






一、MongoDB概述
1.MongoDB简介
MongoDB 是一个开源的、跨平台的、面向文档的、基于分布式文件存储的数据库系统,MongoDB 是由 C++ 语言开发,旨在为 Web 应用提供可扩展的高性能数据存储解决方案。在高负载的情况下,通过添加更多的节点,可以保证服务器性能。

MongoDB 常常被归类为 NoSQL 数据库系统,也是当前 NoSQL 数据库中比较热门的一种。
2、MongoDB 特点
MongoDB 作为非关系性文档数据库有着以下几个主要特点:
- 高性能:MongoDB 提供了高性能的数据持久化方式,包括了对嵌入式数据模型的支持(减少了数据库系统上的 I/O 操作)。对更多的索引类型的支持(更快的查询),并且可以包含来自嵌入式文档和数组的键;
- 高可用:MongoDB 的复制工具(称为副本集)提供:自动故障转移、数据冗余。副本集是一组维护相同数据集合的 MongoDB 实例,提供了冗余和提高了数据可用性;
- 水平拓展:MongoDB 提供水平可伸缩性作为其核心功能的一部分:分片将数据分布在一个集群的机器上。从 3.4 开始,MongoDB 支持基于分片键创建数据区域。在平衡群集中,MongoDB 仅将区域覆盖的读写定向到区域内的那些分片;
- 丰富的查询语言:MongoDB 支持丰富的查询语言以支持读写操作(CRUD)以及:数据聚合、文本搜索和地理空间查询;
- 支持多种存储引擎:MongoDB支持多个存储引擎:WiredTiger 存储引擎(包括对静态加密的支持 )、内存存储引擎。 另外,MongoDB 提供可插拔的存储引擎 API,允许第三方为 MongoDB 开发存储引擎。
3、MongoDB 数据逻辑结构
MongoDB的一个实例,由多个数据库(Database)组成;一个数据库,由多个集合(Collection)组成;一个集合,又由多个文档(Document)组成!
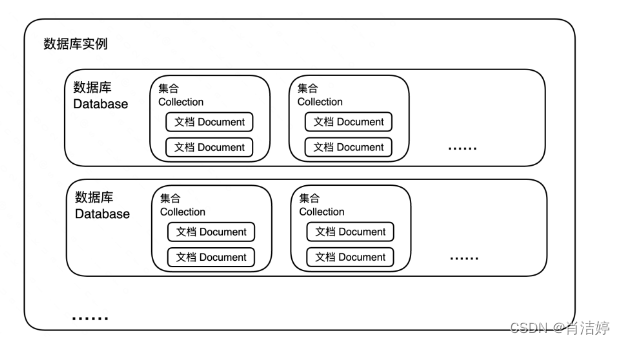
在MongoDB数据库里是存在有数据库的概念,但是没有模式(所有的信息都是按照文档保存的),保存数据的结构就是JSON结构,只不过在进行一些数据处理的时候,才会使用MongoDB自己的一些操作符号。
cls命令可以清屏幕
二、数据库操作
新建数据库
语法:
use DATABASE_NAMEuse:用于切换/创建数据库,若不存在则创建,否则切换到指定数据库。
DATABASE_NAME:数据库的名称。
如执行use test命令,创建数据库test。
![]()
查看数据库
查看全部数据库:
show dbs查看当前数据库,需要先切换到指定数据库
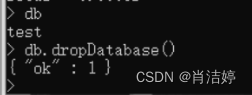
db删除数据库
语法:
db.dropDatabase()如
三、集合操作
创建集合
语法:db.createCollection(name,options)方法创建集合。name是要创建的集合的名称,options是一个可选参数,用于指定集合的配置选项,
如:创建一个名为"myCollection"的普通集合
db.createCollection("myCollection")
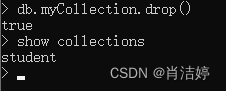
删除集合
语法:
db.createCollection("myCollection")如执行"db.myCollection.drop()"命令,删除集合myCollection
文档操作
单文档插入
db.COLLECTION_NAME.insert(document)或者
db.COLLECTION_NAME.save(document)
多文本插入
db.COLLECTION_NAME.insertMany([document1,document2,.....])insert()与save()方法的区别在于,若使用insert()方法插入文档时,集合中已存在该文档,则会报错。若使用save()方法插入文档时,集合中已存在该文档,则会覆盖。
如
插入如下学生信息:
{name:"张三", age:18, sex:"男",major:"大数据技术"},
{name:"李四", age:19, sex:"男",major:"大数据技术"},
{name:"王五", age:18, sex:"女",major:"人工智能"}
使用insert()方法
db.student.insert( {"name":"王五"," age":"18","sex":"女","major":"人工智能"})使用insertMany([])方法
db.student.insertMany( [{"name":"张三", "age":"18", "sex":"男","major":"大数据技术"}, {"name":"李四"," age":"19","sex":"男","major":"大数据技术"}, {"name":"王五"," age":"18","sex":"女","major":"人工智能"}]))执行“db.student.find()”命令,查看集合student中的文档内容
文档更新
更新单个文档
db.collection_name.updateOne()db.collection_name.updateOne( { key1: value1 }, // 查询条件
{ $set: { key2: value2 } } // 更新操作);
/更新多个文档
db.collection_name.updateMany()db.collection_name.updateMany( { key1: value1 }, // 查询条件
{ $set: { key2: value2 } } // 更新操作);
升级语法
db.集合名.update(条件,新数据) {修改器:{键:值}}| 修改器 | 作用 |
| $inc | 递增 |
| $rename | 重命名列 |
| $set | 修改列值 |
| $unset | 删除列 |
案列说明
1.将{major:"人工智能"}修改为{major:"大数据技术"}
db.student.update({"major":"人工智能"},{$set:{"major":"大数据技术"}})
发现:默认不是修改,而是替换
解决:使用升级语法修改器
2.给{name:"张三"}的年龄加2岁或减2岁
db.student.update({"name":"张三"},{"$inc":{"age":2}})db.student.update({"name":"张三"},{"$inc":{"age":-2}})文档删除
删除单个文档
db.COLLECTION_NAME.remove()删除多个文档
db.COLLECTION_NAME.remove({})- db:当前数据库对象
- COLLECTION_NAME:当前集合对象
- remove():删除文档的条件,可选参数
删除集合student中键nickname为"Rose"的文档,具体操作命令如下
db.student.remove({"nickname":"Rose"})查看集合中所有文档,验证文档是否删除成功,具体操作命令如下
db.student.find()删除集合commet中全部文档,具体操作命令如下
db.student.remove({})
再次查看集合中所有文档,验证文档是否全部删除,具体操作命令如下
db.student.find()文档简单查询
查询所有文档语法
db.COLLECTION_NAME.find()查询所有文档,以易读的方式展示
db.COLLECTION_NAME.find().pretty()- db:当前数据库对象
- COLLECTION_NAME:当前集合对象
- find():查询所有文档的方法
- pretty():格式化查询返回结果
按条件查询文档
基础语法:db.集合名.find(条件[,查询的列])
查询age为4,只显示它的姓名;

