







一、大体结构

二、Header
Header的大小固定为0x70
Magic[8]:8字节
checksum:4字节,文件校验码,校验文件除去maigc ,checksum 外余下的所有文件区域 ,用于检查文件错误 。
Signature[20]:20字节,使用 SHA-1 算法 hash 除去 magic ,checksum 和 signature 外余下的所有文件区域 ,用于唯一识别本文件 。
file_size:4字节
header_size:4字节
endan_tag:4字节,大小端
link_size:4字节,链接数据的大小
link_off:4字节,链接数据的偏移值
map_off:map item 的偏移地址 ,该 item 属于 data 区里的内容 ,值要大于等于 data_off 的大小 。结构如map_list 描述 :
package com.wjdiankong.parsedex.struct;
import java.util.ArrayList;
import java.util.List;
public class MapList {
public int size;
public List<MapItem> map_item = new ArrayList<MapItem>();
} 定义位置 : data区
引用位置 :header 区 。
package com.wjdiankong.parsedex.struct;
public class MapItem {
public short type; //该map_item 的类型
public short unuse; //用对齐字节的 ,无实际用处
public int size; // 表示再细分此 item , 该类型的个数
public int offset; //offset 是第一个元
素的针对文件初始位置的偏移量
public static int getSize(){
return 2 + 2 + 4 + 4;
}
@Override
public String toString(){
return "type:"+type+",unuse:"+unuse+",size:"+size+",offset:"+offset;
}
} header->map_off = 0x0244 , 偏移为 0244 的位置值为 0x 000d 。
每个 map_item 描述占用 12 Byte , 整个 map_list 占用 12 * size + 4 个字节 。所以整个 map_list 占用空间为 12 * 13 + 4 = 160 =0x00a0 , 占用空间为 0x 0244 ~ 0x 02E3 。从文件内容上看 ,也是从 0x 0244到文件结束的位置 。
**注意:**map_item大小+map_item_list+4文件就结束了?!

地址 0x0244 的一个 uinit 的值为 0x0000 000d ,map_list - > size = 0x0d = 13 ,说明后续有 13 个
map_item 。根据 map_item 的结构描述在0x0248 ~ 0x02e3 里的值 ,整理出这段二进制所表示的 13 个
map_item 内容 ,汇成表格如下 :
至此 , header 部分描述完毕 ,它包括描述 .dex 文件的信息 ,其余各索引区和 data 区的偏移信息 , 一个map_list 结构 。map_list 里除了对索引区和数据区的偏移地址又一次描述 ,也有其它诸如HEAD_ITEM ,DEBUG_INFO_ITEM 等信息 。
二、索引区
1、 string_ids_size和string_ids_off
这两个字段表示dex中用到的所有的字符串内容的大小和偏移值,我们需要解析完这部分,然后用一个字符串池存起来,后面有其他的数据结构会用索引值来访问字符串,这个池子也是非常重要的。后面会详细介绍string_ids的数据结构
本区里的元素格式为string_ids_item
public class StringIdsItem {
public int string_data_off;
public static int getSize(){
return 4;
}
@Override
public String toString(){
return Utils.bytesToHexString(Utils.int2Byte(string_data_off));
}
} 以 _ids 结尾的各个 section 里放置的都是对应数据的偏移地址 ,只是一个索引 ,所以才会在 dex文件布局里把这些区归类为 “索引区” 。
string_data_off 只是一个偏移地址 ,它指向的数据结构为string_data_item
public class StringDataItem {
public List<Byte> utf16_size = new ArrayList<Byte>();
public byte data;
} 注意:
LEB128是基于1个Byte的一种不定长度的编码方式。若第一个Byte的最高位为1,则表示还需要下一个Byte来描述,直至最后一个Byte的最高位为0。
将leb128编码的数字转换为可读数字的规则是:除去每个字节的bit7,将每个字节剩余的7个bits拼接在一起,即为数字。
转换过程:
0x02b0 => 0000 0010 1011 0000 =>去除最高位=> 000 0010 011 0000 =>按4bits重排 => 00 0001 0011 0000 => 0x130
