






一、存储引擎
为什么叫`引擎`呢?因为这个名字更拉风~ 其实这个存储引擎以前叫做`表处理器`,后来可能人们觉 得太土,就改成了`存储引擎`的叫法,它的功能就是接收上层传下来的指令,然后对表中的数据进行提 取或写入操作。
二、MySQL中字符集的转换
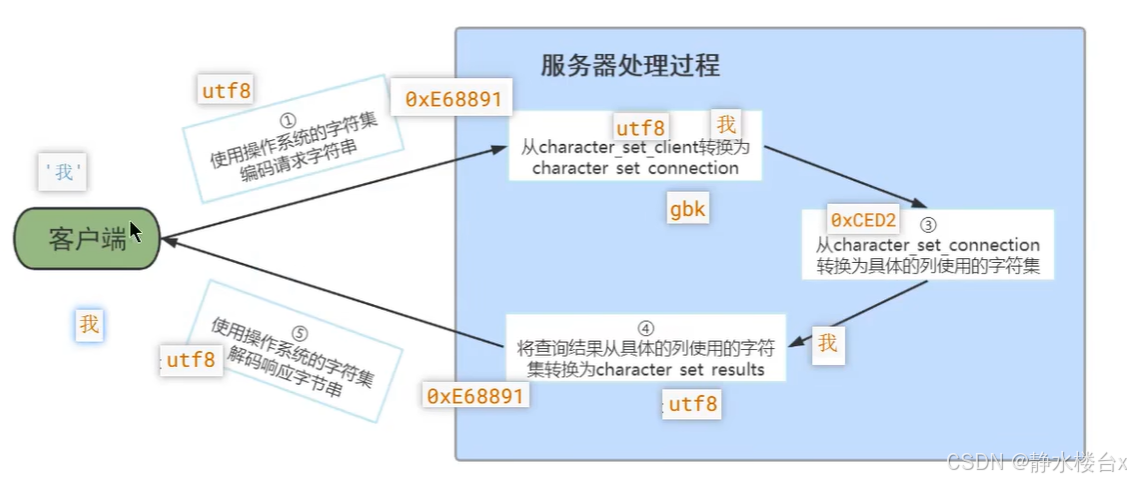
我们知道从客户端发往服务器的请求本质上就是一个字符串,服务器向客户端返回的结果本质上也是一个字符 串,而字符串其实是使用某种字符集编码的二进制数据。这个字符串可不是使用一种字符集的编码方式一条道走 到黑的,从发送请求到返回结果这个过程中伴随着多次字符集的转换,在这个过程中会用到3个系统变量。

转换过程:
现在假设我们客户端发送的请求是下边这个字符串: SELECT * FROM t WHERE s = '我';为了方便大家理解这个过程,我们只分析字符 '我' 在这个过程中字符集的转换(实际上 SELECT * FROM t WHERE s = '我' 这一串字符串都会进行字符集转换)。
三、B+树索引
1、B+树非叶子结点中的key存储的是什么?
B+树非叶子结点中的key存储的是页的用户记录中最小/最大的主键值,之前不知道非叶子结点中的key存的是最小/最大,以为随便存的一个。
2、为什么懵逼?
