







编|泽南
源|机器之心
性能和效率都超越英伟达 A100,这样的超算我有不止十台。
我们还没有看到能与 ChatGPT 相匹敌的 AI 大模型,但在算力基础上,领先的可能并不是微软和 OpenAI。
本周二,谷歌公布了其训练语言大模型的超级计算机的细节,基于 TPU 的超算系统已经可以比英伟达的同类更加快速、节能。
谷歌张量处理器(tensor processing unit,TPU)是该公司为机器学习定制的专用芯片(ASIC),第一代发布于 2016 年,成为了 AlphaGo 背后的算力。与 GPU 相比,TPU 采用低精度计算,在几乎不影响深度学习处理效果的前提下大幅降低了功耗、加快运算速度。同时,TPU 使用了脉动阵列等设计来优化矩阵乘法与卷积运算。
当前,谷歌 90% 以上的人工智能训练工作都在使用这些芯片,TPU 支撑了包括搜索的谷歌主要业务。作为图灵奖得主、计算机架构巨擘,大卫・帕特森(David Patterson)在 2016 年从 UC Berkeley 退休后,以杰出工程师的身份加入了谷歌大脑团队,为几代 TPU 的研发做出了卓越贡献。

如今 TPU 已经发展到了第四代,谷歌本周二由 Norman Jouppi、大卫・帕特森等人发表的论文《 TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings 》详细介绍了自研的光通信器件是如何将 4000 多块芯片并联成为超级计算机,以提升整体效率的。

论文链接:
https://arxiv.org/ftp/arxiv/papers/2304/2304.01433.pdf
TPU v4 的性能比 TPU v3 高 2.1 倍,性能功耗比提高 2.7 倍。基于 TPU v4 的超级计算机拥有 4096 块芯片,整体速度提高了约 10 倍。对于类似大小的系统,谷歌能做到比 Graphcore IPU Bow 快 4.3-4.5 倍,比 Nvidia A100 快 1.2-1.7 倍,功耗低 1.3-1.9 倍。