升级语法
db.集合名.find({键:值}) 注:值可以不直接写
{运算符:值}
db.集合名.find({
键:{运算符:值}
})| 运算符 | 作用 |
| $gt | 大于 |
| $gte | 大于等于 |
| $lt | 小于 |
| $lte | 小于等于 |
| $ne | 不等于 |
| $in | in |
| $nin | not in |
1.查询年龄大于5岁的数据
db.c1.find({age:{$gt:5}})
2.查询年龄是18岁、20岁、25岁的数据
db.c1.find({age:{$in:[18,20,25]}})
总结
db.集合名.insert(JSON数据)
db.集合名.remove([条件,是否删除一条true是false否默认])
也就是默认删除多条
db.集合名.update(条件, 新数据[,是否新增,是否修改多余条])
升级语法
db.集合名.update(条件,{修改器:{键:值}})
db.集合名.find(条件[,查询的列])四、聚合操作
聚合操作是数据处理的一种方法,它涉及对一组数据执行计算,以返回总结性信息,如统计、分析或其他类型的汇总。聚合操作通常用于数据库和大数据环境中,以处理和转换大量数据。
- 单一作用聚合:提供了对常见聚合过程的简单访问,操作都从单个集合聚合文档。
- 聚合管道是一个数据聚合的框架,模型基于数据处理流水线的概念。文档进入多级管道,将 文档转换为聚合结果。
- MapReduce操作具有两个阶段:处理每个文档并向每个输入文档发射一个或多个对象的map阶段,以及reduce组合map操作的输出阶段
常见管道操作符如下表
| 常见管道操作符 | 相关说明 |
| $group | 将集合中的文档进行分组,便于后续统计结果 |
| $limit | 用于限制MongoDB聚合管道返回的文档数 |
| $match | 用于过滤数据,只输出符合条件的文档 |
| $sort | 将输入的文档先进行排序,再输出 |
| $project | 用于修改输入文档的结构(增加、删除字段等)和名称 |
| $skip | 在聚合管道中跳过指定数量的文档,并返回剩余的文档 |















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