底层代码位于:android/dalvik/libdex/leb128.h
Java中也写了一个工具类:
public static byte[] readUnsignedLeb128(byte[] srcByte, int offset){
List<Byte> byteAryList = new ArrayList<Byte>();
byte bytes = Utils.copyByte(srcByte, offset, 1)[0];
byte highBit = (byte)(bytes & 0x80);
byteAryList.add(bytes);
offset ++;
while(highBit != 0){
bytes = Utils.copyByte(srcByte, offset, 1)[0];
highBit = (byte)(bytes & 0x80);
offset ++;
byteAryList.add(bytes);
}
byte[] byteAry = new byte[byteAryList.size()];
for(int j=0;j<byteAryList.size();j++){
byteAry[j] = byteAryList.get(j);
}
return byteAry;
} 这个方法是读取dex中uleb128类型的数据,遇到一个字节最高位=0就停止读下个字节的原理来实现即可
还有一个方法就是解码uleb128类型的数据:
public static int decodeUleb128(byte[] byteAry) {
int index = 0, cur;
int result = byteAry[index];
index++;
if(byteAry.length == 1){
return result;
}
if(byteAry.length == 2){
cur = byteAry[index];
index++;
result = (result & 0x7f) | ((cur & 0x7f) << 7);
return result;
}
if(byteAry.length == 3){
cur = byteAry[index];
index++;
result |= (cur & 0x7f) << 14;
return result;
}
if(byteAry.length == 4){
cur = byteAry[index];
index++;
result |= (cur & 0x7f) << 21;
return result;
}
if(byteAry.length == 5){
cur = byteAry[index];
index++;
result |= cur << 28;
return result;
}
return result;
}这个原理很简单,就是去除每个字节的最高位,然后拼接剩下的7位,然后从新构造一个int类型的数据,位不够就从低位开始左移。
我们通过上面的uleb128的解释来看,其实uleb128类型就是1~5个字节来回浮动,为什么是5呢?因为他要表示一个4个字节的int类型,但是每个字节要去除最高位,那么肯定最多只需要5个字节就可以表示4个字节的int类型数据了。
根据 string_ids_item 和 string_data_item 的描述 ,加上 header 里提供的入口位置 string_ids_size
= 0x0e , string_ids_off = 0x70 ,我们可以整理出 string_ids 及其对应的数据如下 :
注意:
由header中信息获得string的偏移和个数;
由string_ids_item得到string_data_item位置;
由string_data_item开始的utf16(一个字节)是字符串中字符的个数;
string_ids_item 和 string_data_item 里提取出的对应数据表格 :
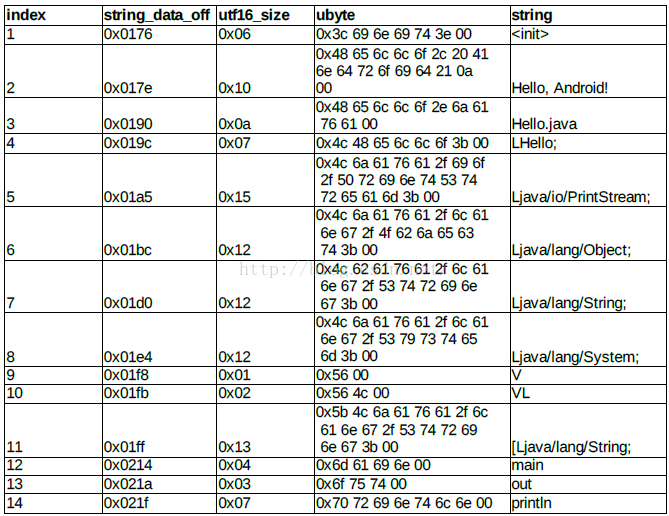
我们用一个字符串池来进行存储即可。下面我们来继续看type_ids数据结构。
2、 type_ids_size和type_ids_off
这两个字段表示dex中的类型数据结构的大小和偏移值,比如类类型,基本类型等信息,后面会详细介绍type_ids的数据结构。
public class TypeIdsItem {
public int descriptor_idx;
public static int getSize(){
return 4;
}
@Override
public String toString(){
return Utils.bytesToHexString(Utils.int2Byte(descriptor_idx));
}
}type_ids_item 里面 descriptor_idx 的值的意思 ,是 string_ids 里的 index 序号 ,是用来描述此type 的字符串 。
根据 header 里 type_ids_size = 0x07 , type_ids_off = 0xa8 , 找到对应的二进制描述区 。00000a0: 1a02

根据 type_id_item 的描述 ,整理出表格如下 。因为 type_id_item - > descriptor_idx 里存放的是指向 string_ids 的 index 号 ,所以我们也能得到该 type 的字符串描述 。这里出现了 3 个 type descriptor :
L 表示 class 的详细描述 ,一般以分号表示 class 描述结束 ;