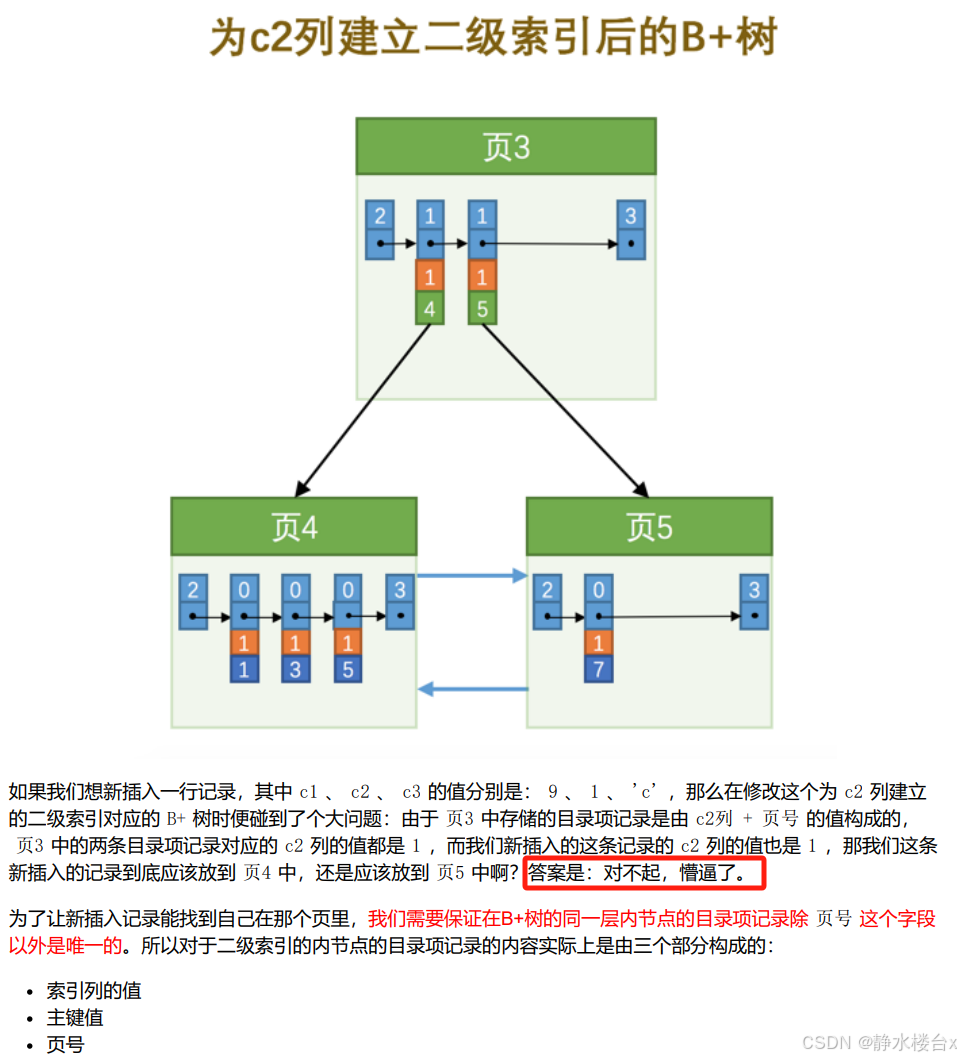
二级索引为什么要指定主键值,因为 人为看来(9,1,'c')可以存到页5代价更小,但是程序如果要做到的话代价太大,所以我们指定了一种规则,为目录项增加了主键值确保唯一性。
3、联合索引的查找过程
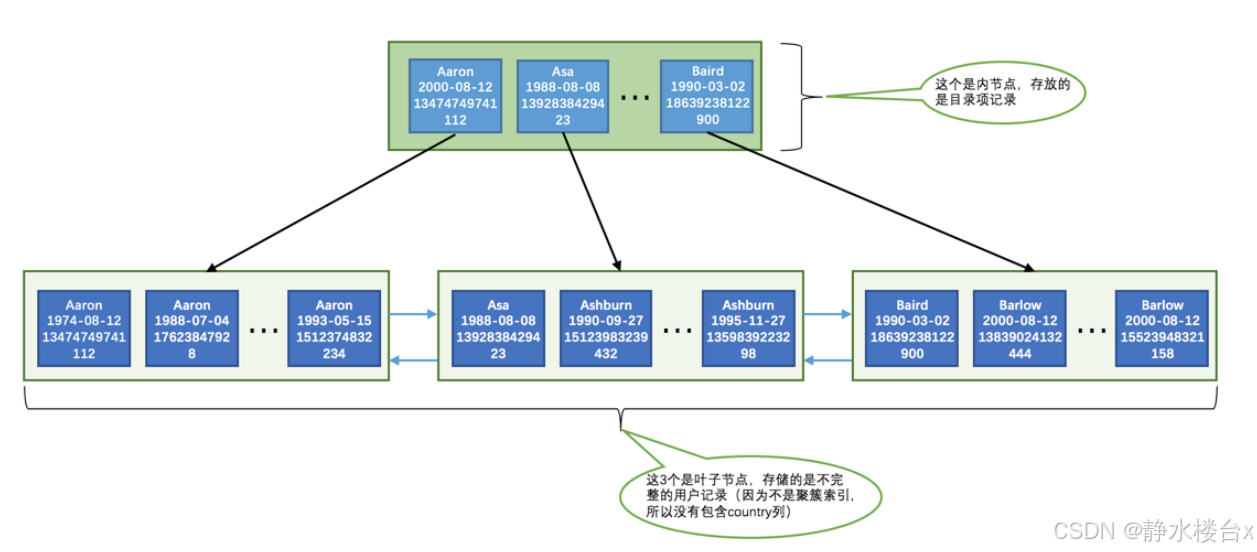
全值匹配查找过程:

【注意】非叶子节点:在查找过程中,非叶子节点只会比较 name 列的值,以定位到合适的子节点。叶子节点:在叶子节点中,MySQL 会依次比较 name、birthday 和 phone_number 列的值,以找到精确匹配的记录。非叶子结点中存储三个列的原因猜测是为了插入时方便比较。
4、为什么记录之间用单链表?
