你需要先将文件内容读取为字节,然后解码这些字节以获得字符串。
需要注意的是,如果字节数据不是以指定的编码方式编码的,那么在解码时就会产生一个 UnicodeDecodeError。为了避免这种情况,可以使用 try-except 语句来处理可能出现的异常:
try:
decoded_str = byte_data.decode('utf-8')
except UnicodeDecodeError as e:
print(f"Decoding error: {e}")或者,可以使用 errors 参数来指定如何处理解码错误,例如:
decoded_str = byte_data.decode('utf-8', errors='replace')def docx_read(file):
python_docx
pip install python_docxGitHub - python-openxml/python-docx: Create and modify Word documents with Python
Python-docx是一个用于创建、修改和读取Microsoft Word文档的Python库。它可以通过Python脚本来操作Word文档,包括添加、删除、修改文本、表格、图片、样式等。
以下是一些常用的Python-docx方法:
- 创建文档
from docx import Document
doc = Document()2. 添加段落
doc.add_paragraph('Hello, World!')3.添加标题
doc.add_heading('Title', level=0)4.添加表格
table = doc.add_table(rows=3, cols=3)
for i in range(3):
for j in range(3):
table.cell(i, j).text = 'cell %d-%d' % (i+1, j+1)5.插入图片
doc.add_picture('picture.png')6. 修改样式
style = doc.styles['Normal']
font = style.font
font.name = 'Arial'
font.size = Pt(12)doc.paragraphs 是一个列表,其中每个元素代表文档中的一个段落,按照它们在文档中出现的顺序排序。每个段落可以包含一个或多个 run,每个 run 代表段落中的一小部分文本,这些文本具有相同的属性。例如,相同的字体、字号、颜色等。通过访问每个段落的 runs 属性,您可以访问每个段落的所有 run。这些属性可以用来读取或修改文档中的文本内容和格式。
postfix = os.path.splitext(file)[-1][1:]
这行代码的作用是获取文件名的后缀名。首先,os.path.splitext(file)可以将文件名分割成文件名和扩展名两部分,返回一个元组。然后,我们使用[-1]选取元组中的最后一个元素,也就是扩展名部分。最后,使用[1:]选取扩展名字符串中的第一个字符到最后一个字符(不包括第一个字符),也就是去掉了扩展名前面的"."。因此,postfix变量即为文件的后缀名。
MRWord\utils\youdao.py
BeautifulSoup4
BeautifulSoup4 是一个Python库,用于从HTML和XML文件中提取数据。它通过提供了一个优雅的接口,使得解析和搜索文档树变得简单。要安装BeautifulSoup4,通常可以使用pip,Python的包管理器。
BeautifulSoup4(简称BS4)是一个用于Python的HTML和XML解析库,它能够以简洁的方式从HTML或XML文件中提取数据。BS4支持多种解析器,包括Python标准库中的html.parser,以及更强大的第三方解析器如lxml。使用BS4,你可以方便地浏览、搜索和修改文档树,而无需编写复杂的正则表达式。
在爬虫过程中,解析HTML页面是一个关键步骤,而BS4正是一款功能强大的解析器,能够轻松解析HTML和XML文档。通过BS4,你可以轻松地选择HTML文档中的特定元素,提取其文本内容、属性等。
以下是使用BeautifulSoup4的基本步骤:
-
安装BeautifulSoup4:你可以使用pip命令来安装BeautifulSoup4库。同时,为了获得更好的解析性能,建议同时安装lxml模块。
pip install beautifulsoup4
pip install lxml2. 解析HTML文档:使用BeautifulSoup4解析HTML文档非常简单,只需要将HTML文档传递给BeautifulSoup类即可。你可以选择使用不同的解析器来解析文档。
from bs4 import BeautifulSoup
html_doc = """你的HTML文档内容"""
soup = BeautifulSoup(html_doc, 'lxml') # 使用lxml解析器3. 搜索文档树:你可以使用BeautifulSoup4提供的方法来搜索文档树中的特定元素。最常用的方法是find()和find_all(),它们可以根据标签名、属性等条件来查找元素。