V 表示 void 返回类型 ,只有在返回值的时候有效 ;
[ 表示数组 ,[Ljava/lang/String; 可以对应到 java 语言里的 java.lang.String[] 类型 。
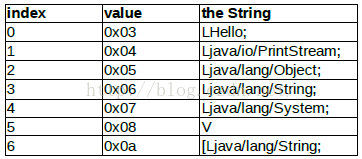
我们后面的其他数据结构也会使用到type_ids类型,所以我们这里解析完type_ids也是需要用一个池子来存放的,后面直接用索引index来访问即可。
3、proto_ids_size和type_ids_off
proto 的意思是 method prototype 代表 java 语言里的一个 method 的原型 。proto_ids 里的元素为 proto_id_item , 结构如下 。
public class ProtoIdsItem {
public int shorty_idx;
public int return_type_idx;
public int parameters_off;
public List<String> parametersList = new ArrayList<String>();
public int parameterCount;
public static int getSize(){
return 4 + 4 + 4;
}
@Override
public String toString(){
return "shorty_idx:"+shorty_idx+",return_type_idx:"+return_type_idx+",parameters_off:"+parameters_off;
}
}shorty_idx :跟 type_ids 一样 ,它的值是一个 string_ids 的 index 号 ,最终是一个简短的字符串描述 ,用来说明该 method 原型 。
return_type_idx :它的值是一个 type_ids 的 index 号 ,表示该 method 原型的返回值类型 。
parameters_off :后缀 off 是 offset , 指向 method 原型的参数列表 type_list ; 若 method 没有参数 ,值为0 。参数列表的格式是 type_list ,结构从逻辑上如下描述 。size 表示参数的个数 ;type_idx 是对应参数的类型 ,它的值是一个 type_ids 的 index 号 ,跟 return_type_idx 是同一个品种的东西 。
public class TypeList {
/**
* struct type_list
{
uint size;
ushort type_idx[size];
}
*/
public int size;//参数的个数
public List<Short> type_idx = new ArrayList<Short>();//参数的类型
} header 里 proto_ids_size = 0x03 , proto_ids_off = 0xc4 , 它的二进制描述区如下 :

根据 proto_id_item 和 type_list 的格式 ,对照这它们的二进制部分 ,整理出表格如下 :

可以看出 ,有 3 个 method 原型 ,返回值都为 void ,index = 0 的没有参数传入 ,index = 1 的传入一个
String 参数 ,index=2 的传入一个 String[] 类型的参数 。
注意:我们在这里会看到很多idx结尾的字段,这个一般都是索引值,所以我们要注意的是,区分这个索引值到底是对应的哪张表格,是字符串池,还是类型池等信息,这个如果弄混淆的话,那么解析就会出现混乱了。这个后面其他数据结构都是需要注意的。
4、field_ids_size和field_ids_off
这两个字段表示dex中的字段信息数据结构的大小和偏移值,后面会详细介绍field_ids的数据结构
5、field_ids数据结构
filed_ids 区里面存放的是dex 文件引用的所有的 field 。本区的元素格式是 field_id_item ,逻辑结构描述如
public class FieldIdsItem {
/**
* struct filed_id_item
{
ushort class_idx;
ushort type_idx;
uint name_idx;
}
*/
public short class_idx;
public short type_idx;
public int name_idx;
public static int getSize(){
return 2 + 2 + 4;
}
@Override
public String toString(){
return "class_idx:"+class_idx+",type_idx:"+type_idx+",name_idx:"+name_idx;
}
} class_idx :表示本 field 所属的 class 类型 , class_idx 的值是 type_ids 的一个 index , 并且必须指向一个class 类型 。
type_idx :表示本 field 的类型 ,它的值也是 type_ids 的一个 index 。
name_idx : 表示本 field 的名称 ,它的值是 string_ids 的一个 index 。
header 里 field_ids_size = 1 , field_ids_off = 0xe8 。说明本 .dex 只有一个 field ,这部分的二进制描述如下 :

