






1 Hive函数
① 条件函数
条件:计算结果为布尔值,或者可以转换为布尔值的数据都可以作为条件使用(比较运算、逻辑运算)
一般可以用where筛选的条件都可以作为条件判断的条件使用
1.if 语法:if(条件语句,条件成立返回的值,条件不成立返回的值
select * from hive_day03.students;
select s_id,s_name,`if`(gender='男','男生','女生') from hive_day03.students;
-- 如果对立情况判断,优先使用if条件函数,若是多种情况判断可以使用IF嵌套,但不建议使用
2.此时可以使用case when
语法一:
case
when 条件1 then 条件1成立时返回的数据
when 条件2 then 条件2成立时返回的数据
when 条件3 then 条件3成立时返回的数据
…
else 所有条件均不成立时返回的数据
end
语法二:
case 字段
when 值1 then 字段值为值1时返回的数据
when 值2 then 字段值为值2时返回的数据
when 值3 then 字段值为值3时返回的数据
…
else 字段的值不等于任何判断值时返回的数据
end
-- 需要使用汉字代替pay_tupe中的数字支付方式 0:未知;1:支付宝;2:微信;3:现金;4:其他
-- 方法一
select orderid,totalmoney,username,useraddress,
case when paytype=0 then '未知'
when paytype=1 then '支付宝'
when paytype=2 then '微信'
when paytype=3 then '现金'
when paytype=4 then '其他'
else '数据异常' end
as paytype,paytime
from hive_day03.orders;
-- 方法二
select orderid,totalmoney,username,useraddress,
case paytype
when 0 then '未知'
when 1 then '支付宝'
when 2 then '微信'
when 3 then '现金'
when 4 then '其他'
else '数据异常' end
as paytype,paytime
from hive_day03.orders;
-- case when的两种方式如何选择
-- 如果判断条件比较负责则方法一;如果仅判断某个字段的值或计算计过则方法二
-- 3.is null和 is not null 如果任何一个数据和null判断是否相等,不等,大于小于等于什么?null
select null is null;
select null>4;
-- 4.nvl (获取字段,默认值) 获取一个字段的值,如果该值为null,则直接使用默认值,可用于数据清洗中处理缺失值
select nvl('666','牛刀小试');
select nvl(null,'牛刀小试');
-- 5.coalesce(值1,值2,值3......) 获取多个数据中第一个不为空的值,若都为null则返回null
select coalesce(null,null,11,18,20);
select coalesce(null,null,null,18,20);
select coalesce(null,null,null,null,null);
② 数据类型转换函数
语法:cast(数据 as 数据类型)
多用于数据类型与字符串类型间的相互转换
时间类型转换在hive不常用,hive中时间字符串和时间类型可以混合使用
select cast('12' as int);
select cast('12.3' as int);
-- 如果数据类型抓换不成功会返回null
select cast('十一' as date); --不会报错,返回null
-- 转换为时间类型数据
-- 如何转换时间字符串中的时间必须格式、数据完整度满足标准才能转换成功
select cast('2021-12-13' as date);
select cast('2021-12-13 12:31:59' as timestamp);
③ 加密函数
-- 1.hash函数会将不同类型的数据计算出一个整数值
-- 相同的数据计算出的哈希值永远相同
-- 整数的哈希值就是数字本身
select hash('hive');
-- 2.current_user 查询当前与hivesercer2连接的用户是谁
select current_user();
-- 3.current_database 查看当前使用的数据库
select current_database();
-- 4.version查看当前hive的版本
select version();
-- 5.md5 MD5加密(了解,已被破解)
select md5('你可长点心吧') as md5;
-- 6.哈希加密
-- sha1 sha2 都是哈希加密,哈希加密是不可逆的加密方式,不可通过密文数据反推铭文数据是什么
-- 使用哈希加密方式一般都是用明文再加密一遍后对比加密都的结果是否相同,如果相同则数据正确
select sha1('你可长点心吧!');
select sha2('你可长点心吧!',256);
-- 7.CRC32,这种方式不能保证数据安全,一般用来校验数据的完整性
select crc32('你可长点心吧');

④ 集合函数
-- 1.创建一个array类型函数
-- 创建array类型数据类型时,需要保证数据类型一致,不一致会自动变为数量范围最大的类型
select `array`(1,2,3,4,5); --[1,2,3,4,5]
select `array`(1,2,3,4,'5'); --["1","2","3","4","5"]
select `array`(1,2,3,4,5.2); --[1,2,3,4,5]
-- 2.怎么创建一个map类型的数据
-- org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException:Arguments must be in key/value pairs
