






引言:大语言模型事实召回机制探索
该论文深入研究了基于Transformer的语言模型在零射击和少射击场景下的事实记忆任务机制。模型通过任务特定的注意力头部从语境中提取主题实体,并通过多层感知机回忆所需答案。作者提出了一种新的分析方法,可以将多层感知机的输出分解成人类可以理解的组件。此外,观察到模型的最后一层具有抑制正确预测的反过度自信机制,通过利用模型解释来减轻这种抑制,从而提高事实回忆性能。这些解释已在各种语言模型和任务中得到评估。
论文标题:
Interpreting Key Mechanisms of Factual Recall in Transformer-Based Language Models
论文链接:
https://arxiv.org/pdf/2403.19521.pdf
GPT-3.5研究测试: https://hujiaoai.cn
GPT-4研究测试: https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4): https://hiclaude3.com
Transformer语言模型的事实回忆
1. 事实回忆任务的重要性与研究背景
事实回忆任务在自然语言处理领域占据着举足轻重的地位。近年来,基于Transformer的语言模型在理解和生成自然语言方面取得了显著成就,但它们的内部机制仍然相对不透明,对于事实回忆任务的研究尤为关键。有学者表示,语言模型在处理事实回忆任务时,会经历两个主要阶段:首先是参数形成阶段,模型将问题中的关键实体(如“法国”)提取出来,形成一个隐含的函数;其次是函数应用阶段,模型将提取出的实体转换为所需的答案(如“巴黎”)。这些发现为该研究提供了宝贵的基础,但仍有许多未解之谜,例如模型是如何从上下文中提取参数并传递给所谓的“函数”的,以及“函数应用”具体是如何与MLP层相关联的。

2. 语言模型在事实回忆中的关键阶段
在零次学习场景中,当给定一个提示如“The capital of France is”时,特定的注意力头会从上下文中提取出主题实体“France”,并将其传递给后续的MLP层以回忆出所需答案“Paris”。研究者引入了一种新颖的分析方法,旨在将MLP的输出分解为人类可理解的组成部分。通过这种方法,量化了MLP层在这些特定注意力头之后的功能。在残差流中,MLP层要么擦除要么放大来自单个的信息,并生成一个将残差流引向预期答案方向的组件。这些零次学习机制也被用于少次学习场景。此外,还观察到在模型的最后一层存在一种普遍的反过度自信机制,该机制会抑制正确的预测。研究者利用解释来改善事实回忆性能,减轻这种抑制。
研究方法
1. MLP输出的人类可理解分解方法
本研究提出了一种新颖的分析方法,用于理解某些深层MLP的行为。该方法揭示了一些MLP的行为类似于激活注意力头,同时也生成了一个负责“函数应用”的任务感知组件。这种分析方法的有效性得到了大量实证证据的支持。
2. 实验设计:从GPT-2到OPT-1.3B的模型范围
研究者研究了从GPT-2小型、中型和大型,到OPT-1.3B不同规模的Transformer基础语言模型。研究涉及两个事实回忆任务,涵盖了不同领域的知识。主要文本详细介绍了使用GPT-2小型模型进行的实验,该模型具有12层和每层12个头,使用的是国家-首都任务。
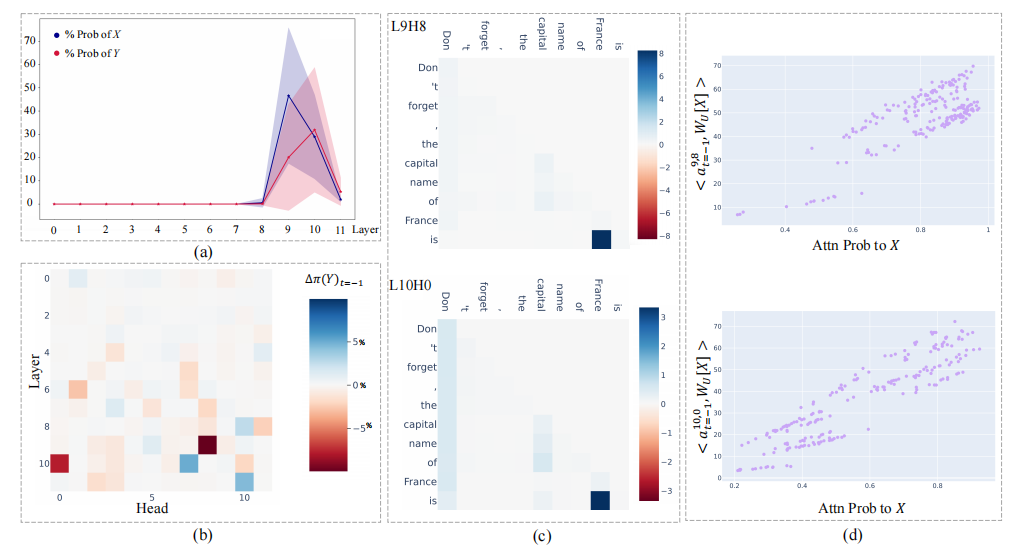
最终层的普遍反过度自信机制
1. 如何识别并缓解模型在最终层的自信抑制
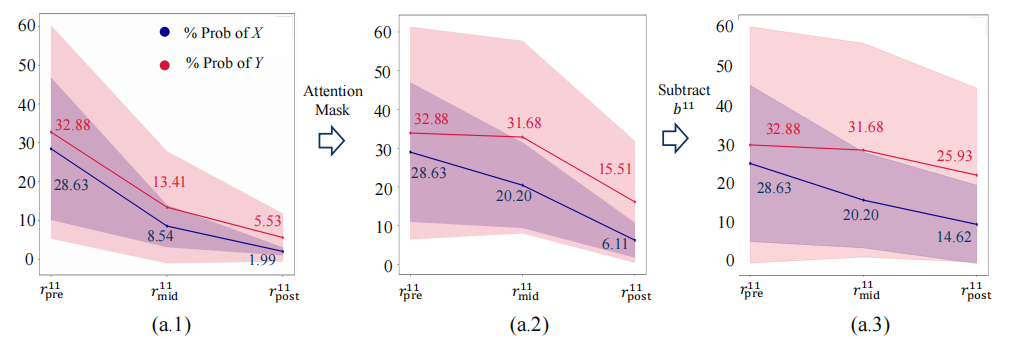
在最终层,无论是零次学习(zero-shot)还是少次学习(few-shot)场景,模型都倾向于通过其最后一层抑制正确的预测。这种抑制是通过整合频繁出现的词汇到残差流中,并利用MLP(多层感知机)将残差流引向训练语料库中的“平均”词汇来实现的。为了缓解这种抑制,采用了两种策略:一是应用注意力掩码,限制注意力头只关注最后的位置;二是从残差流中减去最终MLP层的截距。这些策略在不同的模型和任务中都得到了验证,有效提高了正确预测的概率。