插入删除效率、内存占用等方面。
5、mysql范围查询
如果对多个列都进行范围查询,只有对索引最左边的那个列索引才生效。
比如:SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow' AND birthday > '1980-01-01';
只有name相同的情况下birthday才有序,name不同birthday无序,比如(Asbbb,'1998-10-01')-->(Baaaa,'1997-10-01'),birthday是无序的,所以birthday需要回表进行一一比较(不考虑索引下推的情况下)。若考虑索引下推,则在索引扫描过程中,MySQL 先通过索引查询出name > 'Asa' AND name < 'Barlow'的所有记录,然后在这些记录中检查 birthday > '1980-01-01' 这个条件,只有满足条件的记录才会进行回表操作,由于很多不符合 birthday > '1980-01-01' 的记录在索引扫描阶段就被过滤掉,回表操作大幅减少,查询性能提升。

参考文章:https://baijiahao.baidu.com/s?id=1693718883799963534
6、匹配列前缀
SELECT * FROM person_info WHERE name LIKE '%As%'; MySQL 就无法快速定位记录位置了,因为字符串中间有 'As' 的字符串并没有排好序,所以只能全表扫描了,比如AAsc,BAa,BAsa,BBc,BCc,BDc,BF,CAsZ,CC,CD,CZ,DA,....,ZAsZ,可以看到包含'As'的字符串并没有排好序。因此需要全表扫描。
7、顺序I/O怎么理解?
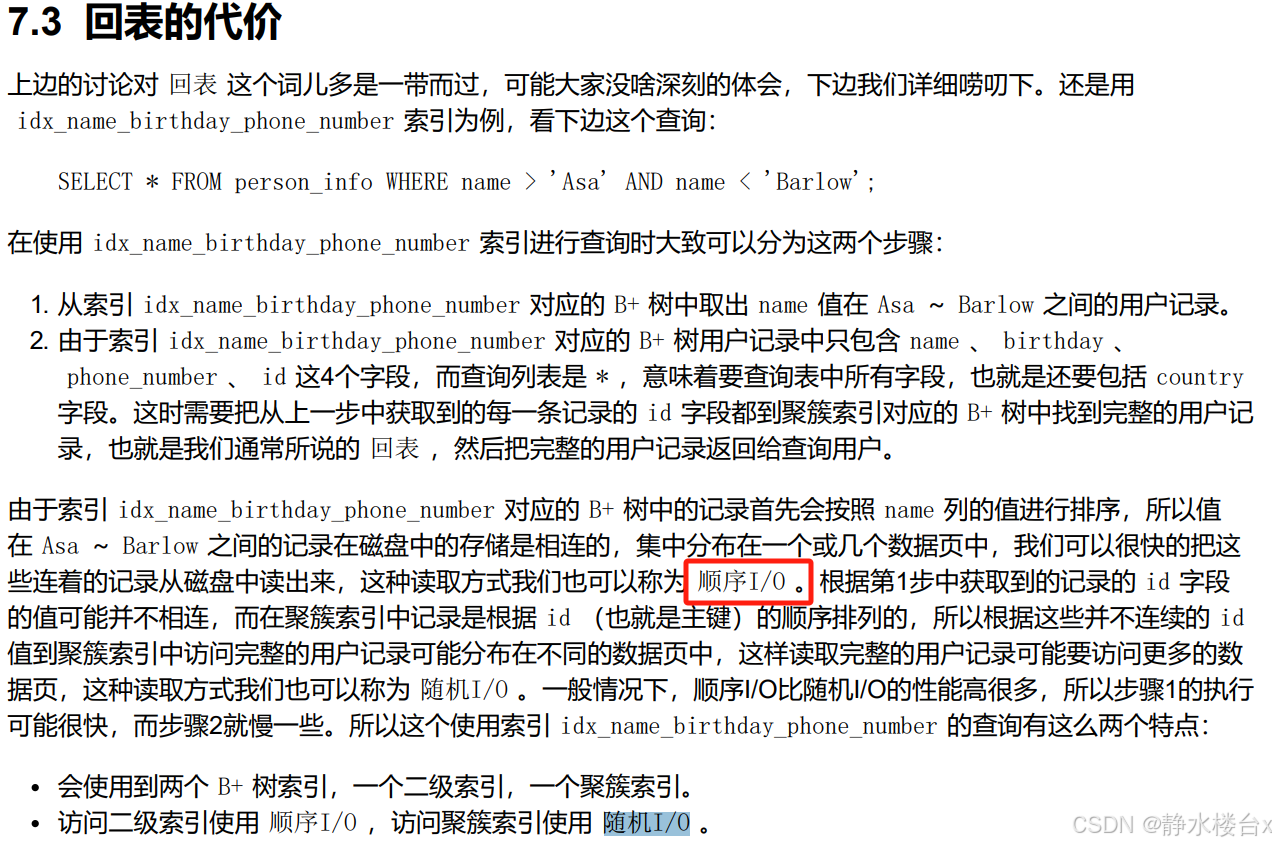
Asa ~ Barlow 之间的记录在磁盘中的存储是相连的,怎么理解?正常来讲,如果只用页来存储数据的话,页之间不一定是物理相连的,但是我们引入区(extent)之后,其实在物理位置上就是相连的了。
四、innodb的表空间
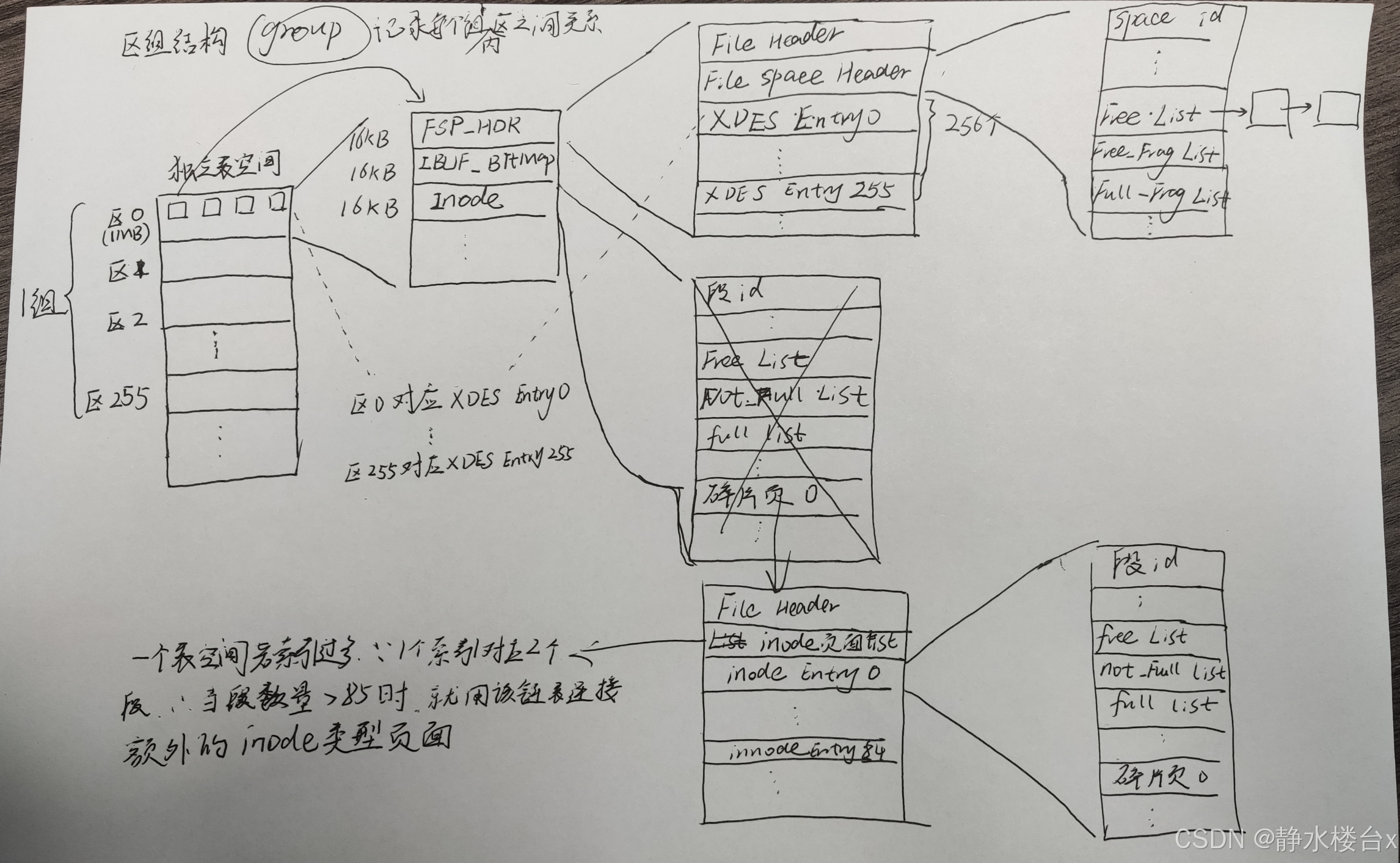
每个独立表空间中的各个组,是由区组结构来管理的,每个区对应一个XDES Entry,每个段对应一个INODE Entry,一个索引会产生两个段,分别是叶子节点段和非叶子节点段。
这两篇文章写的不错:
【mysql】4-2. MySQL存储结构_mysql 表空间-CSDN博客
MySQL存储结构(磁盘) - zzzzzzzk - 博客园
五、单表访问方法
1、全表扫描怎么理解?
对于 InnoDB 表来说也就是直接扫描聚簇索引。从根页面找到聚簇索引对应的叶子节点段,开始扫描。
2、索引合并