除了芯片本身的算力,芯片间互联已成为构建 AI 超算的公司之间竞争的关键点,最近一段时间,谷歌的 Bard、OpenAI 的 ChatGPT 这样的大语言模型(LLM)规模正在爆炸式增长,算力已经成为明显的瓶颈。
由于大模型动辄千亿的参数量,它们必须由数千块芯片共同分担,并持续数周或更长时间进行训练。谷歌的 PaLM 模型 —— 其迄今为止最大的公开披露的语言模型 —— 在训练时被拆分到了两个拥有 4000 块 TPU 芯片的超级计算机上,用时 50 天。
谷歌表示,通过光电路交换机(OCS),其超级计算机可以轻松地动态重新配置芯片之间的连接,有助于避免出现问题并实时调整以提高性能。
下图展示了 TPU v4 4×3 方式 6 个「面」的链接。每个面有 16 条链路,每个块总共有 96 条光链路连接到 OCS 上。要提供 3D 环面的环绕链接,相对侧的链接必须连接到相同的 OCS。因此,每个 4×3 块 TPU 连接到 6 × 16 ÷ 2 = 48 个 OCS 上。Palomar OCS 为 136×136(128 个端口加上 8 个用于链路测试和修复的备用端口),因此 48 个 OCS 连接来自 64 个 4×3 块(每个 64 个芯片)的 48 对电缆,总共并联 4096 个 TPU v4 芯片。
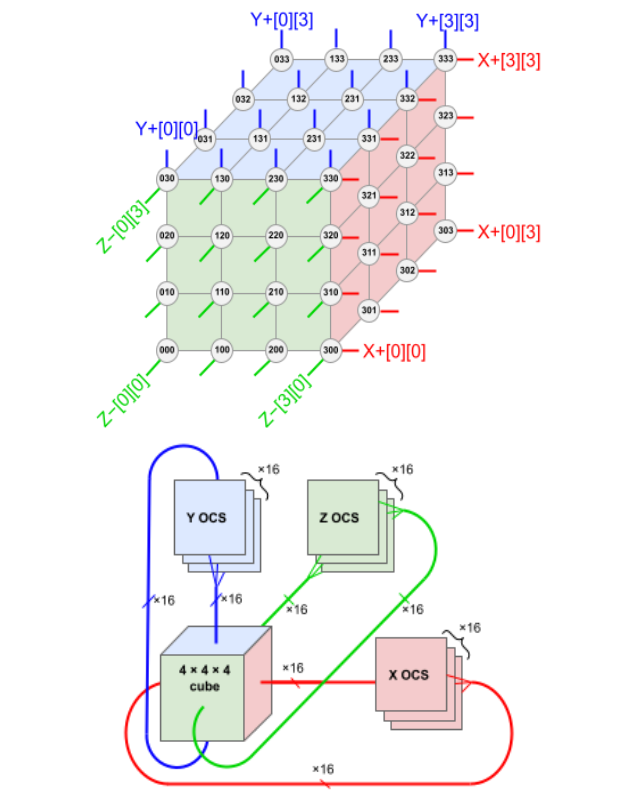
根据这样的排布,TPU v4(中间的 ASIC 加上 4 个 HBM 堆栈)和带有 4 个液冷封装的印刷电路板 (PCB)。该板的前面板有 4 个顶部 PCIe 连接器和 16 个底部 OSFP 连接器,用于托盘间 ICI 链接。

随后,八个 64 芯片机架构成一台 4096 芯片超算。

与超级计算机一样,工作负载由不同规模的算力承担,称为切片:64 芯片、128 芯片、256 芯片等。下图显示了当主机可用性从 99.0% 到 99.9% 不等有,及没有 OCS 时切片大小的「有效输出」。如果没有 OCS,主机可用性必须达到 99.9% 才能提供合理的切片吞吐量。对于大多数切片大小,OCS 也有 99.0% 和 99.5% 的良好输出。