注意:这里的字段都是索引值,一定要区分是哪个池子的索引值,还有就是,这个数据结构我们后面也要使用到,所以需要用一个池子来存储。
6、 method_ids数据结构
method_ids 是索引区的最后一个条目 ,它索引了 dex 文件里的所有的 method.
method_ids 的元素格式是 method_id_item , 结构跟 fields_ids 很相似:
public class MethodIdsItem {
/**
* struct filed_id_item
{
ushort class_idx;
ushort proto_idx;
uint name_idx;
}
*/
public short class_idx;
public short proto_idx;
public int name_idx;
public static int getSize(){
return 2 + 2 + 4;
}
@Override
public String toString(){
return "class_idx:"+class_idx+",proto_idx:"+proto_idx+",name_idx:"+name_idx;
}
} class_idx :表示本 method 所属的 class 类型 , class_idx 的值是 type_ids 的一个 index , 并且必须指向一个 class 类型 。
name_idx :表示本 method 的名称 ,它的值是 string_ids 的一个 index 。
proto_idx :描述该 method 的原型 ,指向 proto_ids 的一个 index 。

对 dex 反汇编的时候 ,常用的 method 表示方法是这种形式 :
Lpackage/name/ObjectName;->MethodName(III)Z
将上述表格里的字符串再次整理下 ,method 的描述分别为 :
0:Lhello; -> ()V
1:LHello; -> main([Ljava/lang/String;)V
2:Ljava/io/PrintStream; -> println(Ljava/lang/String;)V
3: Ljava/lang/Object; -> ()V
至此 ,索引区的内容描述完毕 ,包括 string_ids , type_ids,proto_ids , field_ids , method_ids 。每个索引区域里存放着指向具体数据的偏移地址 (如 string_ids ) , 或者存放的数据是其它索引区域里面的 index 号。
注意:这里的字段都是索引值,一定要区分是哪个池子的索引值,还有就是,这个数据结构我们后面也要使用到,所以需要用一个池子来存储。
7、data_size和data_off
这两个字段表示dex中数据区域的结构信息的大小和偏移值,这个结构中存放的是数据区域,比如我们定义的常量值等信息。
第三、class_defs数据结构
上面我们介绍了所有的索引区域,终于到了最后一个数据结构了,但是我们现在还不能开心,因为这个数据结构是最复杂的,所以解析下来还是很费劲的。因为他的层次太深了。
1、class_def_item
从字面意思解释,class_defs区域里存放着class definitions,class的定义。它的结构较dex区都要复杂些,因为有些数据都直接指向了data区里面。
class_defs的数据格式为class_def_item,结构描述如下:
package com.wjdiankong.parsedex.struct;
public class ClassDefItem {
public int class_idx;
public int access_flags;
public int superclass_idx;
public int iterfaces_off;
public int source_file_idx;
public int annotations_off;
public int class_data_off;
public int static_value_off;
public final static int
ACC_PUBLIC = 0x00000001, // class, field, method, ic
ACC_PRIVATE = 0x00000002, // field, method, ic
ACC_PROTECTED = 0x00000004, // field, method, ic
ACC_STATIC = 0x00000008, // field, method, ic
ACC_FINAL = 0x00000010, // class, field, method, ic
ACC_SYNCHRONIZED = 0x00000020, // method (only allowed on natives)
ACC_SUPER = 0x00000020, // class (not used in Dalvik)
ACC_VOLATILE = 0x00000040, // field
ACC_BRIDGE = 0x00000040, // method (1.5)
ACC_TRANSIENT = 0x00000080, // field
ACC_VARARGS = 0x00000080, // method (1.5)
ACC_NATIVE = 0x00000100, // method
ACC_INTERFACE = 0x00000200, // class, ic