根据二级索引查询出的结果集是按照主键值排序的对使用 Intersection 索引合并有啥好处?可以减少求交集的时间,另外如果二级索引查询出的结果集是按照主键排序的,在回表过程中可以按照一定顺序扫描磁盘。
六、两个表连接的原理
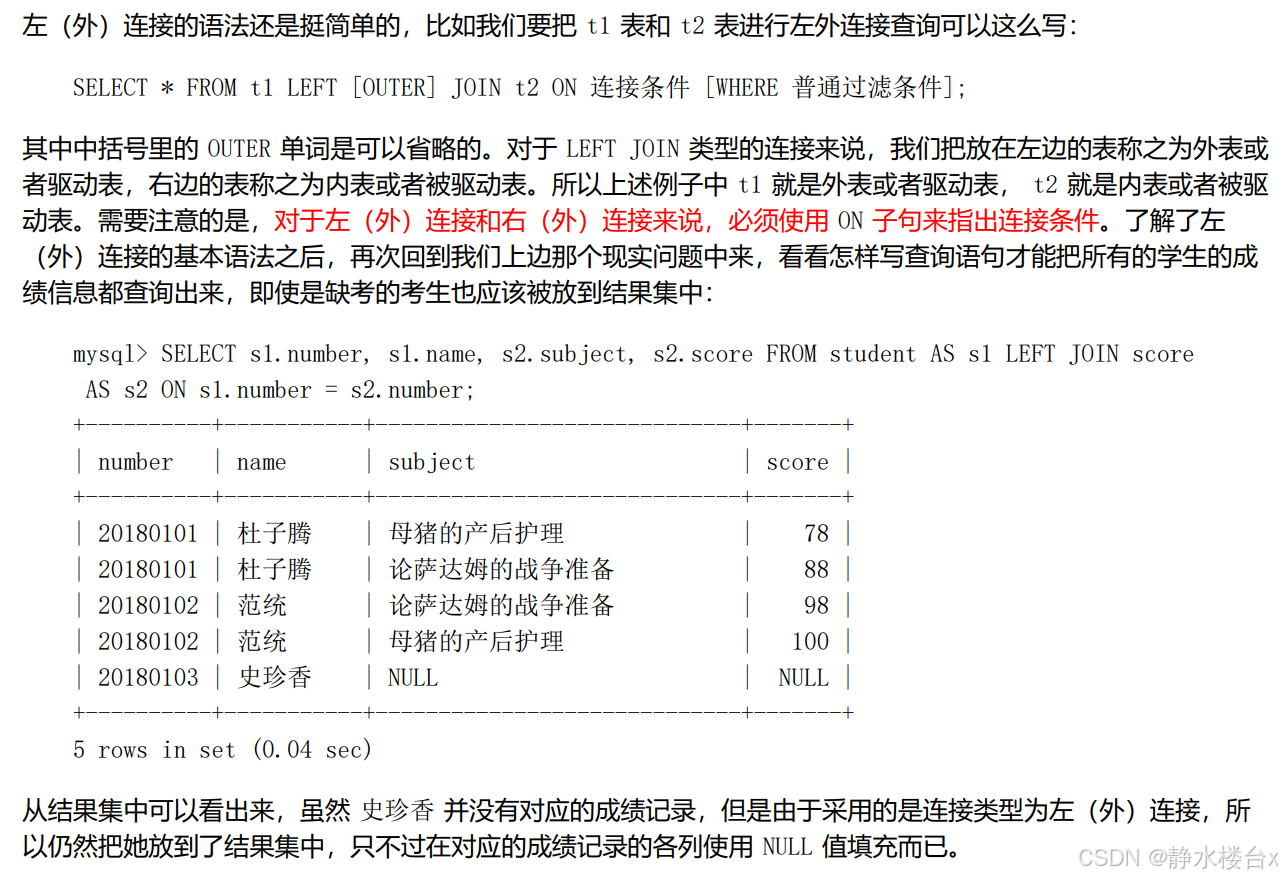
1、外连接和内连接
对于外连接来说,on和where是有区别的。where条件不论是内连接还是外连接,凡是不符合 where子句中的过滤条件的记录都不会被加入最后的结果集。on对于外连接来说,如果无法在被驱动表中找到匹配 ON 子句中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用 NULL 值填充。也就是说,on和where的区别就是要不要把驱动表没有匹配到的记录加入到结果集。
例子一:
例子二:

连接过程是这样的,先查询course表,因为没有where条件,所以查询course表全部记录,接下来是这么进行的:
(1)course表第一条记录(1,'语文',1),开始匹配teacher每一条记录,匹配条件t.t_id = 1 and c.c_id < 3,匹配到(1,'王老师'),组成一条记录(1,'语文',1,1,'王老师');
(2)course表第二条记录(2,'数学',2),开始匹配teacher每一条记录,匹配条件t.t_id = 2 and c.c_id < 3,匹配到(2,'李老师'),组成一条记录(2,'数学',2,2,'李老师');
