






作者 | 智商掉了一地、Python
最近大型语言模型(LLMs)的指令微调备受研究人员的关注,因为它可以开发 LLM 遵循指令的潜力,使其更加符合特定的任务需求。虽然指令微调(Instruction Tuning)作为一种微调方法,与传统的微调相比,所需要的数据较少并更具有人类友好性,还可以用于多种不同的下游任务。这为促进 LLM 适应下游任务提供了优势,但在大量数据上训练拥有数千万甚至数十亿个参数的模型会导致高昂的计算成本。
为了解决上述问题,该论文作者提出将重点放在减少 LLM 指令微调所需的数据量,以降低训练成本和提高数据效率,这被称为低训练数据指令微调(LTD instruction tuning)。具体来说,本文对 LLM 训练中使用的数据进行了初步探索,并确定了多个关于 LLM 训练任务专业化的观察结果,例如优化特定任务的性能、指令微调所需的指令类型数量以及任务特定模型所需的数据量。研究结果表明,只需要使用原始数据集的不到 0.5% 便足以训练出高性能的任务专用模型,相比使用完整任务相关数据进行训练的模型,其性能提高了 2%。
论文题目:
Maybe Only 0.5% Data is Needed: A Preliminary Exploration of Low Training Data Instruction Tuning
论文链接:
https://arxiv.org/abs/2305.09246
大模型研究测试传送门
ChatGPT传送门(免墙,可直接测试):
https://yeschat.cn
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
https://gpt4test.com
什么是 LLM 的指令微调?
大模型由于其参数多且复杂,在实际应用中普遍存在训练时间长、计算资源耗费大等问题。为了提高模型的训练和推理效率,需要对模型进行指令微调。