-- 在map类型中,键和值需同时出现
select `map`('小明','小工','小华');--报错
-- map 类型中每一个元素的键值类型要同意i,如果不统一会自动转换
select `map`('name','小明','gender','男','age',18); --{"name":"小明","gender":"男","age":"18"}
-- 3.size获取复杂数据类型中的元素个数
select size(`array`(1,2,3,4,5)); --结果为5 一个数值就算一个元素
select size(`map`('name','小明','gender','男','age',18)); --3
-- 4. map_key() 获取map中所有的key
select map_keys(`map`('name','小明','gender','男','age',18)); --["name","gender","age"]
-- 5.map_value() 获取map中所有的values
select map_values(`map`('name','小明','gender','男','age',18)); --["小明","男","18"]
-- 6.array_contains 判断array中是否包含该元素
select array_contains(`array`(1,2,3,4,5),5); --true
select array_contains(`array`(1,2,3,4,5),5); --true
select array_contains(`array`(1,2,3,4,5),7); --false
select array_contains(map_values(`map`('name','小明','gender','男','age',18)),'男'); --true
-- 7.sort_array 这种方式只能升序排序,不能降序
select sort_array(`array`(3,5,1,4,6,2,8)); --[1,2,3,4,5,6,8]
如果需要需转化为struct类型使用sort_array_by()函数
sort_array_by是对struct数组类型进行排序的,排序时可以指定列明和升降序关系
-- 查看函数使用方法
desc function extended sort_array_by;
-- 测试使用方法中提供的案例
SELECT sort_array_by(array(struct('g',100),struct('b',200)),'col1','DESC') LIMIT 1; --[{"col1":"g","col2":100},{"col1":"b","col2":200}]
select sort_array_by(`array`(3,5,1,4,6,2,8),'desc'); --异常
提示错误:org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException:Element[s] of first argument array in function SORT_ARRAY_BY must be struct, but array<int> was found.
函数SORT_ARRAY_BY中第一个参数数组的元素[s]必须是struct,但提供是数据类型为数组。
2 CET表达式
CET表达式就是创建了一个临时的结果集提供使用,一定程度上与子查询类似
语法:WITH 表名 AS 查询集 就可以在后续的查语句中使用该表
with t1 as ( select * from hive_day03.course where s_name='周杰轮')
select * from t1;
-- CET表达式只能在当前SQL语句中使用,除了这个语句则失效
select c_name from t1; --报错:Table not found 't1'
with t1 as ( select * from hive_day03.course where s_name='周杰轮'),
t2 as ( select * from hive_day03.course where s_name='林均街')
select * from t1 full join t2 on t1.id=t2.id;
-- 在创建多个临时表时,后边定义的表可以使用前面定义的表
with t1 as ( select * from hive_day03.students where age>20),
t2 as ( select * from t1 where course='CS')
SELECT * FROM t2;
-- CET表达式和子查询有什么区别
-- 1.在一个select语句中使用多个相同的子查询每次都需要计算一次,但是如果使用的是CET表达式则可以重复使用
-- 2.在CET表达式中后面的创建表可以使用先创建表的结果,子查询中不可以,能用CET查询的一定能用子查询解决
WITH t1 as ( select * from hive_day03.course where s_name='周杰轮')
select * from t1
union all
select * from t1;
CET表达式最大的优点:结构清晰,可读性高,便于维护
子查询可以作为值、列、表使用,CET只能作为表使用
3 高阶函数
① 炸裂函数
explod 将一个map或array类型数据拆分为一个表
explode属于UDTF函数,表生成函数,输入一行数据输出多行数据。
select explode(`array`(1,2,3,4));
-- 将一个数据拆分为一个表
select explode(`map`('name','xiaoming','age',18));
-- 给炸裂的数据字段起别名
select explode(`map`('name','xiaoming','age',18)) as (col1,col2);
② 侧视图!
