






随着多模态大语言模型(LLMs)的新发展,人们越来越关注如何将它们从图像-文本数据扩展到更具信息量的真实世界视频。与静态图像相比,视频为有效的大规模预训练带来了独特的挑战,因为需要对其时空动态进行建模。
针对视频与语言联合预训练的挑战,文章提出了高效的视频分解方法,将视频表示为关键帧和时间运动,并设计分词器适配LLM,实现视频、图像和文本的统一生成预训练。应用时,生成的标记被恢复为像素空间,用于创建视频内容。框架表现出对图像和视频内容的理解和生成能力,具有竞争力的性能。
分享几个网站
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
论文标题:
Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization
论文链接:
https://arxiv.org/pdf/2402.03161.pdf
项目链接:
https://video-lavit.github.io
视频理解的挑战:从静态图像到动态视频的转变
现有的多模态LLMs主要集中在图像-文本数据上,对于视频模态的适应性研究较少。视频理解的关键挑战在于如何有效地对视频的时空动态进行建模。传统的2D视觉编码器将视频帧单独编码,往往无法捕捉到视频内容中的时间运动信息,这些信息对于识别视频中的不同行为和事件至关重要。尽管最近的研究VideoPoet尝试通过3D视频编码器来处理视频生成,但其适用性受限于短视频片段,因为长序列的标记(例如,一个2.2秒的视频片段需要1280个标记)会导致计算资源的巨大消耗。
为了解决这些问题,本文提出了一种高效的视频表示方法,将视频分解为关键帧和时间运动,这种分解表示不仅减少了表示视频时空动态所需的标记数量,而且使模型能够继承现有图像LLM所学习的视觉知识,专注于建模时间信息,而无需从头开始学习。
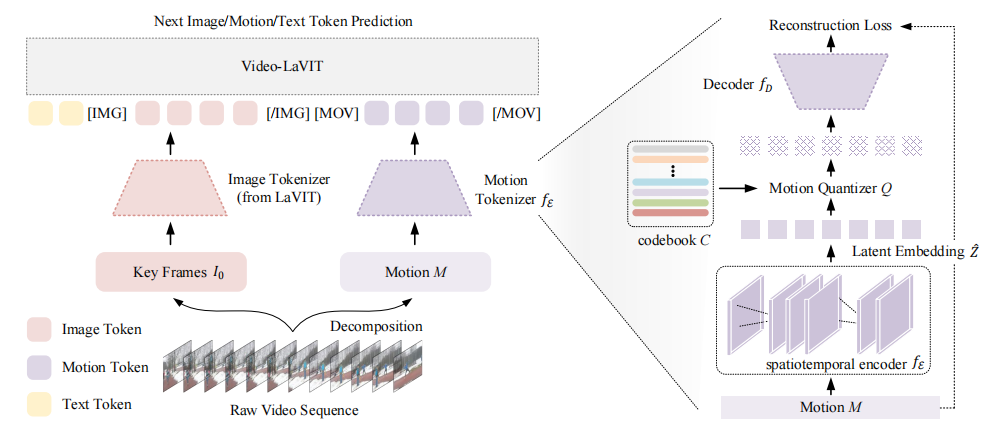
Video-LaVIT模型介绍
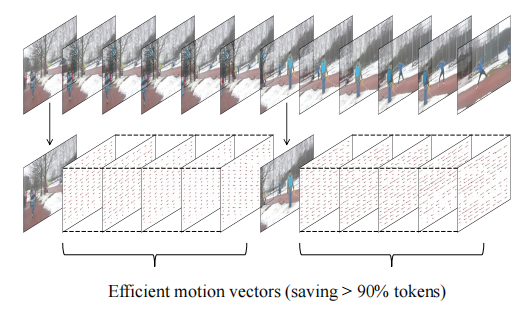
1. 视频分解:关键帧与运动向量的提取
Video-LaVIT模型的核心在于将视频分解为关键帧和时间运动。视频通常被分为多个镜头,每个镜头内的视频帧往往存在大量的信息冗余。因此,将视频分解为交替的关键帧和运动向量,关键帧捕捉主要的视觉语义,而运动向量描述其对应关键帧随时间的动态演变。这种分解表示的好处在于,与使用3D编码器处理连续视频帧相比,单个关键帧和运动向量的组合需要更少的标记来表示视频的时空动态,这对于大规模预训练更为高效。
2. 视频标记化:高效的视频内容表示
