






所谓I/O就是计算机内存与外部设备之间拷贝数据的过程。由于CPU访问内存的速度远远高于外部设备,因此CPU是先把外部设备的数据读到内存里,然后再进行处理。对于一个网络I/O通信过程,比如网络数据读取,会涉及两个对象,一个是调用这个I/O操作的用户线程,另外一个就是操作系统内核。一个进程的地址空间分为用户空间和内核空间,用户线程不能直接访问内核空间。
IO模型分类
常见的IO模型主要有下面4种:同步阻塞I/O、同步非阻塞I/O、I/O多路复用和异步I/O。
首先理解一下同步异步,非阻塞/阻塞。
同步异步
同步异步的关键是IO设备状态需要自己轮询,还是内核主动通知。
同步:用户线程轮询去发起IO请求。
异步:当内核IO操作就绪后,内核主动把数据写入用户程序指定的Buffer。
阻塞非阻塞
阻塞非阻塞描述的是用户线程调用内核IO操作的方式。(仅数据准备阶段)。
阻塞:IO操作需要彻底完成后才返回到用户空间。
非阻塞:IO操作被调用后立即返回给用户一个状态值,不需要等到IO操作彻底完成。
当用户线程发起I/O操作后会经历两个阶段:
-
数据准备阶段:内核等待数据就绪,将数据从网卡拷贝到内核空间。
-
数据拷贝阶段:内核将数据从内核空间拷贝到用户空间。
1. 阻塞IO(Blocking IO)
Linux中默认的Socket IO都是阻塞的,在阻塞IO模式下,读数据的流程如下:
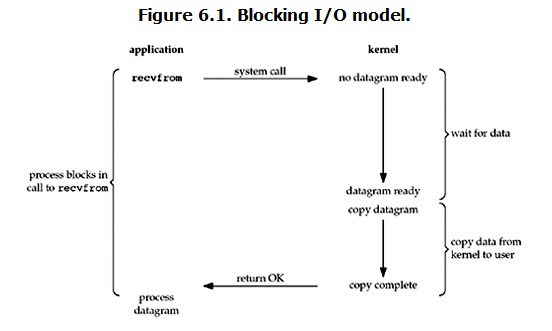
从上图看Blocking IO模式在数据准备和数据拷贝两个阶段,用户程序都是堵塞的。
一个简单的改进方案是在服务器端使用多线程(或多进程)。多线程(或多进程)的目的是让每个连接都拥有独立的线程(或进程),这样任何一个连接的阻塞都不会影响其他的连接。但也存在问题,如果要同时响应成百上千路的连接请求,则无论多线程还是多进程都会严重占据系统资源, 例如线程占用一定的内存, 线程调度带来额外的CPU开销等,降低系统对外界响应的效率。
2. 非阻塞IO(Non-Blocking IO)
非阻塞IO模式下,读数据的流程如下:
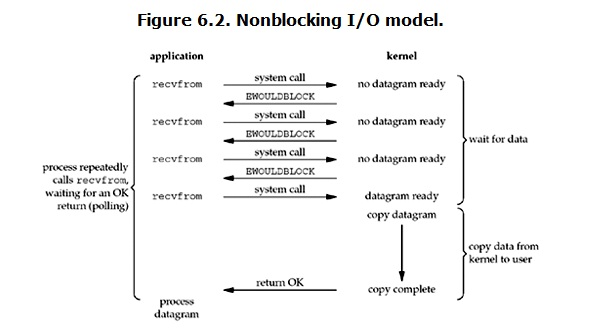
在Non-Blocking模式下,调用recvfrom时,如果内核还没有准备好数据,会直接返回EWOULDBLOCK错误。用户程序可以继续发起调用,直到内核数据已经准备好,就会把数据拷贝到用户内存空间,并返回成功。所以在Non-Blocking模式,用户程序需要通过轮询来查看数据是否准备好,而且数据拷贝阶段还是堵塞的。
由于用户程序需要轮询,轮询会大量占用CPU时间,所以非阻塞模式一般不被推荐使用,而是采用内核自带轮询的IO多路复用技术。
3. IO多路复用(IO Multiplexing) 重点!!!
多路是指网络连接, 复用是指用的同一个线程。
IO多路复用,又叫事件驱动IO(Event-Driver IO),底层使用了内核提供的select/poll/epoll等系统调用。IO多路复用模式下,读数据的流程如下:

当调用了select后,用户程序会堵塞,同时内核监控此select负责的所有Socket,当任意一个进入读就绪状态时,select函数就会返回。用户程序再逐个调用读就绪的Socket的recvfrom函数,把数据从内核拷贝到用户内存。
IO多路复用模型和阻塞IO的模型其实并没有太大的不同,事实上还更差一些。因为这里需要使用两个系统调用(select和recvfrom),而阻塞IO只调用了一个系统调用(recvfrom)。但是,用select的优势在于它可以同时处理多个连接。所以,如果处理的连接数不是很高的话,可能延迟还更大;select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
在多路复用IO模型中,对于每一个socket,一般都设置成为非阻塞的,但整个用户的进程其实是一直被阻塞的。只不过进程是被select这个函数阻塞,而不是被socket IO阻塞。因此使用select()的效果与非阻塞IO类似。
此模式虽然用户程序不在需要轮询了,但是内核还是需要去轮询Socket,消耗大量CPU。
4. 异步IO(Asynchronous I/O)
用户线程发起read调用的同时注册一个回调函数,read立即返回,等内核将数据准备好后,再调用指定的回调函数完成处理。在这个过程中,用户线程一直没有阻塞。异步IO模式下,读数据的流程如下:

IO模型总结

堵塞IO、非堵塞IO、IO多路复用、信号驱动IO都是同步IO,在拷贝数据阶段还是堵塞的;
异步IO发完请求后,用户程序就返回了,数据准备和数据拷贝两个阶段都由内核来完成。















 1219
1219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