语法:SELECT ... FROM 原表 LATTERAL VIEW explode() 表名 as 字段名;
本质上侧视图的连接规则,是从哪条记录炸裂出来的就和哪条语句进行连接
-- 数据准备:创建库
create database hive_day04;
create table hive_day04.The_NBA_championship(
team string,
champ_years array<string>
) row format delimited
fields terminated by ','
collection items terminated by '|';
--step2:HDFS上传数据文件到表中
--step3:验证
select * from the_nba_championship;
-- 将年份炸裂开
select explode(champ_years) from hive_day04.The_NBA_championship;
-- 显示每年夺冠的队伍名称
select explode(champ_years),team from hive_day04.The_NBA_championship;
报错提示:Only a single expression in the SELECT clause is supported with UDTF's. Error encountered near token 'team'无法显示该内容,因为一个team对应多个年份数据,这种数据不是结构化数据无法映射为表
with years as
( select explode(champ_years) as year from hive_day04.The_NBA_championship)
select year,team from hive_day04.The_NBA_championship join years
on array_contains(champ_years,year) order by year;
-- 数据连接操作复杂,hive提供了一种专门用于连接UDTF函数的方式叫做侧视图
-- explode作为表出现,子查询作为表出现必须有别名
select y.year,team from hive_day04.The_NBA_championship
lateral view explode(champ_years) y as year
order by y.year;
① 行列转换!
1 行转列
将图1转为图2

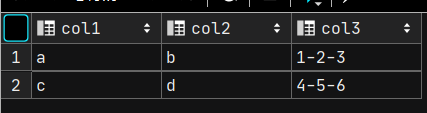
-- 1.将col1和colw两列数据相同的内容进行分组合并
select col1,col2 from hive_day04.row2col2 group by col1, col2;
-- 2.将col3中每一组的数据合并在一起,变成一个数组类型的值
-- collect_list将多行数据转换为一个数组类型的值 是一个聚合函数
select col1,col2,collect_list(col3) as col3
from hive_day04.row2col2
group by col1, col2;
-- collect_set将多行数据转换为一个数组类型的值并去重
select col1,col2,collect_set(col3) as col3
from hive_day04.row2col2
group by col1, col2;
-- 3.将col3中的数组中的每一个值使用-连接到一起,组成一个字符串
-- concat 不支持连接数组内容,只能当个字符
-- concat_ws() 依然无法连接,使用的数组内容必须是字符串数据类型,不能是int类型
-- [08S01][-101] Error while processing statement: FAILED: Execution Error, return code -101 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. Java heap space
-- select col1,col2,concat_ws('-', collect_list(cast(col3 as string))) as col3
-- from hive_day04.row2col2
-- group by col1, col2;
--最终SQL实现
select col1,col2,
concat_ws('-', collect_list(cast(col3 as string))) as col3
from hive_day04.row2col2
group by col1, col2;
列转行
将图1转换为图2
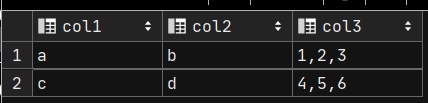
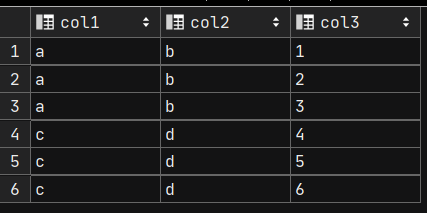
-- 数据准备
create table hive_day04.col2row2(
col1 string,
col2 string,
col3 string
)row format delimited fields terminated by '\t';
--加载数据查看结果
select * from hive_day04.col2row2;
-- 1.将col3的字符串转换为数组类型数据
select col1,col2,split(col3,',') as col3 from hive_day04.col2row2;