ACC_ABSTRACT = 0x00000400, // class, method, ic
ACC_STRICT = 0x00000800, // method
ACC_SYNTHETIC = 0x00001000, // field, method, ic
ACC_ANNOTATION = 0x00002000, // class, ic (1.5)
ACC_ENUM = 0x00004000, // class, field, ic (1.5)
ACC_CONSTRUCTOR = 0x00010000, // method (Dalvik only)
ACC_DECLARED_SYNCHRONIZED = 0x00020000, // method (Dalvik only)
ACC_CLASS_MASK =
(ACC_PUBLIC | ACC_FINAL | ACC_INTERFACE | ACC_ABSTRACT
| ACC_SYNTHETIC | ACC_ANNOTATION | ACC_ENUM),
ACC_INNER_CLASS_MASK =
(ACC_CLASS_MASK | ACC_PRIVATE | ACC_PROTECTED | ACC_STATIC),
ACC_FIELD_MASK =
(ACC_PUBLIC | ACC_PRIVATE | ACC_PROTECTED | ACC_STATIC | ACC_FINAL
| ACC_VOLATILE | ACC_TRANSIENT | ACC_SYNTHETIC | ACC_ENUM),
ACC_METHOD_MASK =
(ACC_PUBLIC | ACC_PRIVATE | ACC_PROTECTED | ACC_STATIC | ACC_FINAL
| ACC_SYNCHRONIZED | ACC_BRIDGE | ACC_VARARGS | ACC_NATIVE
| ACC_ABSTRACT | ACC_STRICT | ACC_SYNTHETIC | ACC_CONSTRUCTOR
| ACC_DECLARED_SYNCHRONIZED);
public static int getSize(){
return 4 * 8;
}
@Override
public String toString(){
return "class_idx:"+class_idx+",access_flags:"+access_flags+",superclass_idx:"+superclass_idx+",iterfaces_off:"+iterfaces_off
+",source_file_idx:"+source_file_idx+",annotations_off:"+annotations_off+",class_data_off:"+class_data_off
+",static_value_off:"+static_value_off;
}
}
(1)class_idx:描述具体的class类型,值是type_ids的一个index。值必须是一个class类型。
(2)access_flags:描述class的访问类型,诸如public,final,static等。
(3)superclass_idx:描述 supperclass 的类型 ,值的形式跟 class_idx 一样 。
(4)interfaces_off:值为偏移地址 ,指向 class 的 interfaces , 被指向的数据结构为 type_list 。class 若没有interfaces ,值为 0。
(5)source_file_idx:表示源代码文件的信息 ,值是 string_ids 的一个 index 。若此项信息缺失 ,此项值赋值为NO_INDEX=0xffff ffff。
(6)annotions_off:值是一个偏移地址 ,指向的内容是该 class 的注释 ,位置在 data 区,格式为annotations_direcotry_item 。若没有此项内容 ,值为 0 。
(7)值是一个偏移地址 ,指向的内容是该 class 的使用到的数据 ,位置在 data 区,格式为class_data_item 。若没有此项内容 ,值为 0 。该结构里有很多内容 ,详细描述该 class 的 field ,method, method 里的执行代码等信息 ,后面有一个比较大的篇幅来讲述 class_data_item 。
(8)static_value_off:值是一个偏移地址 ,指向 data 区里的一个列表 ( list ) ,格式为 encoded_array_item。若没有此项内容 ,值为 0 。
header 里 class_defs_size = 0x01 , class_defs_off = 0x 0110 。则此段二进制描述为 :

2、 class_def_item => class_data_item
class_data_off 指向 data 区里的 class_data_item 结构 ,class_data_item 里存放着本 class 使用到的各种数据 ,下面是 class_data_item 的逻辑结构 :
package com.wjdiankong.parsedex.struct;
public class ClassDataItem {
//uleb128只用来编码32位的整型数
public int static_fields_size;
public int instance_fields_size;
public int direct_methods_size;