为了将连续的视频数据转换为紧凑的离散标记序列,Video-LaVIT设计了视频标记器。关键帧通过使用已建立的图像标记器进行处理,而时间运动的转换则通过设计一个时空运动编码器来实现。该编码器能够捕捉提取的运动向量中包含的随时间变化的上下文信息,从而显著提高LLMs理解视频中复杂动作的能力。
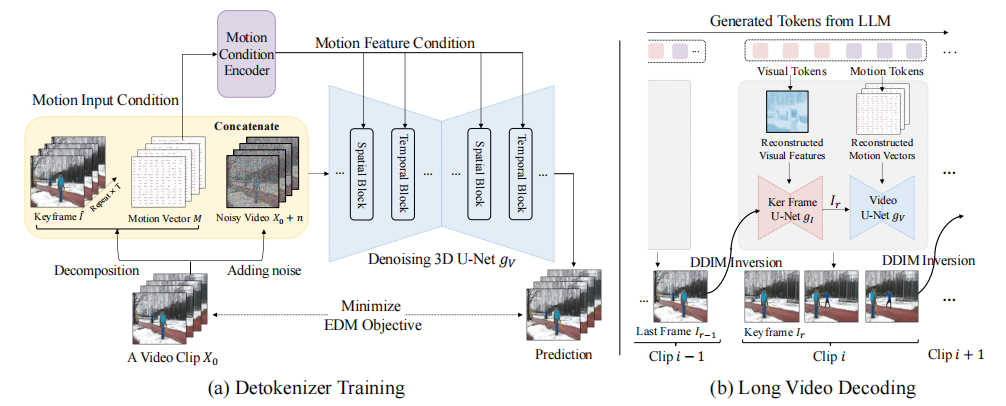
3. 视频去标记化:从离散标记到连续像素空间的映射
在推理阶段,LLMs生成的离散视频标记需要被精心恢复到原始的连续像素空间,以创建各种视频内容。Video-LaVIT的视频去标记器负责这一转换。考虑到直接从离散标记到高维视频空间的映射学习的挑战,采用了顺序解码策略,其中首先基于视觉标记恢复关键帧,然后通过将关键帧和运动标记作为条件来解码后续帧。这种策略在提高视频生成质量方面也得到了最近研究的验证。
多模态内容的联合自回归预训练
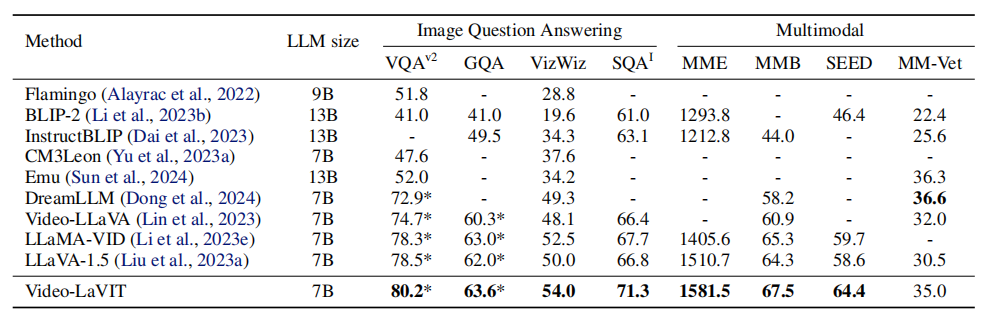
1. 图像理解任务的性能对比
在11个常用的图像和视频基准测试中,Video-LaVIT展示了其在多模态理解能力上的自然能力。特别是在图像理解方面,模型在八个广泛使用的图像问答和多模态基准测试中提供了最佳的整体性能。例如,在SQAI上,它比具有更高输入分辨率的LLaVA-1.5高出4.5%,同时在其他视频-语言模型上的表现也有超过3.5%的提升。这些优势在更全面的多模态基准测试中得到了进一步验证,其中该模型在四个基准测试中领先三个。
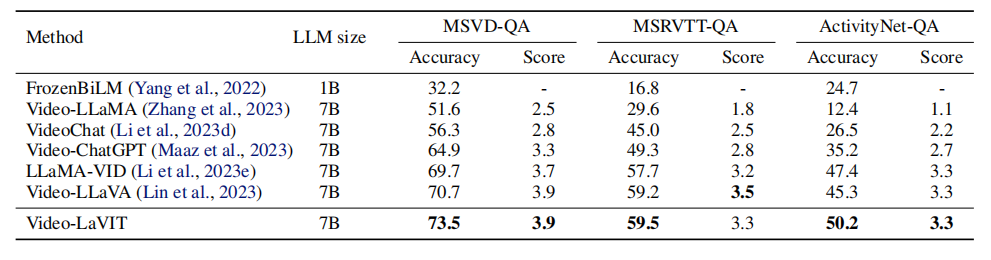
2. 零样本视频问答的准确性
在三个常见的视频基准测试中,Video-LaVIT与多个最近的视频-语言模型进行了比较。在这三个基准测试中实现了最先进的准确性,并都展示了非常有竞争力的相对分数。例如,在MSVD-QA上,该方法超过了之前领先的模型Video-LLaVA 2.8%。通过明确建模时间动态与运动标记,尤其是在包含各种人类行为的ActivityNet-QA基准测试中,纳入运动信息有助于识别不同的动作。在MSRVTT-QA的相对分数方面,仅次于Video-LLaVA(差距0.2),再次确认了该方法的有效性。
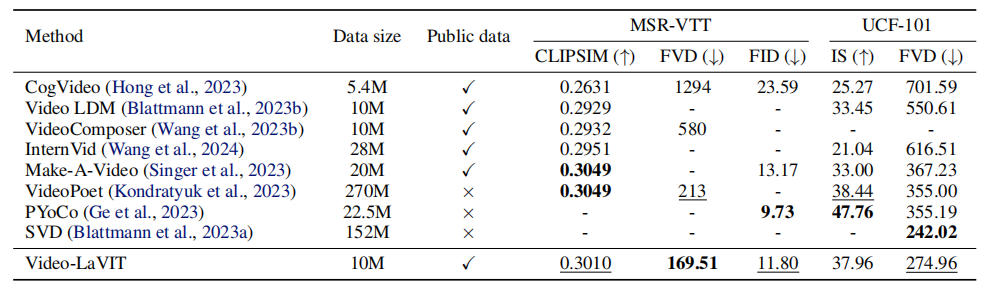
3. 文本到视频生成的竞争性能
通过统一的生成预训练,Video-LaVIT能够灵活地生成视频和图像。在文本到视频生成结果中,该模型在MSR-VTT和UCF-101上的表现显著优于大多数使用类似公共数据集训练的基线,并且与在更大专有数据上训练的模型高度竞争,例如在MSR-VTT上领先FVD。特别是与基于语言模型的文本到视频生成器相比,该方法一致超过CogVideo,同时超过了最近的同期工作VideoPoet,后者使用了更大的数据训练的3D视频分词器。这清楚地验证了分词器设计的优越性。