-- 2.使用炸裂函数,将col3炸成多行数据
select explode(split(col3,',')) as col3 from hive_day04.col2row2;
-- 3.使用侧视图,将原表与explode连接在一起
select col1,col2,c.col3 from hive_day04.col2row2
lateral view explode(split(col3,',')) c as col3;
② josn数据处理
现阶段json是我们最常用的数据传输流文件, 在json之前多用xml流进行数据传输
对于JSON字符串的处理方式
数据准备:
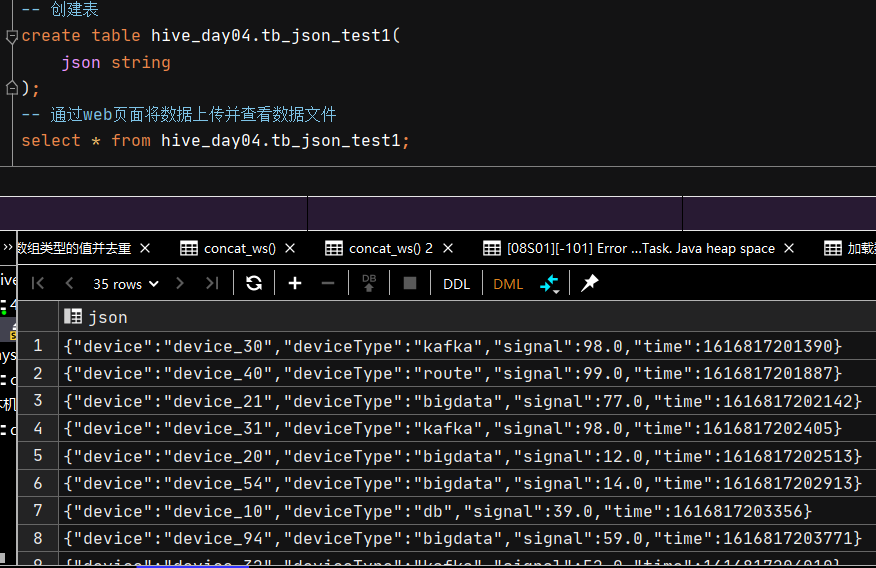
方法一:get_json_object 该json解析方式,一次只能解析一个json数据,效率低下
select get_json_object(json,'$.device') as device,
get_json_object(json,'$.deviceType') as deviceType,
get_json_object(json,'$.signal') as signal,
get_json_object(json,'$.time') as `time`
from hive_day04.tb_json_test1;
方法二:json_tuple 是输入一列数据,输出多列数据,此时json_tuple是UDTF函数
select json_tuple(json,'device','deviceType','signal','time')
as(device,deviceType,signal,`time`)
from hive_day04.tb_json_test1;
利用侧视图将原有的json数据也拼接到该表中
select json,device,deviceType,signal,`time`
from hive_day04.tb_json_test1
lateral view json_tuple(json,'device','deviceType','signal','time') json_t1
as device,deviceType,signal,`time` ;
方法三:比较常用的方法
建表时使用Serde机制进行解析,指定序列化方式加载json数据
create table hive_day04.tb_json_test2(
device string,
deviceType string,
signal string,
`time` bigint
)
row format serde 'org.apache.hive.hcatalog.data.JsonSerDe';

如果表中有一个字段是json类型数据,则我们使用get_json_object或者 json_tuple
如果表中对应的数据文件是json数据类型, 则我们使用JsonSerDe进行序列化解析
4 开窗函数
数据准备:
-- 数据准备:建表并且加载数据
create table hive_day04.website_pv_info(
cookieid string,
createtime string, --day
pv int
) row format delimited
fields terminated by ',';
-- 加载数据并查看
load data local inpath '/root/hivedata/website_pv_info.txt' into table website_pv_info;
select * from website_pv_info;
create table website_url_info (
cookieid string,
createtime string, --访问时间
url string --访问页面
) row format delimited
fields terminated by ',';
-- 加载数据并查看
load data local inpath '/root/hivedata/website_url_info.txt' into table website_url_info;
select * from website_url_info;
website_pv_info表:
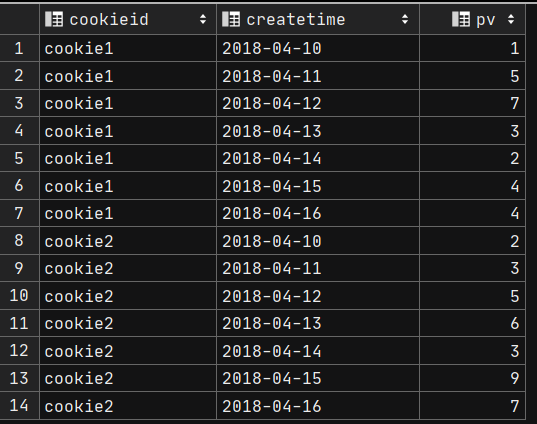
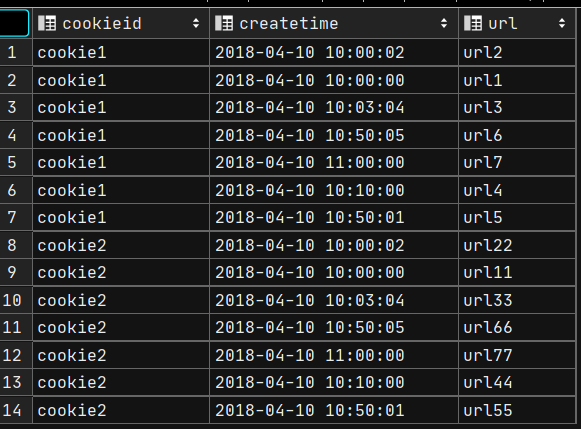
website_url_info表:
窗口聚合函数
需求1: 求出每个用户的总pv数
通过cookieid相同判断是同一个用户访问,所以我们需要按照cookieid进行分组
select cookieid,sum(pv) from hive_day04.website_pv_info
group by cookieid;
结果是2条数据。聚合完成后,数据的条目数减少了,数据发生了缺失
如果需要聚合,但不想让数据丢失应怎么做? 可以连接原表,也可以使用窗口函数
需求2: 获取网站的总pv数, 由于获取的是总数,所以不用分组(这种方式会造成数据缺失)
select sum(pv) from hive_day04.website_pv_info;
如果不想让数据缺失就使用over() 窗口函数
select *,sum(pv) over () as total_pv
from hive_day04.website_pv_info;
需求3: 求出每个用户的pv总数