指令微调(Instruction tuning)是指在少量数据或有限数据条件下,从已有数据中识别出最有价值的核心样本,并通过微调模型的指令来帮助模型获取下游任务的知识,从而实现可比甚至更好的性能。这种方法主要针对预训练语言模型,因为 LLM 需要大量数据来训练,但在某些情况下,如果我们只希望优化特定任务的性能,则只需要在目标任务数据上微调模型的指令,而不是在大量数据上进行微调,可以大大节省时间和计算资源。
指令微调通常是指微调模型的注意力机制、位置编码或其他需要微调的参数,使其适应特定任务的需求。总之,大型模型的指令微调对于提高模型的训练和推理效率至关重要,而不同的指令微调策略可以针对不同的模型和任务需求进行选择和优化。
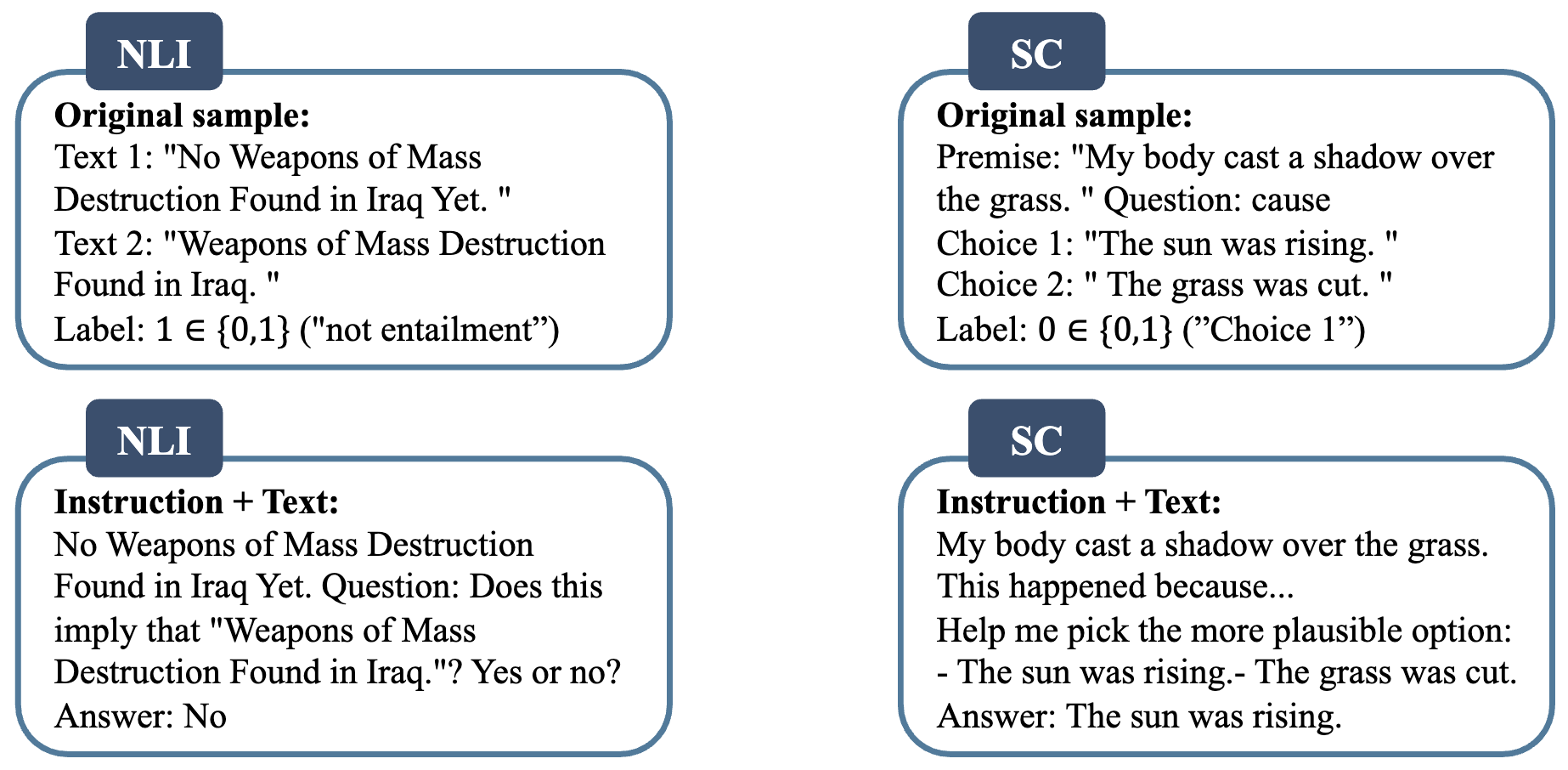
如图 1 所示是微调和指令微调之间的区别。在微调中,语言模型预测样本的标签,而在指令微调中,语言模型回答指令集中的问题。NLI 任务涉及确定两个文本部分(通常称为“前提”和“假设”)之间的逻辑关系。NLI 的目标是根据前提中提供的信息,确定假设是否为真、假或未确定。句子完成(SC)任务涉及预测最可能的单词或一系列单词,以完成给定的句子或短语。
论文速览
本文主要从数据角度来探讨如何降低 LLM 训练阶段的成本,提高数据效率。为了实现该目的,作者通过从现有数据中识别出最有价值的核心样本来帮助模型获取下游任务的知识,并仅用少量数据来实现可比甚至更好的性能。
方法流程如图 2 所示,潜在空间用三个矩形表示,每个任务代表其中一个颜色系列。具有相同色系但不同色调的点,对应于来自同一任务但来自不同数据集的数据,如 NLI 任务有 5 个数据集,因此有 5 种不同的色调。
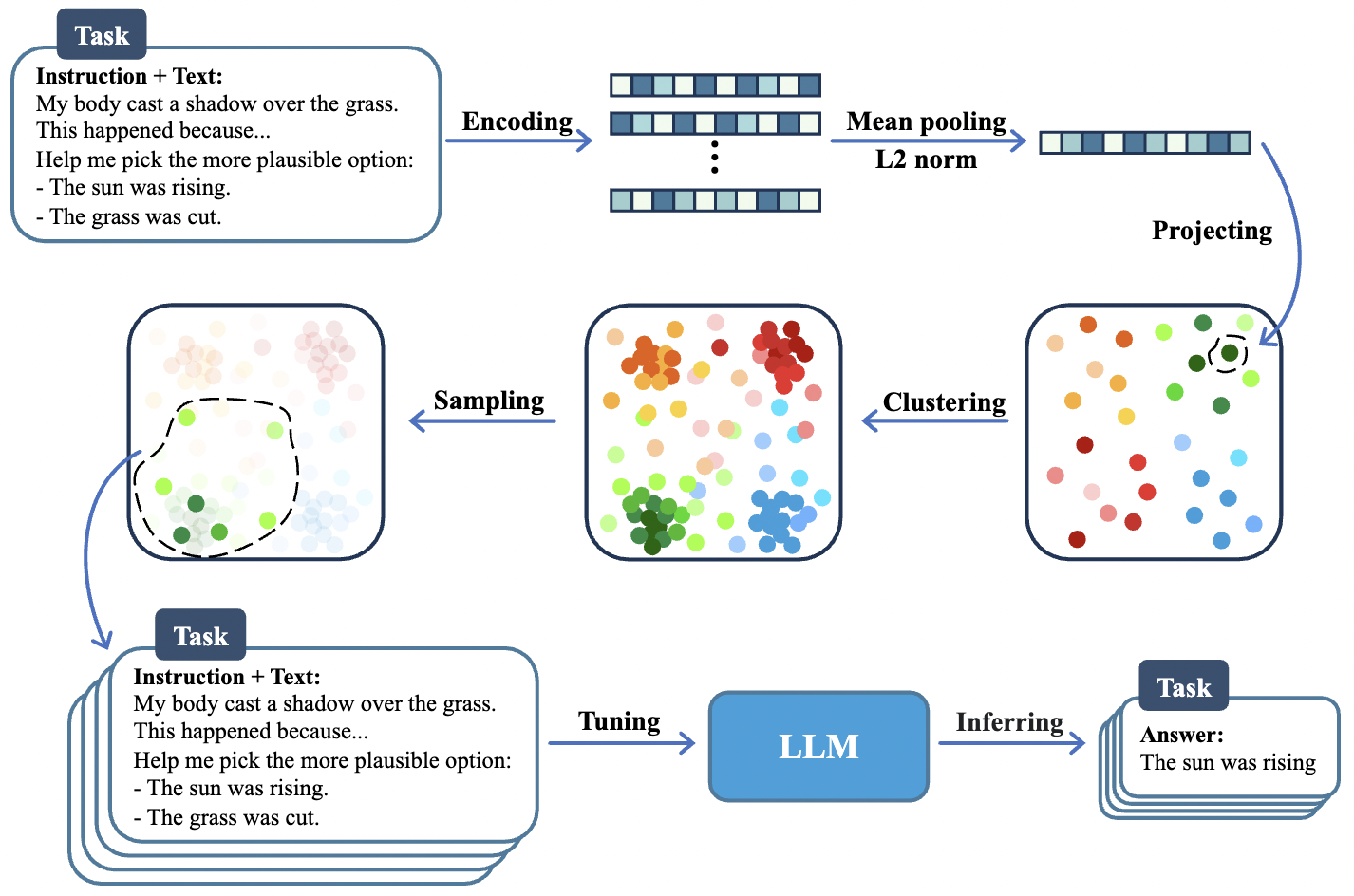
主要分为以下几步:
- 将每个句子编码成嵌入向量,并进行均值池化和 L2 归一化的预处理。
- 在潜在空间中,将所有样本点聚类成几个类别。
- 从这些聚类样本中进行采样,找到原始分布中的核心样本。
- 使用这些检索到的样本来指导微调 LLM 并进行评估。
实验