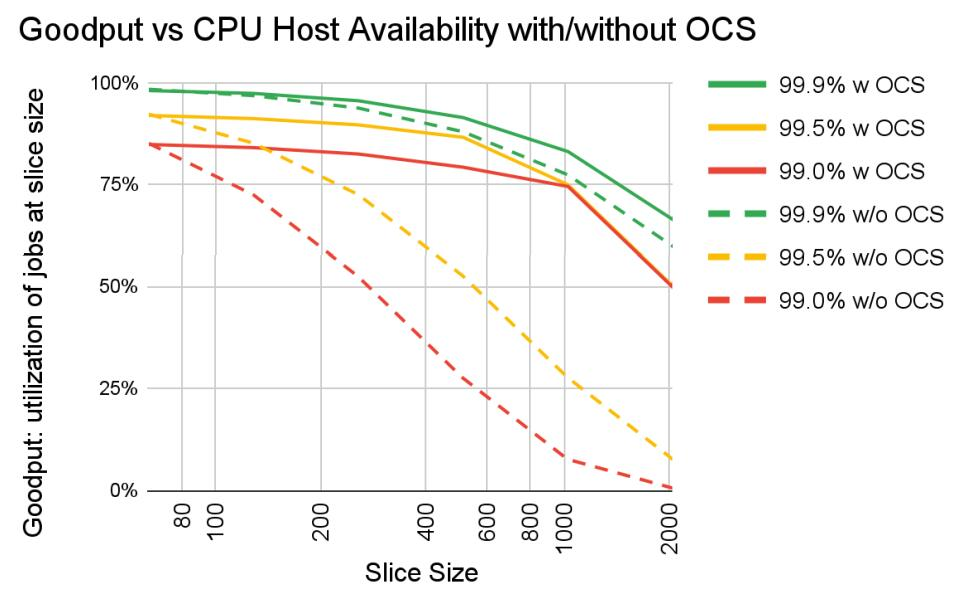
与 Infiniband 相比,OCS 的成本更低、功耗更低、速度更快,成本不到系统成本的 5%,功率不到系统功率的 3%。每个 TPU v4 都包含 SparseCores 数据流处理器,可将依赖嵌入的模型加速 5 至 7 倍,但仅使用 5% 的裸片面积和功耗。
「这种切换机制使得绕过故障组件变得容易,」谷歌研究员 Norm Jouppi 和谷歌杰出工程师大卫・帕特森在一篇关于该系统的博客文章中写道。「这种灵活性甚至允许我们改变超级计算机互连的拓扑结构,以加速机器学习模型的性能。」
在新论文上,谷歌着重介绍了稀疏核(SparseCore,SC)的设计。在大模型的训练阶段,embedding 可以放在 TensorCore 或超级计算机的主机 CPU 上处理。TensorCore 具有宽 VPU 和矩阵单元,并针对密集操作进行了优化。由于小的聚集 / 分散内存访问和可变长度数据交换,在 TensorCore 上放置嵌入其实并不是最佳选择。在超级计算机的主机 CPU 上放置嵌入会在 CPU DRAM 接口上引发阿姆达尔定律瓶颈,并通过 4:1 TPU v4 与 CPU 主机比率放大。数据中心网络的尾部延迟和带宽限制将进一步限制训练系统。
对此,谷歌认为可以使用 TPU 超算的总 HBM 容量优化性能,加入专用 ICI 网络,并提供快速收集 / 分散内存访问支持。这导致了 SparseCore 的协同设计。
SC 是一种用于嵌入训练的特定领域架构,从 TPU v2 开始,后来在 TPU v3 和 TPU v4 中得到改进。SC 相对划算,只有芯片面积的约 5% 和功率的 5% 左右。SC 结合超算规模的 HBM 和 ICI 来创建一个平坦的、全局可寻址的内存空间(TPU v4 中为 128 TiB)。与密集训练中大参数张量的全部归约相比,较小嵌入向量的全部传输使用 HBM 和 ICI 以及更细粒度的分散 / 聚集访问模式。