既然是每个用户那就按照cookieid进行分组将pv数进行叠加(这种情况会造成数据缺失)
select cookieid,sum(pv) from hive_day04.website_pv_info
group by cookieid;
– 如果想数据缺失,就使用窗口函数over
– 如果不想数据缺失,就不能group by 那么该如何分组呢? over(partition by)
select *,sum(pv) over (partition by cookieid) as user_pv
from hive_day04.website_pv_info;
-- 这种书写方式,将开窗范围固定在每一组范围内,则聚合函数计算的数据范围就是该窗口范围
– 需求: 求出每个用户截止到当天你的累计pv数
– 每个用户的pv数 : sum(pv) over (partition by cookieid)
– 每个用户截止到当天的pv数??? sum(pv) over (partition by cookieid order by create_time)
select *, sum(pv) over (partition by cookieid order by createtime) as current_pv
from hive_day04.website_pv_info;
-- 此时开窗范围:是从本组的最开始位置到当前行为止, 计算其聚合值
窗口聚合函数:sum|max|min|avg OVER ([PARTITION BY <...>] [ORDER BY <....>] [<window_expression>])
控制窗口操作的范围:
rows between
- preceding:往前
- following:往后
- current row:当前行
- unbounded:起点
- unbounded preceding 表示从前面的起点 第一行
- unbounded following:表示到后面的终点 最后一行
控制窗口操作的范围(窗口函数的排序)!:
RANK() 排序字段值相同时赋值重复排名,总数不变 如排名1,1,3 跳跃
DENSE_RANK() 排序字段值相同时会重复排名,总数会减少,如排名1,1,2,不跳跃
ROW_NUMBER() 会根据顺序编号,1,2,3,4,5
数仓DWS层常用来去重过滤
select XXX,count (distinct yyy) from 数据表 group by xxx;
缺点: 比较消耗资源,而且容易产生数据倾斜或者OOM问题
# 使用with子查询 + row number()提前过滤 > 谓词下推
with tmp as(
select
row number() over()排名
from dwb.1
left join dwb.2
left join dwb.3
)
select
count(if(order rn = l and xxx, order id, null))
from tmp;
NTILE(n)把每个分组内的数据分为n桶
SELECT cookieid, createtime, pv,
RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1,
DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn4
FROM website_pv_info;
其他开窗函数
lag : 获取向上的第n行数据
lead : 获取向下第n行数据
first_value : 获取当前窗口中的第1行数据
last_value : 获取当前窗口的最后一行数据
-- 获取当前行的上一行数据, 有值就返回1, 没有值就为null
select *,lag(1) over (partition by cookieid) as lag_value
from hive_day04.website_url_info;
-- 获取当行上一行的时间
select *,lag(createtime, 1) over (partition by cookieid) as lag_value
from hive_day04.website_url_info;
-- 获取上一行的时间,如果上一行的时间为空则赋值为 '9999-99-99'
select *,lag(createtime, 1, '9999-99-99') over (partition by cookieid) as lag_value
from hive_day04.website_url_info;
-- lead
-- 获取三天后的时间,如果没有该时间则赋值为'9999-99-99'
-- lead 和 lag 开窗范围是分组范围内
select *, lead(createtime, 3, '9999-99-99') over (partition by cookieid order by createtime) as lead_value
from hive_day04.website_url_info;
-- lag和lead不能书写负数
-- select *, lead(createtime, -3, '9999-99-99') over (partition by cookieid order by createtime) as lead_value
-- from hive_day04.website_url_info;
-- first_value
-- last_value
-- 获取的是开窗范围的第一个值或最后一个值