(3)course表第三条记录(3,'英语',3),开始匹配teacher每一条记录,匹配条件t.t_id = 3 and c.c_id < 3,没有匹配的,将(3,'英语',3,NULL,NULL)加入到结果集,匹配机制必须是两张表两个条件都满足;
(4)course表第四条记录(4,'化学',5),开始匹配teacher每一条记录,匹配条件t.t_id = 5 and c.c_id < 3,没有匹配的,将(4,'化学',5,NULL,NULL)加入到结果集。
参考gpt:

七、 子查询在mysql中是怎么执行的
1、对于不相关子查询来说,可以尝试把它们物化之后再参与查询
1、比如我们上边提到的这个查询: SELECT * FROM s1 WHERE key1 NOT IN (SELECT common_field FROM s2 WHERE key3 = 'a') 先将子查询物化,然后再判断 key1 是否在物化表的结果集中可以加快查询执行的速度。
小贴士: 请注意这里将子查询物化之后不能转为和外层查询的表的连接,只能是先扫描s1表(注意子查询已经先执行了),然后对s1表 的某条记录来说,判断该记录的key1值在不在物化表中。
我的疑问是:
(1)为什么不能是先扫描物化表,然后对物化表的每条记录来说,如果能在 s1 表 中找到对应的 key1 列的值与该值 不相等 的记录,那么就把这些记录加入到最终的结果集?