public int virtual_methods_size;
public EncodedField[] static_fields;
public EncodedField[] instance_fields;
public EncodedMethod[] direct_methods;
public EncodedMethod[] virtual_methods;
@Override
public String toString(){
return "static_fields_size:"+static_fields_size+",instance_fields_size:"
+instance_fields_size+",direct_methods_size:"+direct_methods_size+",virtual_methods_size:"+virtual_methods_size
+"\n"+getFieldsAndMethods();
}
private String getFieldsAndMethods(){
StringBuilder sb = new StringBuilder();
sb.append("static_fields:\n");
for(int i=0;i<static_fields.length;i++){
sb.append(static_fields[i]+"\n");
}
sb.append("instance_fields:\n");
for(int i=0;i<instance_fields.length;i++){
sb.append(instance_fields[i]+"\n");
}
sb.append("direct_methods:\n");
for(int i=0;i<direct_methods.length;i++){
sb.append(direct_methods[i]+"\n");
}
sb.append("virtual_methods:\n");
for(int i=0;i<virtual_methods.length;i++){
sb.append(virtual_methods[i]+"\n");
}
return sb.toString();
}
}关于元素的格式 uleb128 在 string_ids 里有讲述过 ,不赘述 。
encoded_field 的结构如下 :
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class EncodedField {
/**
* struct encoded_field
{
uleb128 filed_idx_diff; // index into filed_ids for ID of this filed
uleb128 access_flags; // access flags like public, static etc.
}
*/
public byte[] filed_idx_diff;
public byte[] access_flags;
@Override
public String toString(){
return "field_idx_diff:"+Utils.bytesToHexString(filed_idx_diff) + ",access_flags:"+Utils.bytesToHexString(filed_idx_diff);
}
}encoded_method 的结构如下 :
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class EncodedMethod {
/**
* struct encoded_method
{
uleb128 method_idx_diff;
uleb128 access_flags;
uleb128 code_off;
}
*/
public byte[] method_idx_diff;
public byte[] access_flags;
public byte[] code_off;
@Override
public String toString(){
return "method_idx_diff:"+Utils.bytesToHexString(method_idx_diff)+","+Utils.bytesToHexString(Utils.int2Byte(Utils.decodeUleb128(method_idx_diff)))
+",access_flags:"+Utils.bytesToHexString(access_flags)+","+Utils.bytesToHexString(Utils.int2Byte(Utils.decodeUleb128(access_flags)))
+",code_off:"+Utils.bytesToHexString(code_off)+","+Utils.bytesToHexString(Utils.int2Byte(Utils.decodeUleb128(code_off)));
}
}(1) method_idx_diff:前缀 methd_idx 表示它的值是 method_ids 的一个 index ,后缀 _diff 表示它是于另外一个 method_idx 的一个差值 ,就是相对于 encodeed_method [] 数组里上一个元素的 method_idx 的差值 。
(2) access_flags:访问权限 , 比如 public、private、static、final 等 。