-- first_value 和 last_value 开窗范围和 sum相同, 排序前 是整组范围内, 排序后是 该组开始位置,到当前行为止
select *, first_value(createtime) over (partition by cookieid order by createtime) as first,
last_value(createtime) over (partition by cookieid order by createtime) as last
from hive_day04.website_url_info;
-------------------------------------窗口函数练习--------------------------------------------
show tables;
-- 建表
CREATE TABLE hive_day04.order_info(
name string,
orderdate string,
cost string
);
-- 数据加载
INSERT INTO table order_info
VALUES ('jack', '2020-01-01', '10'),
('tony', '2020-01-02', '15'),
('jack', '2020-02-03', '23'),
('tony', '2020-01-04', '29'),
('jack', '2020-01-05', '46'),
('jack', '2020-04-06', '42'),
('tony', '2020-01-07', '50'),
('jack', '2020-01-08', '55'),
('mart', '2020-04-08', '62'),
('mart', '2020-04-09', '68'),
('neil', '2020-05-10', '12'),
('mart', '2020-04-11', '75'),
('neil', '2020-06-12', '80'),
('mart', '2020-04-13', '94');
-- 需求1 : 用户上次购买的时间
-- 分析: 分组: 用户 排序: 时间 聚合方式 : lag(orderdate)
select *,lag(orderdate, 1) over (partition by name order by orderdate) as last_date
from hive_day04.order_info;
-- 需求2 : 用户最近三次购物金额总和
-- 分析: 分组: 用户 排序 时间 聚合方式 : sum(cost) 开窗范围: 前2行到当前行
select *,
sum(cost) over (partition by name order by orderdate
rows between 2 preceding and current row) as sum_3_cost
from
hive_day04.order_info;
-- 需求3 : 用户当月单次消费最大值
-- 分析: 分组: 用户, 年份, 月份 排序 : 不需要 聚合类型: max(cost) 开窗范围 : 分组范围内(不排序默认就是分组范围内)
select *,
year(orderdate) as year,
month(orderdate) as month,
max(cost) over (partition by name, year(orderdate),month(orderdate))
as max_cost
from
hive_day04.order_info;
-- 需求4 : 用户每月购物金额总和
-- 分析: 分组: 用户, 年份, 月份 排序: 不需要 聚合类型: sum(cost) 开窗范围 : 分组内部所有数据(不排序默认就是分组范围内)
select *,
year(orderdate) as year,
month(orderdate) as month,
sum(cost) over (partition by name, year(orderdate), month(orderdate)) as month_total_cost
from
hive_day04.order_info;
-- 需求5 : 按照用户月消费金额进行排序(消费金额相同则跳过排名 例如 12245)
-- 分析: 分组: 用户 年份 月份 聚合类型: sum(cost) / rank(sum(cost)) 开窗范围: 分组范围内
with
t1 as (select name,
year(orderdate) as year,
month(orderdate) as month,
sum(cost) as month_cost
from hive_day04.order_info
group by name, year(orderdate), month(orderdate))
select *,rank() over (partition by name order by month_cost)
from t1;
-- 需求6 : 与用户本次消费与上次消费的时间间隔
-- 步骤1:获取本次消费的金额
select orderdate from hive_day04.order_info;
-- 步骤2:获取上次消费的时间
select orderdate,lag(orderdate,1) over (partition by name order by orderdate)
from hive_day04.order_info;