2. 反过度自信机制的普遍性及其对预测的影响
这种反过度自信机制的普遍性表明,它并不依赖于特定的任务、模型或上下文演示的数量。这种机制可能是模型为了避免在错误预测时产生过分自信而导致的大量损失的一种防御策略。例如,在GPT-2小模型中,通过应用注意力掩码和减去截距的方法,能够将零次学习场景中正确预测的概率从15.51%提高到25.93%。这种策略的有效性在不同的模型和任务中得到了证实,为未来的研究提供了新的方向。
结论与展望
1. 研究总结
本研究深入探讨了Transformer基础的语言模型在事实回忆任务中所采用的机制。在零样本场景中,发现特定的注意力头部能够识别出与任务相关的实体,例如国家名称,并将其传递给后续的多层感知器(MLP),以回忆出所需的答案,如首都名称。研究者引入了一种新的分析方法,旨在将MLP的输出分解为人类可理解的组成部分。通过这种方法,量化了跟随这些任务特定头部的MLP层的功能,发现在残差流中要么抹除要么放大来自个别头部的信息,并生成一个将残差流引向预期答案方向的组件。
此外,观察到在模型的最后一层存在一种普遍的反过度自信机制,该机制通过注意力头部将频繁出现的词汇融入残差流,并利用MLP将残差流引向训练语料库中的“平均”词汇,从而抑制正确预测。
2. 未来研究方向
未来的研究可以在以下几个方向进行深入:
-
探索任务语义的构建:该研究没有深入探讨模型在浅层如何构建任务语义。未来研究可以探索多个电路路径如何协同工作以形成任务语义,以及如何应对电路发现方法中的协同电路路径挑战。
-
机制的起源研究:该研究还未探究这些机制的起源,例如MLP将残差流引向预期答案的行为似乎与Transformer架构中的残差连接有关。未来研究可以探讨模型如何使用最终层作为防御线来减轻过度自信带来的风险。
-
自动化MLP解释技术:该分析方法需要初步的人类推理。未来研究可以探索更自动化的MLP解释技术,这将是一个有前景的研究主题。
此外,该分析方法在解释MLP输出方面具有潜在的广泛应用,可以用于需要控制性的各种应用,如角色扮演、风格化对话和模型越狱等。未来的工作可以在这些领域进行深入研究,以进一步提高语言模型的可解释性和控制性。

















 31万+
31万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









