







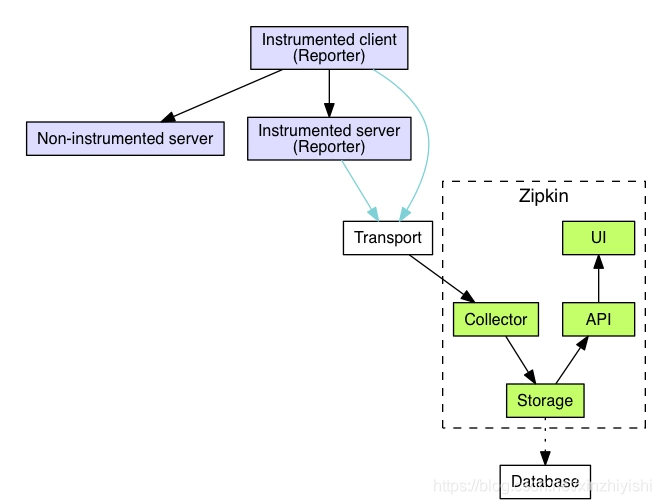
Zipkin是什么
Zipkin分布式跟踪系统(Distributed Tracing System);它可以帮助收集时间数据,解决在microservice架构下的延迟问题;它管理这些数据的收集和查找;Zipkin的设计是基于谷歌的Google Dapper论文。
每个应用程序向Zipkin报告定时数据,Zipkin UI呈现了一个依赖图表来展示多少跟踪请求经过了每个应用程序;如果想解决延迟问题,可以过滤或者排序所有的跟踪请求,并且可以查看每个跟踪请求占总跟踪时间的百分比。
为什么使用Zipkin
随着业务越来越复杂,系统也随之进行各种拆分,特别是随着微服务架构和容器技术的兴起,看似简单的一个应用,后台可能有几十个甚至几百个服务在支撑;一个前端的请求可能需要多次的服务调用最后才能完成;当请求变慢或者不可用时,我们无法得知是哪个后台服务引起的,这时就需要解决如何快速定位服务故障点,Zipkin分布式跟踪系统就能很好的解决这样的问题。
Zipkin的Span模型几乎完全仿造了Dapper中Span模型的设计,我们知道,Span用来描述一次RPC调用,所以一个RPC调用只应该关联一个spanId(不算父spanId),Zipkin中的Span主要包含三个数据部分:
-
基础数据:用于跟踪树中节点的关联和界面展示,包括traceId、spanId、parentId、name、timestamp和duration,其中parentId为null的Span将成为跟踪树的根节点来展示,当然它也是调用链的起点,为了节省一次spanId的创建开销,让顶级Span变得更明显,顶级Span中spanId将会和traceId相同。timestamp用于记录调用的起始时间,而duration表示此次调用的总耗时,所以timestamp+duration将表示成调用的结束时间,而duration在跟踪树中将表示成该Span的时间条的长度。需要注意的是,这里的name用于在跟踪树节点的时间条上展示。
-
Annotation数据:用来记录关键事件,只有四种,cs(Client Send)、sr(Server Receive)、ss(Server Send)、cr(Client Receive),所以在Span模型中,Annotation是一个列表,长度最多为4。每种关键事件包含value、timestamp和endpoint,value就是cs、sr、ss和cr中的一种,timestamp表示发生的时间,endpoint用于记录发生的机器(ip)和服务名称(serviceName)。可以很自然的想到,cs和cr、sr和ss的机器名称是相同的,为了简单起见,cs和cr的服务名称可以一样,sr和ss的服务名称可以一样。Annotation数据主要用于用户点击一个Span节点时展示具体的Span信息。
-
BinaryAnnotation数据:我们并不满足在跟踪树上只展示调用链的时间信息,如果需要绑定一些业务数据(日志)的话,可以将数据写入BinaryAnnotation中,它的结构和Annotation数据一模一样,在Span中也是一个列表,这里就不再阐述,但BinaryAnnotation中不宜放太多数据,不然将导致性能和体验的下降。
这是Span的最终形态,也就是说这是Zipkin在收集完数据并展现给用户锁看到的最终形态。Span的产生是“不完整”的,Zipkin服务端需要将搜集的有同一个traceId和spanId的Span组装成最终完整的Span,也就是上面说到的Span。
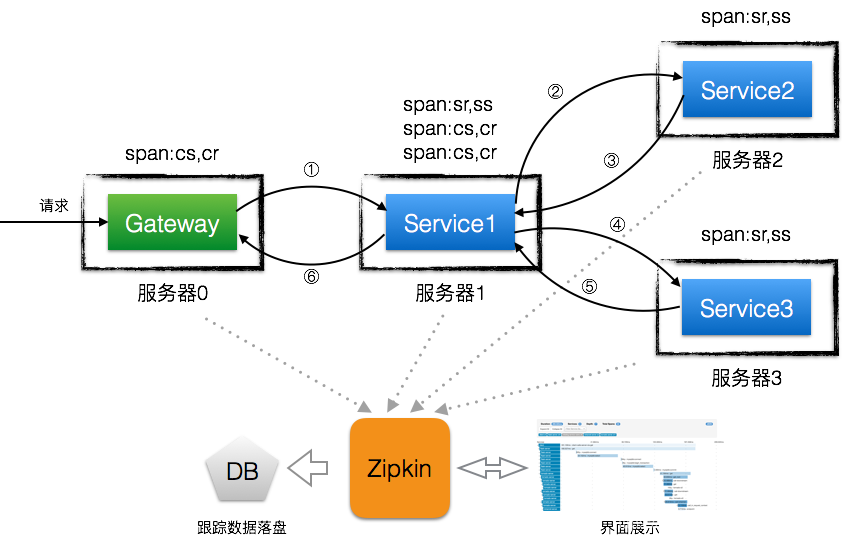
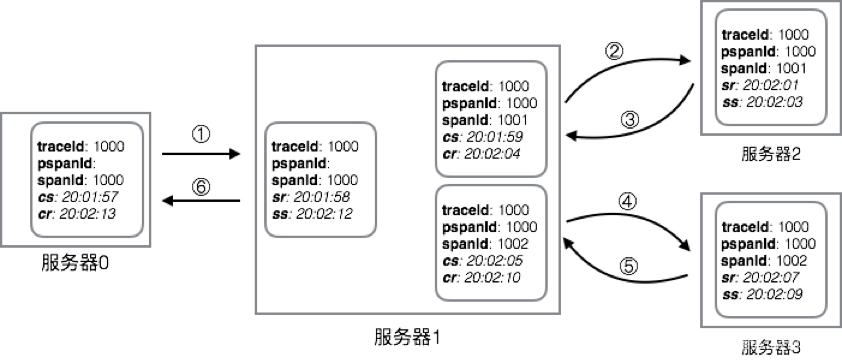
一共产生了6条span日志,它们将在Zipkin服务端组装成3个Spa














 1130
1130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









