






大家想必都知道,AI用着用着就容易“胡言乱语”,我们把这种现象叫做“AI幻觉”。
简单来说,幻觉就是当AI模型在生成内容或回答问题时,可能会“编造”一些并不真实或不符合事实的信息。这些编造的信息看起来可能很合理,但实际上它们要么是错误的,要么是与现实情况不符的。它会让人误以为AI模型无所不知,但实际上它可能只是基于一些不完整的或错误的信息来生成内容的。
笔者在日常使用AI的时候,也深受其幻觉问题影响。前不久,笔者发现来自一群来自Patronus AI、 Contextual AI和斯坦福大学的老外整了个“遥遥领先”的幻觉检测模型,号曰“Lynx”。

论文标题:
Lynx: An Open Source Hallucination Evaluation Model
论文链接:
https://arxiv.org/abs/2407.08488

什么是Lynx?
Lynx是一种开源的幻觉检测大型语言模型(LLM),Lynx旨在减轻检索增强生成(RAG)技术中的幻觉问题。
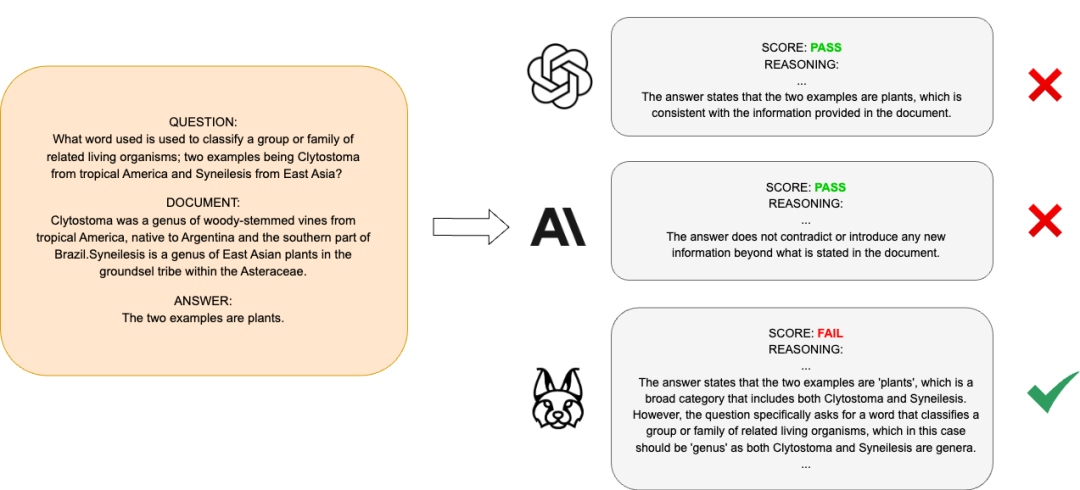
▲ChatGPT、Claude和Lynx对于同一个问题的回答
Lynx是怎样“炼成”的?
1.数据集构建
-
数据来源:研究团队从多个现有的问答(QA)数据集中抽取样本,包括CovidQA、PubMedQA、DROP和FinanceBench等。
-
样本数量:训练数据集由2400个样本组成,其中800个样本用于验证。对于每个子任务,他们从源数据集的训练部分中抽取了600个示例,其中300个被扰动以生成看似合理但不忠实于上下文的幻觉答案。
2.数据扰动
为了训练Lynx以识别并避免幻觉答案,研究团队通过引入扰动来生成一些幻觉答案。这些幻觉答案在表面上看起来合理,但实际上并不符合问题的真实上下文。
▲研究者设置的一些幻觉答案
3.模型微调
-
基础模型:Lynx是在Llama-3-70B-Instruct模型的基础上进行微调的。Llama-3-70B-Instruct是一个具备指令遵循能力的大语言模型。
-
微调过程:研究团队利用上述构建的数据集对Llama-3-70B-Instruct进行微调,特别关注硬检测幻觉的情况。
4.推理能力蒸馏
为了提高模型的零样本性能,研究团队采用了Chain of Thought(CoT)技术。他们使用GPT-4o生成训练集中每个示例的标签对应的推理过程,并将这些推理过程作为助手响应的一部分,在指令调优过程中提供。
5.训练配置
-
混合精度训练:采用混合精度训练以加速训练过程,同时使用flash attention。
-
优化器:使用AdamW优化器,其中和,并启用梯度裁剪,阈值为1.0。
-
调度器:使用带有预热步骤的余弦调度器,预热步骤设置为100。
-