# 查找所有的段落标签
paragraphs = soup.find_all('p')
# 查找具有特定属性的元素
links = soup.find_all('a', {'class': 'link-class'})4. 提取信息:一旦你找到了需要的元素,你可以使用BeautifulSoup4提供的方法来提取其文本内容、属性等信息。
# 提取第一个段落标签的文本内容
first_paragraph = paragraphs[0].text
# 提取链接的href属性
for link in links:
href = link.get('href')
print(href)总之,BeautifulSoup4是一个功能强大的HTML和XML解析库,它可以帮助你轻松地解析网页内容并提取所需信息。如果你正在使用Python进行网络爬虫或网页数据分析等工作,那么BeautifulSoup4将是一个非常有用的工具。
MRWord\utils\common.py
def turn_to_unicode(string):
def turn_to_unicode(string):
res = ''
for v in string:
res = res + hex(ord(v)).upper().replace('0X', '\\u')
print(string, '的Unicode编码为', res)
return resord()
ord() 是 Python 中的一个内置函数,它用于返回单个字符(Unicode 字符)的 Unicode 码点(也称为 Unicode 编号或 Unicode 编码)。这个编号是一个介于 0 和 1,114,111(即 0x10FFFF)之间的整数,对应于 Unicode 标准中定义的字符。
ord() 函数只接受一个参数,即单个字符(或长度为一个的字符串)。如果你传入一个包含多个字符的字符串,ord() 会引发一个 TypeError。
下面是一些使用 ord() 函数的例子:
# 获取字符 'A' 的 Unicode 码点
print(ord('A')) # 输出: 65
# 获取字符 '中' 的 Unicode 码点(这是一个中文字符)
print(ord('中')) # 输出可能是一个介于 19968(0x4E00)和 40959(0x9FA5)之间的数字
# 尝试获取多个字符的 Unicode 码点将会引发错误
print(ord('AB')) # TypeError: ord() expected a character, but string of length 2 found在上面的例子中,'A' 的 Unicode 码点是 65(对应于 ASCII 编码中的大写字母 A),而 '中' 是一个中文字符,其 Unicode 码点通常是一个较大的数字。
ord() 函数经常与 chr() 函数一起使用,chr() 函数接受一个 Unicode 码点作为参数,并返回对应的字符。例如:
# 使用 chr() 将 Unicode 码点转换回字符
print(chr(65)) # 输出: A
print(chr(ord('中'))) # 输出: 中hex()
hex() 函数是Python内置函数,用于将十进制整数转换为十六进制表示的字符串。其语法非常简单:
hex(x)其中 x 是一个十进制整数。函数将返回一个字符串,该字符串以 "0x" 开头,后跟该整数的十六进制表示形式。例如:
print(hex(255)) # 输出: '0xff'这个例子中,255 的十六进制表示是 ff,因此 hex(255) 返回了字符串 '0xff'。
需要注意的是,当您使用 hex() 函数时,结果字符串会始终包含 "0x" 前缀,它是用来表明该字符串表示的是一个十六进制数。
Unicode字符串
Unicode 字符串前缀通常是 \u,而 \\u(因为反斜杠 \ 在字符串中是一个转义字符,所以需要使用两个反斜杠来表示一个实际的反斜杠)。
另外:
-
在连接字符串时,使用
+运算符是可行的,但在循环中频繁地这样做可能会比较慢。使用列表推导式和join()方法通常会更高效。 -
输出的字符串将没有空格或逗号等分隔符,这可能会使得结果难以阅读。
可借鉴代码
def turn_to_unicode(string):
# 使用列表推导式生成每个字符的Unicode编码,并确保每个编码都是四个十六进制数字
unicode_codes = ['\\u{:04x}'.format(ord(v)) for v in string]
# 使用 ' '.join 将编码连接成一个字符串,中间用空格分隔以提高可读性
res = ''.join(unicode_codes)
print(string, '的Unicode编码为', res)
return res
# 示例用法
unicode_string = turn_to_unicode('Hello, World!')