-- 步骤3:获取本次消费时间与上次消费时间的差值
-- org.apache.hadoop.hive.ql.parse.SemanticException:
-- Line 2:26 Invalid table alias or column reference 'last_time':
-- (possible column names are: order_info.name, order_info.orderdate, order_info.cost)
-- 此时不能直接使用本次和上一次的时间进行差值运算,因为当前select 语句钟 ,上一次的时间还没计算出来
select orderdate,lag(orderdate,1) over (partition by orderdate order by name) last_time,
datediff(orderdate,last_time) as cost_interval
from hive_day04.order_info;--报错
-- 可以借助CET表达式,在第一个临时表中
with time1 as ( select name,orderdate,
lag(orderdate,1) over (partition by name order by orderdate) last_orderdate from hive_day04.order_info)
select * ,datediff(orderdate,last_orderdate) as diff_cost_date from time1;
-- 需求7 : 计算用户消费的月环比增长率
-- 环比增长率=(本期的某个指标的值-上一期这个指标的值)/上一期这个指标的值*100%
-- 第一步,获取用户本月消费总额是多少,选择分组聚合,因为后续要计算上一个月的数据,若使用开窗聚合,每个月的数据重复很多,不方便获取上一个月的数据
select name,year(orderdate) as year,
month(orderdate) as month,
sum(cost) as month_total_cost
from hive_day04.order_info
group by name,year(orderdate),month(orderdate);
-- 第二步,获取用户上一个月的消费总金额
with t1 as ( select name,year(orderdate) as year,
month(orderdate) as month,
sum(cost) as month_total_cost
from hive_day04.order_info
group by name,year(orderdate),month(orderdate)
order by year(orderdate),month(orderdate)
)
select *,lag(month_total_cost) over (partition by name order by year,month) as last_month_total_cost
from t1;
-- 第三步,计算环比增长率
with t1 as ( select name,year(orderdate) as year,
month(orderdate) as month,
sum(cost) as month_total_cost
from hive_day04.order_info
group by name,year(orderdate),month(orderdate)
order by year(orderdate),month(orderdate)
),t2 as ( select *,
lag(month_total_cost) over (partition by name order by year,month) as last_month_total_cost
from t1
)
select *,concat(round((month_total_cost - last_month_total_cost)/last_month_total_cost*100),'%')
as increment_rate
from t2;
-- 需要使用的字段必须已经计算完成,不能为正在计算的字段
-- 若需要使用正在使用的字段,需使用with as 创建临时表计算出来
-- 每次遇到开窗函数需要考虑以下几个方便
-- 1.按照什么分组
-- 2.按照什么排序
-- 3.使用哪种聚合方式
-- 4.开窗范围是从哪到哪
over partition by会把每个数据的明细都显现出来,聚合显示多条
group by 聚合只会显示一条
练习:
-- 练习1 : 用户下一次购买的时间
-- 下一次购买时间
select *,lead(orderdate, 1) over (partition by name order by orderdate) as next_date
from hive_day04.order_info;
-- 练习2 : 用户当月单词消费最小值
-- 方法一:
select *,year(orderdate) as year,month(orderdate) as month,
min(cost) over (partition by name, year(orderdate),month(orderdate)) as min_cost
from hive_day04.order_info;
-- 方法二