(3) code_off:一个指向 data 区的偏移地址 ,目标是本 method 的代码实现 。被指向的结构是
code_item ,有近 10 项元素 ,后面再详细解释 。
class_def_item – > class_data_off = 0x 0234 。

名称为 LHello; 的 class 里只有 2 个 directive methods 。 directive_methods 里的值都是 uleb128 的原始二
进制值 。按照 directive_methods 的格式 encoded_method 再整理一次这 2 个 method 描述 ,得到结果如下
表格所描述 :

method 一个是 , 一个是 main , 这里我们需要用我们在string_ids那块介绍到的一个方法就是解码uleb125类型的方法得到正确的value值。
3、class_def_item => class_data_item => code_item
到这里 ,逻辑的描述有点深入了 。我自己都有点分析不过来 ,先理一下是怎么走到这一步的 ,code_item
在 dex 里处于一个什么位置 。
(1) 一个 .dex 文件被分成了 9 个区 ,详细见 “1. dex 整个文件的布局 ” 。其中有一个索引区叫做
class_defs , 索引了 .dex 里面用到的 class ,以及对这个 class 的描述 。
(2) class_defs 区 , 这里面其实是class_def_item 结构 。这个结构里描述了 LHello; 的各种信息 ,诸如名称 ,superclass , access flag, interface 等 。class_def_item 里有一个元素 class_data_off , 指向data 区里的一个 class_data_item 结构 ,用来描述 class 使用到的各种数据 。自此以后的结构都归于 data区了 。
(3) class_data_item 结构 ,里描述值着 class 里使用到的 static field , instance field , direct_method ,和 virtual_method 的数目和描述 。例子 Hello.dex 里 ,只有 2 个 direct_method , 其余的 field 和method 的数目都为 0 。描述 direct_method 的结构叫做 encoded_method ,是用来详细描述某个 method的 。
(4) encoded_method 结构 ,描述某个 method 的 method 类型 , access flags 和一个指向 code_item的偏移地址 ,里面存放的是该 method 的具体实现 。
(5) code_item , 一层又一层 ,盗梦空间啊!简要的说 ,code_item 结构里描述着某个 method 的具体实现 。它的结构如下描述 :
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class CodeItem {
/**
* struct code_item
{
ushort registers_size;
ushort ins_size;
ushort outs_size;
ushort tries_size;
uint debug_info_off;
uint insns_size;
ushort insns [ insns_size ];
ushort paddding; // optional
try_item tries [ tyies_size ]; // optional
encoded_catch_handler_list handlers; // optional
}
*/
public short registers_size;
public short ins_size;
public short outs_size;
public short tries_size;
public int debug_info_off;
public int insns_size;
public short[] insns;
@Override
public String toString(){
return "regsize:"+registers_size+",ins_size:"+ins_size
+",outs_size:"+outs_size+",tries_size:"+tries_size+",debug_info_off:"+debug_info_off
+",insns_size:"+insns_size + "\ninsns:"+getInsnsStr();
}
private String getInsnsStr(){
StringBuilder sb = new StringBuilder();
for(int i=0;i<insns.length;i++){
sb.append(Utils.bytesToHexString(Utils.short2Byte(insns[i]))+",");
}
return sb.toString();
}
}末尾的 3 项标志为 optional , 表示可能有 ,也可能没有 ,根据具体的代码来 。
(1) registers_size:本段代码使用到的寄存器数目。
(2) ins_size:method传入参数的数目 。
(3) outs_size: 本段代码调用其它method 时需要的参数个数 。
(4) tries_size: try_item 结构的个数 。
