








import re
# socket--->
import urllib
import time
url = 'https://tieba.baidu.com/p/5631230268'
def getHtml(url):
# urllib.urlopen打开指定的网络链接;
page = urllib.urlopen(url)
# read()查看网页的内容;
html = page.read()
return html
def getImg(html):
reg = r'src="(.+?\.jpg)"'
imglist = re.findall(reg, html)
for index,imgurl in enumerate(imglist):
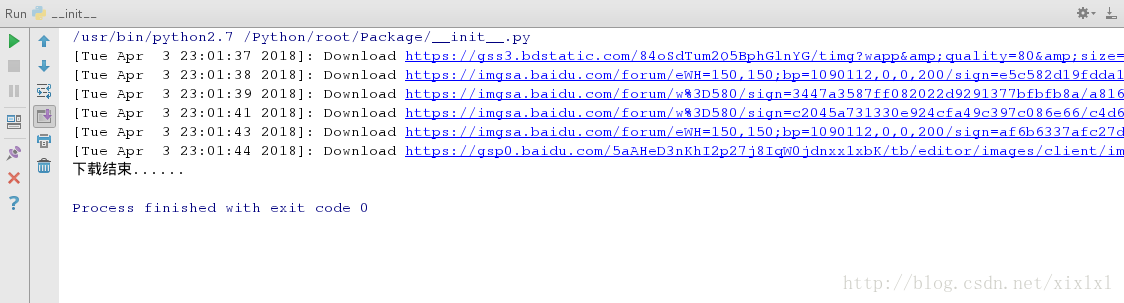
print "[%s]: Download %s ......." %(time.ctime(), imgurl)
# urlretrieve下载指定的图片文件到本地;
urllib.urlretrieve(imgurl, '/home/kiosk/Music/picture%.3d.jpg' %(index+1))
if index == 5:
print "下载结束......"
break
html = getHtml(url)
getImg(html)














 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









