






什么是kafka
一款开源的分布式数据流处理平台,可以实时发布、订阅、存储和处理数据流。
作用与特点
Kafka 主要起到削峰、系统解耦的作用。
主要特点有:
- 高吞吐、低延时:这是 Kafka 显著的特点,Kafka 能够达到百万级的消息吞吐量,延迟可达毫秒级;
- 持久化存储:Kafka的消息最终持久化保存在磁盘之上,提供了顺序读写以保证性能,并且通过 Kafka的副本机制提高了数据可靠性。
- 分布式可扩展:Kafka 的数据是分布式存储在不同 broker 节点的,以 topic 组织数据并且按 partition 进行分布式存储,整体的扩展性都非常好。
- 高容错性:集群中任意一个 broker 节点宕机,Kafka 仍能对外提供服务。
术语解释
- Broker:一个Kafka服务端节点。
- 集群:由多个Broker组成的集合。
- Producer:生产者,推送消息。
- Consumer:消费者,拉取消息进行消费。
- Consumer Group:消费组由若干个消费者组成,一条消息只能被消费组中一个Consumer消费。
- Topic:主题,服务端消息的逻辑存储单元。一个 topic 通常包含若干个 Partition 分区。
- Partition:topic的分区,分布式存储在各个 broker 中, 实现发布与订阅的负载均衡。若干个分区可以被若干个 Consumer同时消费,达到消费者高吞吐量。一个分区拥有多个副本(Replica)。
- Message:消息,或称日志消息,是 Kafka 服务端实际存储的数据,每一条消息都由一个 key、一个 value 以及消息时间戳 timestamp 组成。
- Rebalance:是让一个消费组的所有消费者就如何消费订阅 topic 的所有分区达成共识的过程。
- 位点: 消息到达分区时被指定的序列号。
- 最小位点: 分区的最小位点,即当前分区的首条消息的位点。
- 最大位点: 分区的最大位点,即当前分区的最新消息的位点。
- 消费位点: 分区被当前Consumer消费了的消息的最大位点。
- 堆积量Lag: 当前分区下的消息堆积总量,即最大位点减去消费位点的值。
注意点
-
topic对应的多个消费组互不干扰,类似RabbitMQ的广播模式。
-
分区和消费组
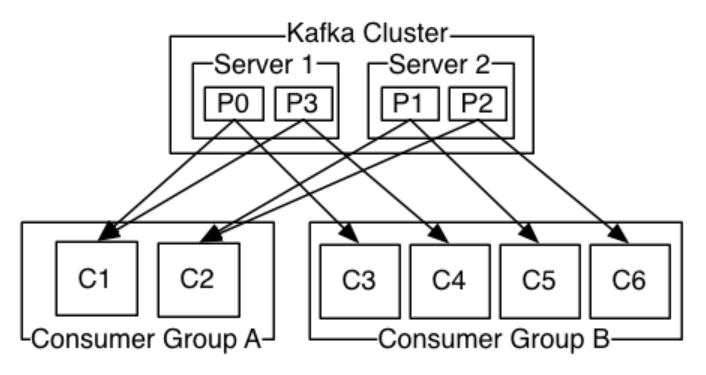
kafka cluster中有两台broker服务器,每一台都有两个分区,这四个分区都是同一个topic下的。下左的消费者组A,组内有两个消费者,每个消费者负责两个分区的消费,而右边的消费者组B有四个消费者,每个负责消费一个分区。
为什么每个分区只从属于组中的一个消费者?
Kafka它在设计的时候就是要保证分区下消息的顺序。如果组中多个消费者可以消费同一个分区,那么多个消费者各自拉取未消费的消息会产生重复消费。例如消费者C1消费offset:100的消息,但还未完成提交。消费者C2进行拉消息则会再次拉取到offset:100的消息,产生重复消费。劣势是无法让同一个 consumer group 里的 consumer 均匀消费数据;优势是每个 consumer 不用都跟大量的 broker 通信,减少通信开销,同时也降低了分配难度,实现也更简单。另外,因为同一个 partition 里的数据是有序的,这种设计可以保证每个 partition 里的数据也是有序被消费。同一时刻,一条消息只能被组中的一个消费者实例消费
- 分区数>消费组中的消费者实例数
存在一个消费者会负责多个分区。 - 分区数=消费组中的消费者实例数
一个消费者负责一个分区。 - 分区数=消费组中的消费者实例数
部分消费者是多余的,处于空闲状态。
- 分区数>消费组中的消费者实例数
-
重复消费
消费端已经消费了数据,但是offset没来得及提交。
常见原因在于: reblance。
常见处理方式- 增加max.poll.interval.ms、session.timeout.ms
- 减少max.poll.records
- 提高业务逻辑处理速度
-
提高消费速度
提高消费速度有以下两个办法:- 增加Consumer实例个数。
可以在进程内直接增加(需要保证每个实例对应一个线程,否则没有太大意义),也可以部署多个消费实例进程;需要注意的是,实例个数超过分区数量后就不再能提高速度,将会有消费实例不工作。 - 增加消费线程。
增加Consumer实例本质上也是增加线程的方式来提升速度,因此更加重要的性能提升方式是增加消费线程,最基本的步骤如下:- 定义一个线程池。
- Poll数据。
- 把数据提交到线程池进行并发处理。
- 等并发结果返回成功后,再次poll数据执行。
- 增加Consumer实例个数。
-
消费失败
- 失败后一直尝试再次执行消费逻辑。这种方式有可能造成消费线程阻塞在当前消息,无法向前推进,造成消息堆积。
- 打印失败的消息或者存储到某个服务(例如创建一个Topic专门用来放失败的消息),然后定时检查失败消息的情况,分析失败原因,根据情况处理。【推荐】
-
消息推拉模式
拉模式,对于推拉模式具体可以参考另外一篇博文消息队列之推拉模式














 4906
4906











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