print(unicode_string)输出将是:
Hello, World! 的Unicode编码为 \u0048\u0065\u006c\u006c\u006f\u002c\u0020\u0057\u006f\u0072\u006c\u0064\u0021 \u0048\u0065\u006c\u006c\u006f\u002c\u0020\u0057\u006f\u0072\u006c\u0064\u0021
请注意,Unicode 编码字符串通常用于编程中(如JSON或XML),并且不是人类可读的。在上面的例子中,我已经包含了打印原始字符串和其Unicode编码,以便您可以比较两者。如果您只是想要一个可读的表示形式,您可能不需要在函数中包含 print 语句,而只是返回 Unicode 编码的字符串。
扩展延伸
在 Python 中,Unicode 编码字符串是默认的字符串类型,从 Python 3 开始,所有的字符串都是 Unicode 字符串(即 str 类型)。这意味着当你创建一个字符串时,Python 会自动将其存储为 Unicode 格式。
Unicode 是一种字符编码标准,它为全球几乎所有的书写系统中的每个字符分配了一个唯一的数字标识符(即 Unicode 码点)。这些标识符的范围从 U+0000 到 U+10FFFF。
在 Python 3 中,你可以直接使用 Unicode 字符(例如中文字符、希腊字母等)在字符串中,而不需要进行任何特殊的编码或解码操作。Python 会自动处理这些字符的编码和存储。
例如:
# 创建一个包含 Unicode 字符的字符串
unicode_string = "Hello, 世界!"
print(unicode_string) # 输出: Hello, 世界!
# 你可以直接访问字符串中的 Unicode 字符
first_char = unicode_string[0] # 'H'
last_char = unicode_string[-1] # '!'(注意这是一个全角感叹号)
# 使用 ord() 函数获取 Unicode 字符的码点
code_point = ord(last_char) # 输出可能是 65373('!' 的 Unicode 码点)
print(hex(code_point)) # 输出可能是 '0xff01'('!' 的十六进制 Unicode 码点)如果你需要将 Unicode 字符串转换为其他编码(如 UTF-8、GBK 等),你可以使用 Python 的 encode() 方法。相反,如果你需要将其他编码的字符串转换为 Unicode 字符串,你可以使用 decode() 方法。但在 Python 3 中,由于所有的字符串都是 Unicode 字符串,你通常只需要在需要将字符串写入文件或发送到网络时才需要关心编码问题。
例如,将 Unicode 字符串编码为 UTF-8 字节串:
encoded_bytes = unicode_string.encode('utf-8')
print(encoded_bytes) # 输出可能是 b'Hello, \xe4\xb8\x96\xe7\x95\x8c!'将 UTF-8 字节串解码为 Unicode 字符串:
decoded_string = encoded_bytes.decode('utf-8')
print(decoded_string) # 输出: Hello, 世界!def instance_new_line(str_text, len_text, is_cn=False):
def instance_new_line(str_text, len_text, is_cn=False):
""" 例句换行 """
import math
if not is_cn:
str_len = len(str_text)
# 判断是否需要换行
lines = math.ceil(str_len/len_text)
for i in range(1, lines):
blank_index = str_text.find(' ', len_text * i, -1)
if not blank_index == -1:
str_text = str_text[:blank_index] + '\n' + str_text[blank_index+1:]
return str_text
else:
str_len = len(str_text)
len_text = int(len_text/2)
lines = math.ceil(str_len / len_text)
for i in range(1, lines):
str_text = str_text[:len_text] + '\n' + str_text[len_text:]
return str_text
说明阶段:
这段代码定义了一个函数instance_new_line,用于实现例句的换行功能。函数接受三个参数:str_text代表输入的文本字符串,len_text代表每行文本的长度限制,is_cn是一个布尔值,用于标识文本是否为中文。函数会根据is_cn的值来决定如何换行。如果is_cn为False,则函数会尝试在英文或其他非中文字符的空白处换行;如果为True,则简单地按照指定的长度将中文文本截断并换行。
细节分析阶段:
ceil 美/siːl/ v.给……抹灰泥或装镶板;(用熟石膏、木板等)装天花板