作者在选择特定任务和指令格式后,在总共 11 个数据集上进行了实验,这些数据跨越 4 个自然语言处理任务:自然语言推理(NLI,1.9M 个 token)、句子补语(SC,660.6K 个 token)、词义消解(WSD,25.5K 个 token)和指代消解(CR,185.1K 个 token)。成功使用原始数据集不到 0.5% 的数据训练了一个特定任务模型,相当于将数据规模缩小了 200 倍,并与在 P3 中基于任务相关数据训练的模型具有可比性能。
对于自然语言推理(NLI)任务,得出了以下观察结果:
- 如果只是为了优化特定任务的性能,仅在目标任务数据上微调的 LLM 模型很可能比在不同类型任务数据上微调的模型更优。
- 另外,在专门针对单个任务时,似乎只需要一个指令进行指令微调。虽然增加指令类型数量可以提高性能,但边际效应变得不那么显著,甚至可能有单一指令优于十种指令的情况。
- 与为整体任务性能训练模型相反,结果还表明,16000 个实例(1.9M 个 token,占 P3 的 0.5%)可能足以训练一个 NLI 任务特定的模型。
综合来看,在特定任务和指令格式下,仅使用少量的数据就可以训练具有可比性能的模型。
小结
本文主要从低训练数据指令微调的角度研究任务特定模型的性能,这为降低训练成本、提高数据效率提供了一些初步发现和洞见。由于计算资源的限制,该研究还存在一些限制,未来的工作可以在更大的模型上验证这些思路,并使用更广泛的任务和数据集。
基于这些研究结果,我们可以期待未来在低训练数据下的指令微调方面能够有更深入的探究和应用。除了这种方法,作者还探索了另外两种方法来减少 fine train 所需的训练数据,期待后续完善的论文。总而言之,本文迈出了重要一步,它为未来探索低训练数据下的指令微调方向指明了一定方向,我们也期待能够看到该领域的更多发展和创新,希望有朝一日 DIY 大模型不再是梦~

















 429
429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