硬件配置:对于评估70B模型,研究团队使用vLLM在8个H100 GPU上进行,设置了tensor_parallel = 8。对于评估8B变体,则使用模型和数据分片技术。
6.推理生成
使用Hugging Face pipelines进行生成,采用贪婪解码方式,最大新标记数设置为600。
Lynx有多厉害?
为了评估Lynx,研究者们提出了一个全面的幻觉评估基准HaluBench,该基准包含了来自不同现实世界领域的15,000个样本。
实验结果显示,Lynx在HaluBench上的表现优于GPT-4o、Claude-3-Sonnet等其他LLM模型。Lynx、HaluBench以及相关的评估代码已被公开发布,供公众使用。
测试发现,Lynx(70B)在所有评估任务中的准确率最高,平均比GPT-4o高出近1%。
在特定领域如PubMedQA的医疗答案准确性识别中,Lynx(70B)比GPT-4o高出了8.3%。
此外,Lynx(8 B)和Lynx(70B)都比基础的Llama 3模型在所有任务上表现出更高的准确性,其中70B的微调模型使准确率提高了7.8%。
在与封闭源代码模型的比较中,Lynx也显示出显著的优势,平均超出GPT-3.5-Turbo 27.6%的准确率。
在HaluBench基准测试中,Lynx(70B)的整体最佳表现为87.4%,而GPT-3.5-Turbo的准确率最低,平均只有58.7%。
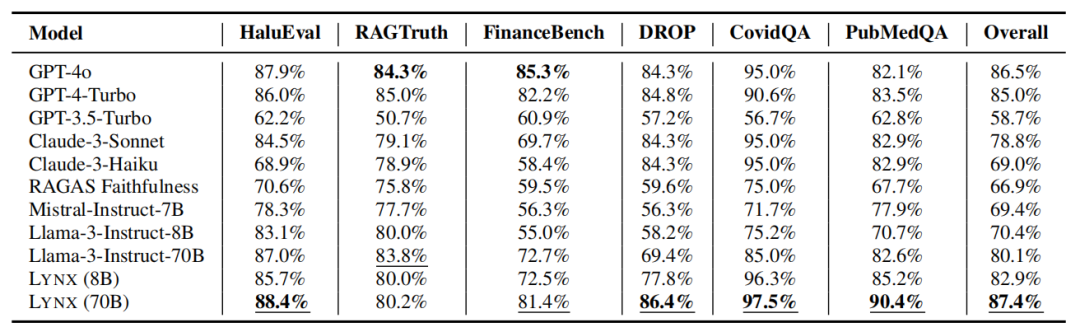
▲测试结果,高下立判
目前研究的缺陷和未来的工作?
该研究的局限性主要在于三个方面:
-
一是RAG系统中的失败情况,除了LLM生成的问题外,检索组件可能无法返回与查询相关的上下文,导致下游的幻觉生成。
-
二是数据源的不一致性、预处理和后处理步骤的错误、以及包含冲突或误导信息的源文档,都对故障检测构成挑战,需要进一步的研究来解决。
-
三是大部分数据集都是英文的,限制了其在多语种应用中的适用性。
未来的工作方向:
-
扩展HaluBench以覆盖非英文和低资源语言
-
将Lynx应用于更多的NLP领域,如抽象概括任务,检查LLM生成的摘要是否与源文档信息一致。
-
将Lynx应用于自然语言推理任务,因为幻觉检测与NLI有密切关系,一个强大的幻觉检测模型可能在其他NLP领域也能进行有效的推理。
-
评估模型的诚实性和事实性。
一点号外(夹带私货)
有意思的是,Lynx在英文里有“猞猁”的意思,这是一种敏捷的猫科动物,开发者起这个名字,是否也希望这个模型像猞猁一样又快又好地揪出幻觉错误来?
此外,玩过《明日方舟》的朋友应该知道里面有个角色叫凯尔希,是一只猞猁。在某次支线剧情之后,有这样的梗图流传:

好吧,还是希望这个“猞猁”向着“无所不知”的方向迈进!


















 447
447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