select *,substr(orderdate,1,7) as year_month,
min(cost) over (partition by name,substr(orderdate,1,7)) as min_cost
from hive_day04.order_info;
-- 练习3 : 用户上一次+这次的购物金额
select *,sum(cost) over (partition by name order by orderdate
rows between 1 preceding and current row) as sum_2_cost
from hive_day04.order_info;
dense_rank()对结果集进行排序,排名值没有间断。 特定行的排名等于该特定行之前不同排名值的数量加一
-- 练习4 : 按照用户月消费次数进行排序(消费金额相同不跳过排名 例如 12234)
with t1 as (select name,
year(orderdate) as year,
month(orderdate) as month,
count(name) as cost_name
from hive_day04.order_info
group by name, year(orderdate), month(orderdate))
select *,dense_rank() over (partition by name order by cost_name) drank1
from t1;
5 特殊函数
1.grouping sets :根据给定的不同的维度组合进行分组聚合【分组函数】,结果相当于挨个分组聚合然后union合并
语法:grouping sets (维度1,维度2,维度3)
-- Hive语法
select
daystr, -- 日期
city, -- 城市
count(distinct cookieid) as cnt --个数
from test.t_cookie
group by daystr,city
grouping sets (daystr,city,(daystr,city));
结果与下面一样
select daystr, -- 日期
null as city, -- 城市
count(distinct cookieid) as cnt --个数
from test.t_cookie group by daystr
union all
select null as daystr, -- 日期
city, -- 城市
count(distinct cookieid) as cnt --个数
from test.t_cookie group by city
union all
select daystr, -- 日期
city, -- 城市
count(distinct cookieid) as cnt --个数
from test.t_cookie group by daystr,city;
2.grouping
语法:select grouping(维度1,维度2,维度3……) from 数据表 group by grouping sets();
select
daystr,
city,
count(distinct cookieid) as cnt,
grouping(daystr) as dg,
grouping(city) as cg,
grouping(daystr, city) as dcg
from hive.test.t_cookie
group by
grouping sets(
daystr,
city,
(daystr, city)
);
① 在以上案例中,我们使用【grouping sets】方式实现了日期维度、城市维度以及日期+城市维度的分组操作
② 在select查询字段中,我们通过【dg】字段以及【cookie访问量指标+dg】完成了对日期维度判断操作,【cg】字段完成了对城市维度的判断?通过【dcg】实现了对日期+城市维度的判断操作?
3.cube函数
功能:将给定的维度自动按照所有维度子集进行分组聚合合并的结果
全集:group by + cube(A,B,C)
子集:(),(A),(B),(C),(A,B),(A,C) , (B,C), (A,B,C)
语法:cube(维度1,维度2,维度3……)
特点:语法简单
场景:一般不常用,工作中一般不对空集【不基于维度】做计算
select
daystr, -- 日期
city, -- 城市
count(distinct cookieid) as cnt --个数
from test.t_cookie
group by
-- 自动按照所有子集分组:(),(daystr),(city),(daystr,city)
cube (daystr,city);
4.rollup函数
功能:将给定的维度自动按照维度,从左往右每次递减最右边的维度的维度子集进行分组聚合合并的结果
全集:group by + rollup(A,B,C)
子集:(A,B,C),(A,B),(A),()
语法:rollup(维度1,维度2,维度3……)
特点:维度逐级递减
select
daystr, -- 日期
city, -- 城市
count(distinct cookieid) as cnt --个数
from test.t_cookie
group by
rollup (daystr,city);















 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