解:比如物化表结果为1 3 4,s1表key1有1 2,正确结果应该是2。如果是先扫描物化表,比如对于物化表第一条记录1,1=1,3 != 1和2,4!= 1和2,则会将1 2加入结果集,结果是错误的。相反,如果这样理解:先扫描s1表,然后对s1表 的某条记录来说,判断该记录的key1值在不在物化表中,对于s1表第一条记录1,在物化表中,pass,对于s1表第二条记录2,不在物化表中,加入结果集,最终结果是2,所以这种理解是对的。因次where中的in子查询(不相关)正确的理解是:先执行子查询,再执行外层查询。
《mysql是怎样运行的》这本书205页讲了in子查询的两种角度,第二种角度是正确的,第一种角度有特殊情况,就是物化表是否有重复记录,如果有重复记录,那么就会把结果重复加入结果集。因此不能简单的直接将in子查询转为连接查询。
《mysql是怎样运行的》这本书205页讲了in子查询的两种角度,都是正确的,因为物化表已经去重了。
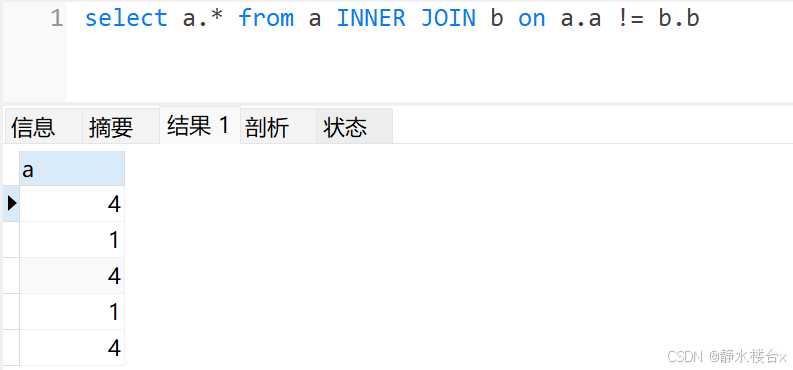
(2)为什么不能将子查询转换为和外层查询表的连接?比如转为on xx != yy?
解:not in的逻辑取的是in的补集,我错误的想法是为什么not in不能通过指定条件on a.a != b.b转换为内连接,因为这样逻辑就错了,比如:有表a(1) (4),b(1)(2)(3),执行select * from a inner join b是笛卡尔积,如下

加上on a.a != b.b结果是不对的,因此不能将not in转换为连接。
2、对于一些不能将子查询转位 semi-join 的情况,典型的比如下边这几种: 外层查询的WHERE条件中有其他搜索条件与IN子查询组成的布尔表达式使用 OR 连接起来 SELECT * FROM s1 WHERE key1 IN (SELECT common_field FROM s2 WHERE key3 = 'a') OR key2 > 100; 是为什么?