作为独立的核心,SC 允许跨密集计算、SC 和 ICI 通信进行并行化。下图显示了 SC 框图,谷歌将其视为「数据流」架构(dataflow),因为数据从内存流向各种直接连接的专用计算单元。
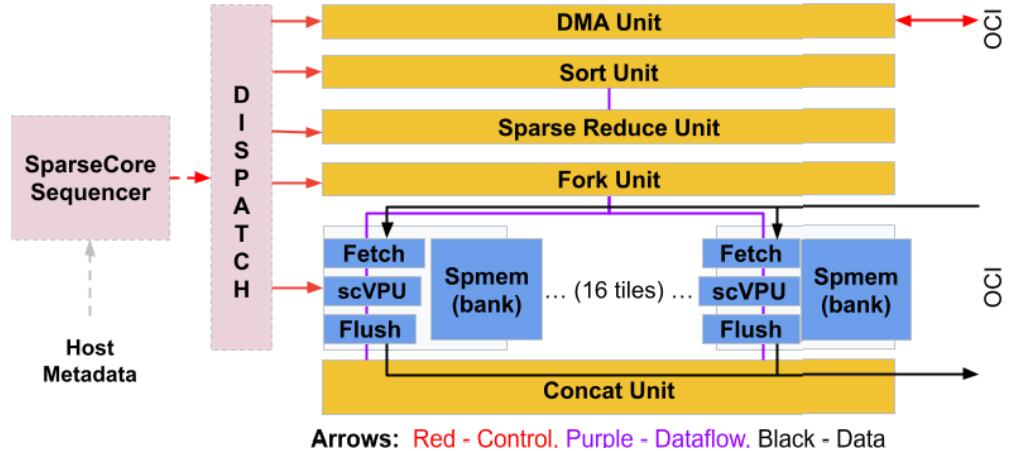
最通用的 SC 单元是 16 个计算块(深蓝色框)。每个 tile 都有一个关联的 HBM 通道,并支持多个未完成的内存访问。每个 tile 都有一个 Fetch Unit、一个可编程的 8-wide SIMD Vector Processing Unit 和一个 Flush Unit。获取单元将 HBM 中的激活和参数读取到 2.5 MiB 稀疏向量内存 (Spmem) 的图块切片中。scVPU 使用与 TC 的 VPU 相同的 ALU。Flush Unit 在向后传递期间将更新的参数写入 HBM。此外,五个跨通道单元(金色框)执行特定的嵌入操作,正如它们的名称所解释的那样。
与 TPU v1 一样,这些单元执行类似 CISC 的指令并对可变长度输入进行操作,其中每条指令的运行时间都取决于数据。
在特定芯片数量下,TPU v3/v4 对分带宽比高 2-4 倍,嵌入速度可以提高 1.1-2.0 倍。
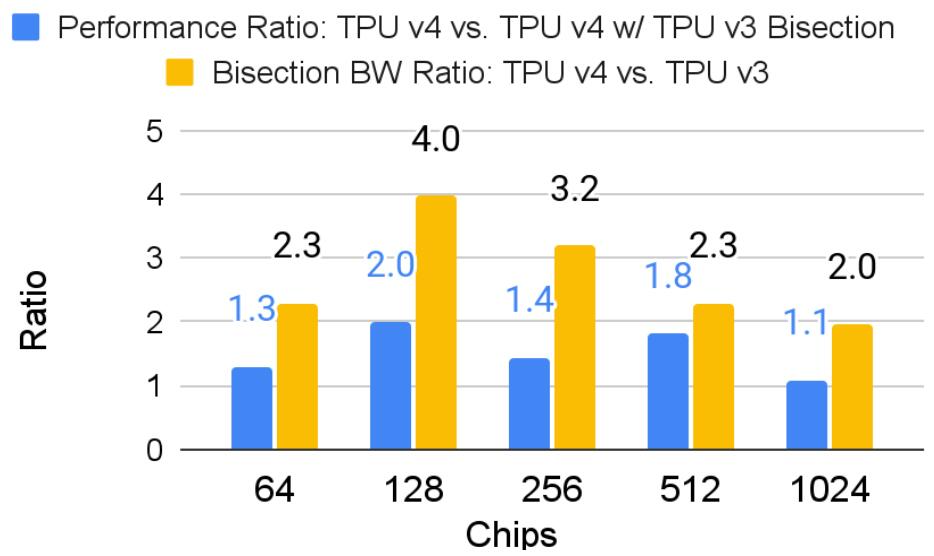
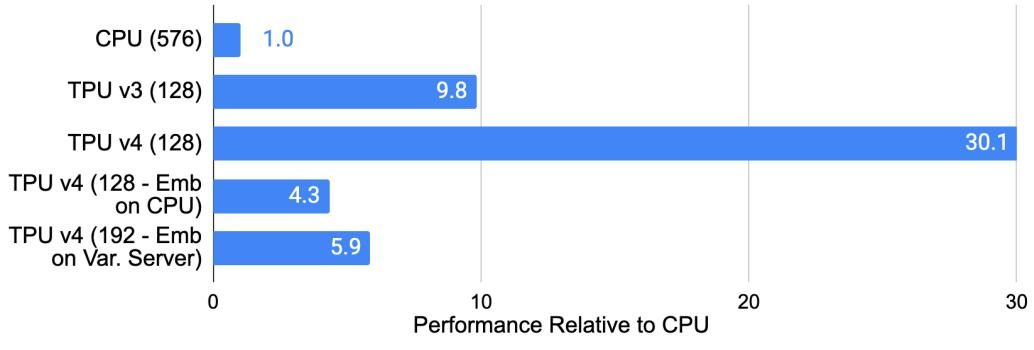
下图展示了谷歌自用的推荐模型(DLRM0)在不同芯片上的效率。TPU v3 比 CPU 快 9.8 倍。TPU v4 比 TPU v3 高 3.1 倍,比 CPU 高 30.1 倍。
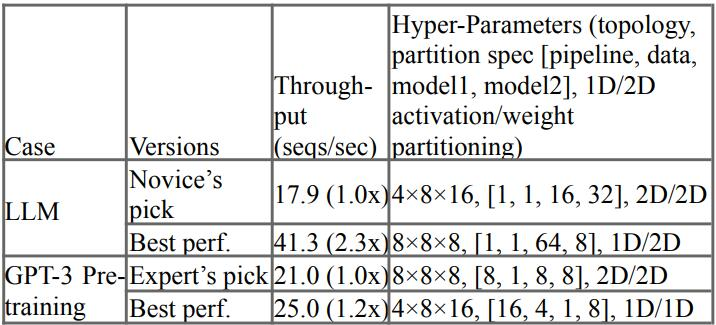
谷歌探索了 TPU v4 超算用于 GPT-3 大语言模型时的性能,展示了预训练阶段专家设计的 1.2 倍改进。
虽然谷歌直到现在才公布有关其超级计算机的详细信息,但自 2020 年以来,基于 TPU 的 AI 超算一直在位于俄克拉荷马州的数据中心发挥作用。谷歌表示,Midjourney 一直在使用该系统训练其模型,最近一段时间,后者已经成为 AI 画图领域最热门的平台。

