






所用所有数据表如下

数据库多表联查
数据查询结果
将i表与p表关联查询(以最早的数据为准),且去除两表重复部分,并在结果中查询符合条件的数据

SELECT * FROM
(
SELECT i.openid openid,i.invitees guwen,i.zid zid,u.phone FROM i
LEFT JOIN u ON i.openid=u.openid
GROUP BY i.openid
UNION
(
SELECT p.openid openid,'' as guwen,p.zid zid,u.phone FROM p
LEFT JOIN u ON p.openid=u.openid
GROUP BY p.openid
)
)
f
WHERE
(f.zid in( SELECT z.zid FROM z WHERE apart = '少儿部' ) )
AND f.phone <> ''
GROUP BY f.openid
tp中多表联查
 field至少为两个参数,否则报错
field至少为两个参数,否则报错
public function cc()
{
$apart='少儿部';
$where['f.phone'] = ['neq', ''];
$sql1 = db('P')
->join('U', 'P.openid=U.openid', 'left')
->field("P.openid openid,'' as guwen,P.zid zid,U.phone")
->group('U.openid')
->buildSql();
$sqlres = db('I')
->join('U', 'I.openid=U.openid', 'left')
->field("I.openid openid,I.invitees guwen,I.zid zid,U.phone")
->group('I.openid')
->union([$sql1])
->buildSql();
$sqlzids=db('Z')->field('Z.zid')->where(['apart'=>$apart])->buildSql();
$list = db()->table([$sqlres => 'f'])
->field('f.*')
->where('f.zid in' . $sqlzids)
->where($where)
->group('f.openid')
->select();
var_dump($list);
}
数据库中查询某字段的连接结果
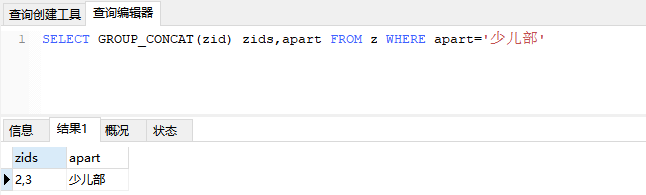
SELECT GROUP_CONCAT(zid) zids,apart FROM z WHERE apart='少儿部'
数据库group使用–先分组,再计算
分组,配合计算使用
注意:
①默认获取的是选择查询索引(where或者group by)的第一条符合分组的记录填充
②如果子查询的数据超过1G【1G一般是mysql中默认的,子查询配置的表大小,数量差不多是500万条以上数据】,则后面的查询结构就丢失,造成随机性数据丢失的问题
数据表如下
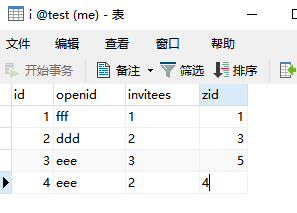
以最早的数据为准

SELECT * FROM i GROUP BY i.openid
以最新的数据为准min
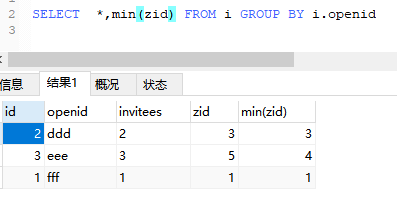
SELECT *,min(zid) FROM i GROUP BY i.openid
数据库distinct使用–先去重,再计算
distinct 只是去重,不太适合条件和计算类查找
















 1371
1371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