假设有以下数据:
-
表
s1:key1 key2 1 50 2 150 3 200 -
表
s2:common_field key3 1 'a' 3 'b'
sql
SELECT * FROM s1
WHERE key1 IN (SELECT common_field FROM s2 WHERE key3 = 'a')
OR key2 > 100;- 返回行:
key1=1(满足子查询)、key2=150、key2=200(满足key2 > 100)
改写后的半连接查询结果:
sql
SELECT s1.*
FROM s1
SEMI JOIN s2
ON (s1.key1 = s2.common_field AND s2.key3 = 'a')
OR s1.key2 > 100;- 返回行:
key1=1(满足ON的子查询条件);key2=150(满足s1.key2 > 100);key2=200(满足s1.key2 > 100)。
-
看似结果相同,但这是巧合! 如果
s2为空表,结果会完全不同: - 原查询:仍会返回
key2=150和key2=200(因为OR的第二个条件独立于子查询); - 改写后的查询:返回空集(因为
SEMI JOIN要求s2表不为空,而s2为空表时无法满足OR的任何条件)。
八、buffer pool
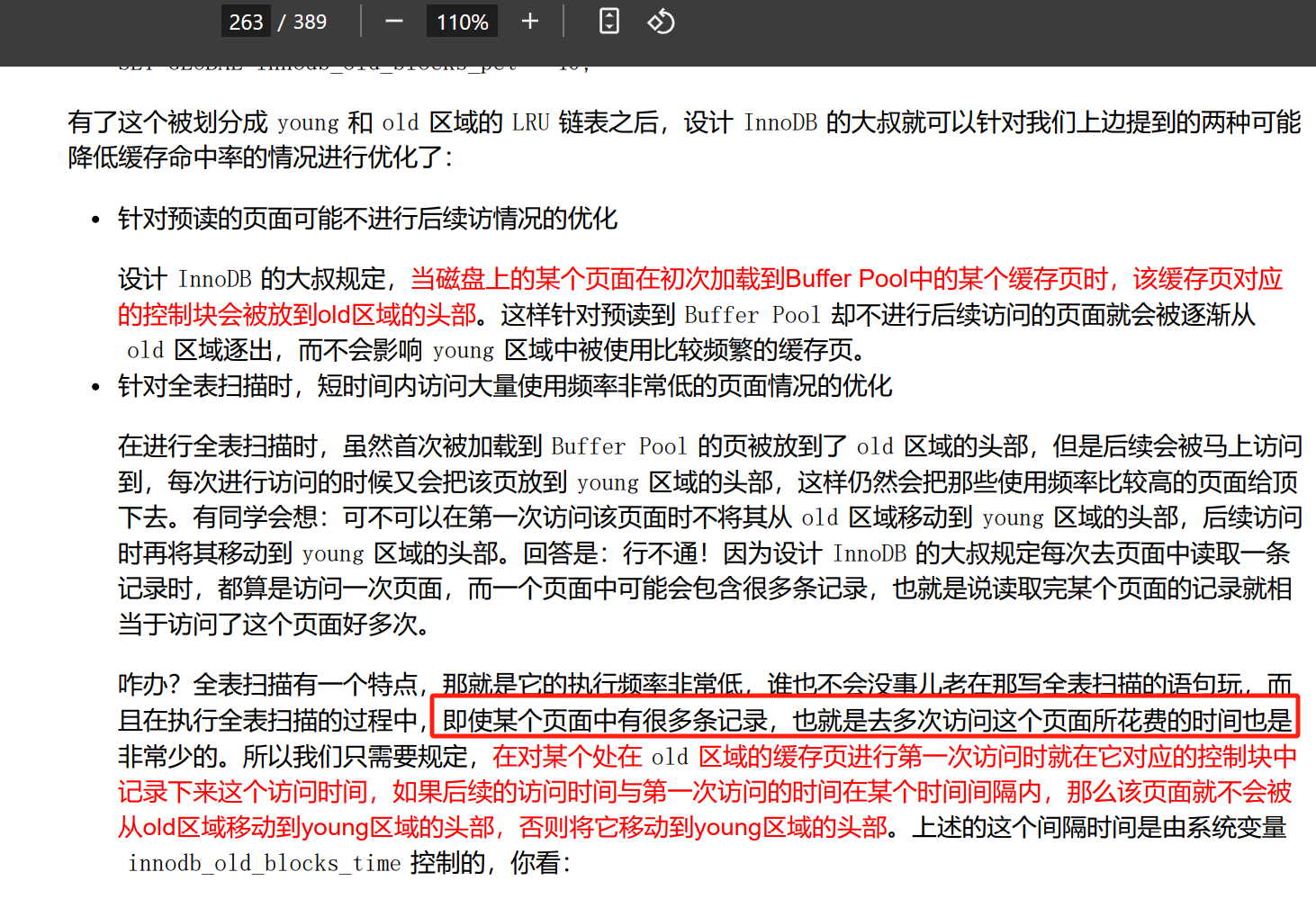
1、即使某个页面中有很多条记录,也就是去多次访问这个页面所花费的时间也是 非常少的?意思是这个页面已经在缓存页了,所以很快。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