(5) debug_off:偏移地址 ,指向本段代码的 debug 信息存放位置 ,是一个 debug_info_item 结构。
(6) insns_size:指令列表的大小 ,以 16-bit 为单位 。 insns 是 instructions 的缩写 。
(7) padding:值为 0 ,用于对齐字节 。
(8) tries 和 handlers:用于处理 java 中的 exception , 常见的语法有 try catch 。
4、 分析 main method 的执行代码并与 smali 反编译的结果比较
在 8.2 节里有 2 个 method , 因为 main 里的执行代码是自己写的 ,分析它会熟悉很多 。偏移地址是
directive_method [1] -> code_off = 0x0148 ,二进制描述如下 :

insns 数组里的 8 个二进制原始数据 , 对这些数据的解析 ,需要对照官网的文档 《Dalvik VM Instruction
Format》和《Bytecode for Dalvik VM》。
分析思路整理如下
(1) 《Dalvik VM Instruction Format》 里操作符 op 都是位于首个 16bit 数据的低 8 bit ,起始的是 op =0x62。
(2) 在 《Bytecode for Dalvik VM》 里找到对应的 Syntax 和 format 。
syntax = sget_object
format = 0x21c 。
(3) 在《Dalvik VM Instruction Format》里查找 21c , 得知 op = 0x62 的指令占据 2 个 16 bit 数据 ,格式是 AA|op BBBB ,解释为 op vAA, type@BBBB 。因此这 8 组 16 bit 数据里 ,前 2 个是一组 。对比数据得 AA=0x00, BBBB = 0x0000。
(4)返回《Bytecode for Dalvik VM》里查阅对 sget_object 的解释, AA 的值表示 Value Register ,即0 号寄存器; BBBB 表示 static field 的 index ,就是之前分析的field_ids 区里 Index = 0 指向的那个东西 ,当时的 fields_ids 的分析结果如下 :

对 field 常用的表述是
包含 field 的类型 -> field 名称 :field 类型 。
此次指向的就是 Ljava/lang/System; -> out:Ljava/io/printStream;
(5) 综上 ,前 2 个 16 bit 数据 0x 0062 0000 , 解释为
sget_object v0, Ljava/lang/System; -> out:Ljava/io/printStream;
其余的 6 个 16 bit 数据分析思路跟这个一样 ,依次整理如下 :
0x011a 0x0001: const-string v1, “Hello, Android!”
0x206e 0x0002 0x0010:
invoke-virtual {v0, v1}, Ljava/io/PrintStream; -> println(Ljava/lang/String;)V
0x000e: return-void
(6) 最后再整理下 main method , 用容易理解的方式表示出来就是 。
ACC_PUBLIC ACC_STATIC LHello;->main([Ljava/lang/String;)V
{
sget_object v0, Ljava/lang/System; -> out:Ljava/io/printStream;
const-string v1,Hello, Android!
invoke-virtual {v0, v1}, Ljava/io/PrintStream; -> println(Ljava/lang/String;)V
return-void
}
看起来很像 smali 格式语言 ,不妨使用 smali 反编译下 Hello.dex , 看看 smali 生成的代码跟方才推导出
来的有什么差异 。
.method public static main([Ljava/lang/String;)V
.registers 3
.prologue
.line 5
sget-object v0, Ljava/lang/System;->out:Ljava/io/PrintStream;
const-string v1, “Hello, Android!\n”
index 0
class_idx 0x04
type_idx 0x01
name_idx 0x0c
class string Ljava/lang/System;
type string Ljava/io/PrintStream;
name string out
invoke-virtual {v0, v1}, Ljava/io/PrintStream;->println(Ljava/lang/String;)V
.line 6
return-void
从内容上看 ,二者形式上有些差异 ,但表述的是同一个 method 。这说明刚才的分析走的路子是没有跑偏
的 。另外一个 method 是 , 若是分析的话 ,思路和流程跟 main 一样 。走到这里,心里很踏实了。















 3053
3053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