谷歌在论文中表示,对于同等大小的系统,其芯片比基于英伟达 A100 芯片的系统快 1.7 倍,能效高 1.9 倍,后者与第四代 TPU 同时上市,并被用于 GPT-4 的训练。
对此,英伟达发言人拒绝置评。
当前英伟达的 AI 芯片已经进入 Hopper 架构的时代。谷歌表示,未对第四代 TPU 与英伟达目前的旗舰 H100 芯片进行比较,因为 H100 在谷歌芯片之后上市,并且采用了更先进的制程。
但同样在此,谷歌暗示了下一代 TPU 的计划,其没有提供更多细节。Jouppi 告诉路透社,谷歌拥有开发「未来芯片的健康管道」。
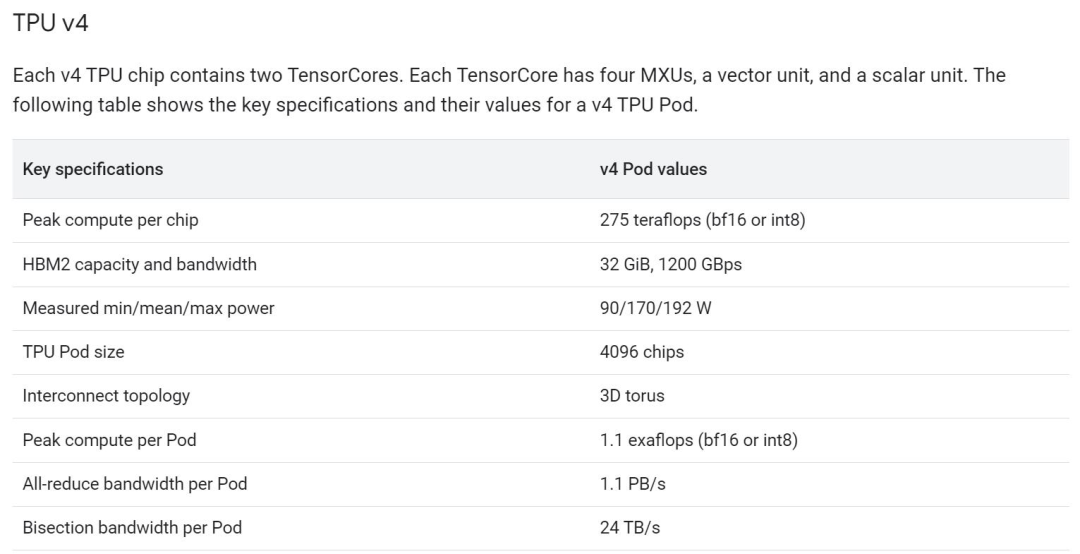
TPU v4 比当代 DSA 芯片速度更快、功耗更低,如果考虑到互连技术,功率边缘可能会更大。通过使用具有 3D 环面拓扑的 3K TPU v4 切片,与 TPU v3 相比,谷歌的超算也能让 LLM 的训练时间大大减少。
性能、可扩展性和可用性使 TPU v4 超级计算机成为 LaMDA、MUM 和 PaLM 等大型语言模型 (LLM) 的主要算力。这些功能使 5400 亿参数的 PaLM 模型在 TPU v4 超算上进行训练时,能够在 50 天内维持 57.8% 的峰值硬件浮点性能。
谷歌表示,其已经部署了数十台 TPU v4 超级计算机,供内部使用和外部通过谷歌云使用。
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
[1]https://www.reuters.com/technology/google-says-its-ai-supercomputer-is-faster-greener-than-nvidia-2023-04-05/_

















 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









