






原创 victory54610 Python SQL审天下 2024-01-22 05:24 发表于陕西
在MySQL数据库中,GROUP BY是一个强大的工具,用于对查询结果进行分组。然而,在使用GROUP BY时,有一些常见的坑可能会导致结果不符合预期。在本文中,我们将探讨一些常见的GROUP BY陷阱,并提供相应的解决方法。
测试数据:
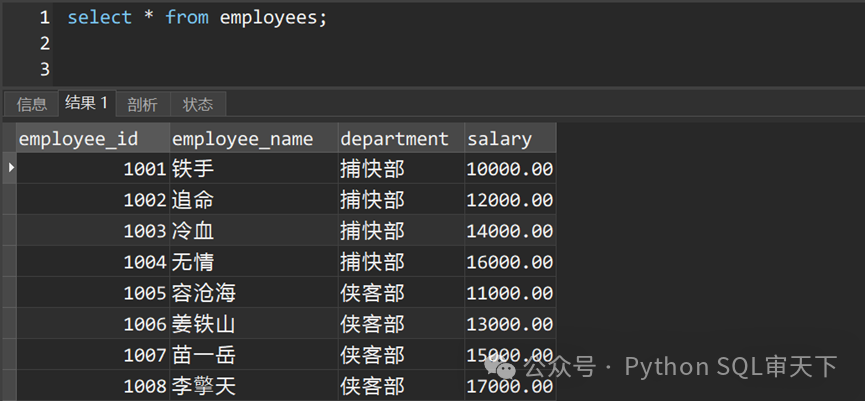
坑之一:选择列表中的非聚合列
在使用GROUP BY时,SELECT语句中的列必须要么是聚合函数的结果,要么在GROUP BY子句中列出。如果选择了不在这两者之一的列,MySQL将无法确定应该返回哪个值,可能会返回随机的值或者是第一个匹配的值。
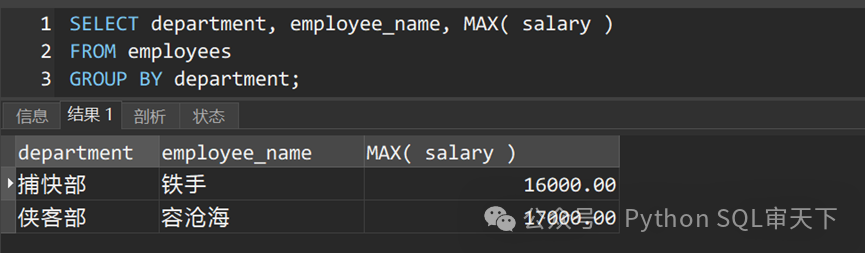
在上面的例子中,employee_name列没有被包含在聚合函数中,也没有在GROUP BY子句中列出,导致返回的employee_name并非每个部门的最大工资对应的员工。如本例中捕快部工资最高的员工应该是“无情”,侠客部工资最高的员工应该是“李擎天”。
要解决这个问题,确保SELECT语句中的列要么是聚合函数的结果,要么在GROUP BY子句中列出。如果需要获取最大工资对应的员工,可以使用子查询或者窗口函数。
坑之二:HAVING子句使用错误
HAVING子句用于在GROUP BY之后过滤结果,类似于WHERE子句。然而,由于其位置在GROUP BY之后,需要注意它对聚合结果的过滤。
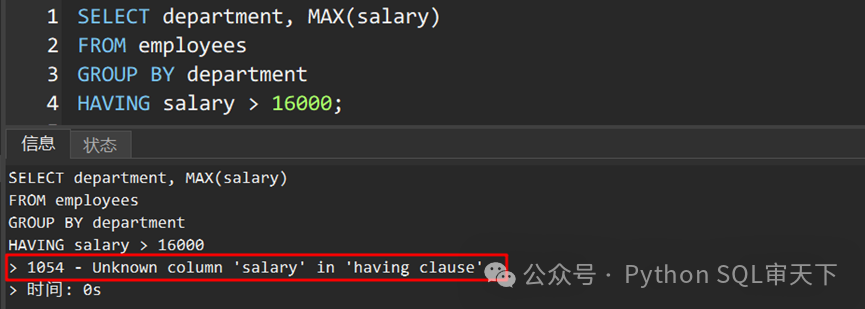
在上面的例子中,尽管看起来似乎可以使用HAVING子句过滤工资大于16000的部门,但实际上这是错误的。HAVING子句中应使用聚合函数。
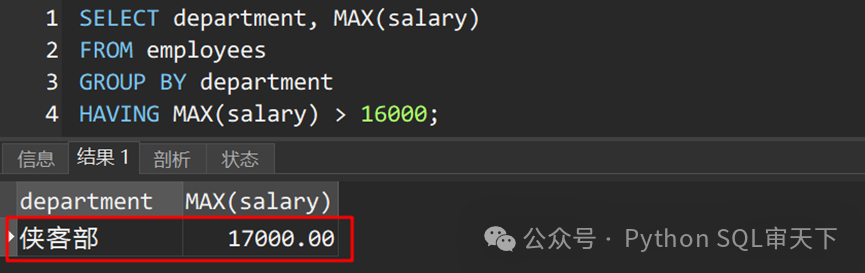
坑之三:GROUP BY的列顺序问题
在GROUP BY子句中,列的顺序并不重要,但在SELECT语句中,列的顺序会影响结果的显示顺序。如果不注意这一点,会导致结果与预期不符。
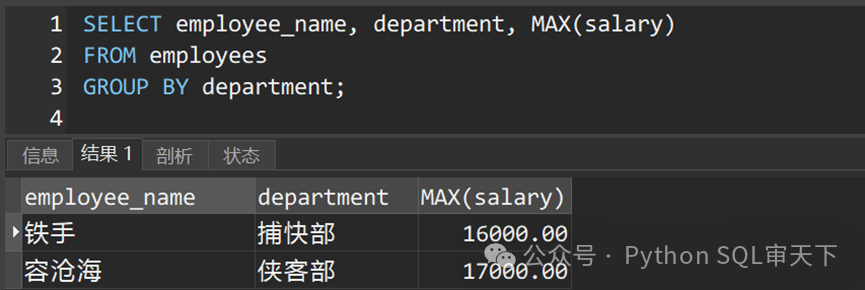
在上面的例子中,实际上有两个坑,一个是坑一中所说的,另外由于SELECT语句中列的顺序与GROUP BY子句中的不同,导致结果与预期不一致。
因此为避免这个问题发生,应确保SELECT语句中的列顺序与GROUP BY子句中的列顺序一致,或者使用列的别名来明确指定显示顺序。
今天的分享就到这儿啦,非常感谢您对“Python SQL审天下”公众号的关注和点赞。如果您觉得我的公众号能给您带来一丝丝的收获,请多多转发给您的朋友圈,让更多的人看到并了解。也许您不经意间的点赞和转发,会给他人带来独特的体验和感受。














 54
54











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