instance 美/ˈɪnstəns/ n.例子,实例 v.举……为例
blank 美/blæŋk/ n.空白处,空格;
- 函数首先导入
math模块,以便后续使用其ceil函数来计算换行数量。 - 如果
is_cn为False,表示文本不是中文:- 计算
str_text的长度。 - 使用
math.ceil函数计算需要换行的行数。 - 循环遍历每一行,尝试在空白处(即空字符串的位置)换行。这里存在一个问题:
str.find函数的第三个参数应该是查找的起始位置,而不是结束位置,因此-1是不合适的。此外,由于英文文本中通常不会在固定字符数处断开,所以应该查找最接近指定长度的空白字符(如空格、标点符号等)来进行换行。 - 如果找到了空白索引,就在该位置插入换行符
\n。 - 最后返回处理后的字符串。
- 计算
- 如果
is_cn为True,表示文本是中文:- 由于中文字符通常占用更多的字节,因此将
len_text除以2来调整每行的中文字符数。 - 计算需要换行的行数。
- 循环遍历每一行,并在指定的长度处直接插入换行符
\n,这里简单地按照字符数截断,可能会导致一个词语被分开,这在中文排版中是不合适的。 - 返回处理后的字符串。
- 由于中文字符通常占用更多的字节,因此将
存在的问题包括:
- 英文文本换行时,查找空白字符的逻辑可能不正确,因为
-1作为find函数的第三个参数是不合适的,而且直接截断可能会导致单词被拆分。 - 中文文本换行时,简单地按照字符数截断可能会导致一个完整的词语或短语被分开,影响可读性。
总结阶段:
总的来说,instance_new_line函数的目的是根据指定的行长度对文本进行换行处理,但实现上存在一些问题,特别是在处理英文和中文文本时。对于英文文本,应该更精细地处理换行位置,避免拆分单词;对于中文文本,应该考虑词语的完整性,避免将一个词语截断。
一个可能的改进方案是:
- 对于英文文本,可以使用正则表达式来查找接近指定长度的单词边界(如空格、标点符号等)进行换行。
- 对于中文文本,可以使用分词工具来确保换行不会拆分一个完整的词语。
math.ceil
math.ceil 是 Python 标准库 math 中的一个函数,用于向上取整。具体来说,math.ceil(x) 会返回大于或等于 x 的最小整数。如果 x 本身就是一个整数,那么 math.ceil(x) 就返回 x 本身。
例如:
import math
print(math.ceil(4.1)) # 输出 5
print(math.ceil(4)) # 输出 4
print(math.ceil(-1.2)) # 输出 -1在上面的例子中,math.ceil(4.1) 返回 5,因为 5 是大于 4.1 的最小整数。对于负数,math.ceil 会取比该数大的最小整数,所以 math.ceil(-1.2) 返回 -1。
在你提供的 instance_new_line 函数中,math.ceil 被用来计算根据指定的行长度需要换行的行数。这是通过将文本的总长度除以每行的长度限制,并对结果向上取整来实现的。这样做是为了确保即使最后一行文本不满一行长度,也会计算在内。
str.find()
str.find() 是 Python 字符串对象的一个方法,用于查找子字符串在主字符串中首次出现的索引位置。如果找到子字符串,它返回子字符串的起始索引;如果没有找到,它返回 -1。
方法的基本语法是:
str.find(sub[, start[, end]])sub是要查找的子字符串。start和end是可选参数,用于指定在字符串中的查找范围。
示例:
text = "Hello, world!"
index = text.find("world")
print(index) # 输出 7,因为 "world" 在 "Hello, world!" 中从索引 7 开始
index_not_found = text.find("Earth")
print(index_not_found) # 输出 -1,因为 "Earth" 没有在文本中找到在 instance_new_line 函数代码中,str_text.find('', len_text * i, -1) 这行代码有几个问题:
- 第一个参数是空字符串
'',这意味着它实际上是在查找一个空位置,这是没有意义的,因为空字符串在字符串中的任何位置都可以被视为存在。 - 第三个参数
-1通常用于指定查找的结束位置,但在str.find()方法中,如果提供的是负数,它会被解释为从字符串末尾开始的偏移量。然而,在这里使用-1并不合适,因为它会将查找范围限制在字符串的最后一个字符,通常这不是我们期望的行为。
如果您想在某个特定长度后查找空格或其他适当的换行点,您应该使用有意义的子字符串(如空格 ' ')作为 find 方法的第一个参数,并适当调整起始查找位置。同时,您还需要考虑如何处理找不到合适换行点的情况。
到行尾见缝插\n
def sub_str_len(str_text, len_text):
def sub_str_len(str_text, len_text):
""" 控制字符串长度 """
ret_text = ''
new_line_list = str_text.split('\n')
for line in new_line_list:
text_list = line.split(';')
if len(text_list) > len_text:
for i in range(len_text):
ret_text += text_list[i] + ';'
else:
ret_text += '\n'
return ret_text说明阶段:
这段代码定义了一个名为sub_str_len的函数,它接受两个参数:str_text(一个字符串)和len_text(一个数字,可能意图表示每行的最大项目数)。函数的目的是控制字符串的长度,但具体实现逻辑上似乎有些问题。该函数试图将输入文本str_text按照换行符拆分成多行,并进一步将每行按照分号;拆分。如果拆分后的项目数大于len_text,则将这些项目用;连接起来添加到ret_text中;如果项目数不大于len_text,则在ret_text后添加一个换行符。
细节分析阶段:
- 函数首先初始化一个空字符串
ret_text,用于存储处理后的文本。 - 使用
split('\n')将输入字符串str_text拆分成多行,每行存储到列表new_line_list中。 - 遍历
new_line_list中的每一行,使用split(';')将每行按分号拆分,得到一个项目列表text_list。 - 判断
text_list的长度是否大于len_text:- 如果大于,则遍历
text_list中的前len_text个项目,将它们用;连接起来,并追加到ret_text中。 - 如果不大于,则在
ret_text后追加一个换行符\n。
- 如果大于,则遍历
- 函数返回处理后的字符串
ret_text。
然而,这段代码存在以下问题:
- 如果
text_list的长度小于或等于len_text,函数只会在ret_text后添加一个换行符,而不会添加当前行的任何内容。这可能导致丢失原始文本中的数据。 - 函数没有处理超过
len_text长度的行中剩余的项目,这些项目将被忽略。 - 变量名
len_text可能会引起误解,因为它实际上表示的是每行要处理的项目数量,而不是文本长度。
总结阶段:
综上所述,sub_str_len函数的目的是控制字符串中每行分号分隔的项目的数量,但实现上存在逻辑问题,可能会导致数据丢失或不完整的处理。
为了修正这些问题,我们可以重新设计函数逻辑,确保所有项目都被处理,并且每行的项目数量不超过len_text。下面是一个可能的改进实现:
def sub_str_len(str_text, max_items_per_line):
""" 控制每行字符串中由分号分隔的项目的最大数量 """
ret_text = ''
lines = str_text.split('\n')
for line in lines:
items = line.split(';')
for i in range(0, len(items), max_items_per_line):
chunk = items[i:i+max_items_per_line] # 取max_items_per_line个项目的块
ret_text += ':'.join(chunk) + '\n' # 使用':'连接并追加换行符
return ret_text.rstrip('\n') # 去除末尾多余的换行符在这个改进版本中,我们确保了所有项目都被处理,每行的项目数量受到max_items_per_line的限制,并且避免了数据丢失的问题。同时,我也更改了参数名以更清晰地反映其意图。
.split()
是 Python 字符串的一个方法,用于将字符串按照指定的分隔符拆分成多个部分,并返回一个包含这些部分的列表。如果没有指定分隔符,那么默认会使用所有的空白字符,比如空格、换行(\n)、制表符(\t)等。
方法的基本语法是:
str.split([sep[, maxsplit]])sep是分隔符,默认为所有的空白字符。maxsplit是可选参数,如果提供,则分割操作将最多进行maxsplit次。
示例:
# 使用默认分隔符(空白字符)分割字符串
text = "Hello World from Python"
words = text.split()
print(words) # 输出 ['Hello', 'World', 'from', 'Python']
# 使用指定分隔符分割字符串
data = "apple,banana,cherry,dates"
fruits = data.split(',')
print(fruits) # 输出 ['apple', 'banana', 'cherry', 'dates']
# 使用 maxsplit 参数
limited_split = data.split(',', maxsplit=2)
print(limited_split) # 输出 ['apple', 'banana', 'cherry,dates']在第一个例子中,split() 方法使用默认的空白字符作为分隔符,将字符串拆分成单词列表。在第二个例子中,我们使用逗号作为分隔符来拆分一个包含水果名称的字符串。在第三个例子中,我们限制了 split() 方法的分割次数,所以它只在前两个逗号处进行了分割。
.split() 方法在处理文本数据、日志文件、CSV 文件等格式时非常有用,因为它可以快速地将数据分解成更小的、更容易处理的部分。
















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