质量评估
1. 文本到图像生成的视觉质量
在图像理解方面,Video-LaVIT 在多个基准测试中表现出色。这一成果得益于其能够有效地利用从图像中学习到的视觉知识,并将其应用于视频内容的理解和生成。
2. 文本到视频生成的详细比较
在零样本视频问题回答方面,Video-LaVIT 在三个常用基准测试中均展现出最佳准确性。例如,使用GPT助手进行评估时,Video-LaVIT 在MSVD-QA基准测试中超越了之前领先的模型Video-LLaVA 2.8%的准确率。这一结果证明了Video-LaVIT 在理解视频内容方面的有效性。
3. 图像到视频生成的能力展示
在图像到视频的生成任务中,Video-LaVIT 展示了其强大的生成能力。通过将解耦的视觉-运动标记化和LLM预训练相结合,Video-LaVIT 能够生成具有自然和精细运动的视频片段。例如,在之前的研究中,与SVD的比较,Video-LaVIT 能够生成更复杂的动物运动,同时不违反物理规则。

4. 长视频生成的时间一致性
Video-LaVIT 通过在解码连续视频片段时明确约束噪声,能够在长视频生成中提供高度的时间一致性。例如,在生成一个围绕“一艘在加勒比海水晶般清澈的水面上优雅航行的豪华游艇”的360度视频时,通过使用噪声约束,Video-LaVIT 能够改善不同片段之间的时间一致性。

结论与展望
1. 模型潜力
Video-LaVIT的设计理念为未来的研究提供了新的方向:
-
通过对视频进行高效的分解和重新组合,该模型能够在保持高效性的同时,捕捉到视频内容的丰富动态信息。这一点对于提升机器对现实世界动态场景的理解至关重要。
-
该模型的成功也展示了大语言模型在多模态学习领域的巨大潜力,尤其是在处理更为复杂的视频数据时。
-
Video-LaVIT在无需特定任务微调的情况下,就能在多个基准测试中取得竞争性能,这进一步证明了其作为多模态通用模型的潜力。
2. 面临的挑战
尽管Video-LaVIT展现出了巨大的潜力,但在其发展道路上仍然存在一些挑战:
-
尽管通过视频分解能够有效减少模型处理的数据量,但对于极长视频的处理仍然是一个挑战,因为模型的上下文窗口大小有限。
-
运动向量的分辨率可能限制了模型在捕捉极其细微动作时的能力。此外,尽管Video-LaVIT在训练时的计算效率已经有所提高,但要将其扩展到网络规模的视频数据上,仍然需要进一步的优化。
-
如何进一步提升模型在理解和生成长视频内容时的连贯性和一致性,也是未来研究需要关注的问题。
Video-LaVIT的出现为多模态人工智能领域的发展注入了新的活力,预示着未来在更加自然和直观的人机交互方式方面的巨大潜力。随着技术的进步和研究的深入,Video-LaVIT及其后续版本将在多模态人工智能领域扮演越来越重要的角色。
















 31万+
31万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









