






叶子结点:一棵树当中没有子结点(即度为0)的结点称为叶子结点,简称“叶子”。
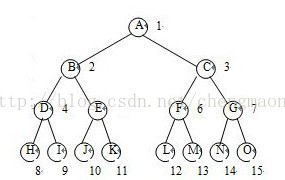
如图所示:
高度
对于高度的理解,我们不管他数据结构什么什么知识,就拿楼房来说,假如一个人提问:楼房的高度有好高?我们会下意识的从底层开始往上数,假如楼有6层,则我们会说,这个楼有6层楼那么高,则提问者就会大概知道楼有多高了。所以高度就是以从下往上对比,这是我们的习惯。而在树中,树的高度也是从下往上数,如图所示

K节点在树的底层,是一个叶子节点,则一般定义为K的高度在最低为1,以此类推,O的高度也是为1,P的节点也是为1。M节点是叶子节点O的父节点,从下往上数,M节点高度为2。那么G节点的高度是多少呢?从G-L的高度为2,从G-M-O节点高度为3,到底G节点高度为多少呢,正确答案是3,请看定义:
高度的定义为:从结点x向下到某个叶结点最长简单路径中边的条数
深度:
理解了高度,则深度的理解就很容易了,深度是从根节点往下,列如上图中:B的深度为2。
结点的深度:从根节点开始自顶向下逐层累加。
深度与高度差异:
对于整棵树来说,最深的叶结点的深度就是树的深度;树根的高度就是树的高度。这样树的高度和深度是相等的。
对于树中相同深度的每个结点来说,它们的高度不一定相同,这取决于每个结点下面的叶结点的深度。
B树的目的为了硬盘快速读取数据(降低IO操作次树)而设计的一种平衡的多路查找树。目前大多数据库及文件索引,都是使用B树或变形来存储实现。
为什么B树效率高:
在大规模数据存储操作中,由于无法一次性加载到内存里。所以避免不了发生内外存交换。所以次数越少,效率表现也越高。
b+树来存储,只有叶子节点存储数据,每个叶子节点都指向下一个。
B树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于
走右结点;
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键
字范围的子结点;
所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点
中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率
从1/2提高到2/3;
满二叉树
一棵深度为k,且有2^k-1个节点的树是满二叉树。
另一种定义:除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
这两种定义是等价的。
从树的外形来看,满二叉树是严格三角形的,大家记住下面的图,它就是满二叉树的标准形态:
所有内部节点都有两个子节点,最底一层是叶子节点。
性质:
1) 如果一颗树深度为h,最大层数为k,且深度与最大层数相同,即k=h;
2) 它的叶子数是: 2^(h-1)
3) 第k层的结点数是: 2^(k-1)
4) 总结点数是: 2^k-1 (2的k次方减一)
5) 总节点数一定是奇数。
6) 树高:h=log2(n+1)。
完全二叉树
完全二叉树是由满二叉树而引出来的。对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。
若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h 层所有的结点都连续集中在最左边,这就是完全二叉树。
(大家好好理解一下上面两个定义,是等价的~~)
满二叉树一定是完全二叉树,完全二叉树不一定是满二叉树。
下面是完全二叉树的基本形态:
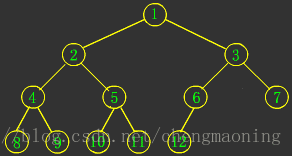
完全二叉树的性质:
1) 深度为k的完全二叉树,至少有2^(k-1)个节点,至多有2^k-1个节点。
2) 树高h=log2n + 1。
对满二叉树、完全二叉树总结点及树高的总结:
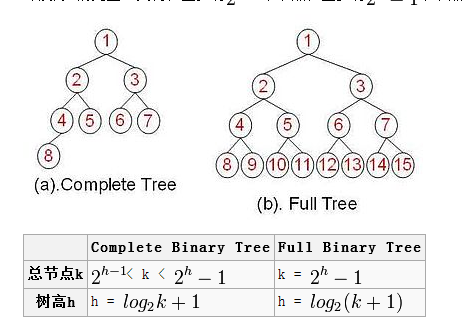
https://blog.csdn.net/JuinH/article/details/77648460
https://www.cnblogs.com/lwhkdash/p/5313877.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









