






本文是学习算法不好玩的学习笔记,配合视频链接学习更好。视频链接如下:https://space.bilibili.com/236935093
算法入门之排序算法(算法不好玩)
递归
递归是函数自己调用自己来解决问题的一种方式。它体现的是一种自顶向下的解决问题的思路。、
递归解决问题有两个过程:
-
第一个过程是拆分问题的过程
-
第二个过程是组合问题的解的过程
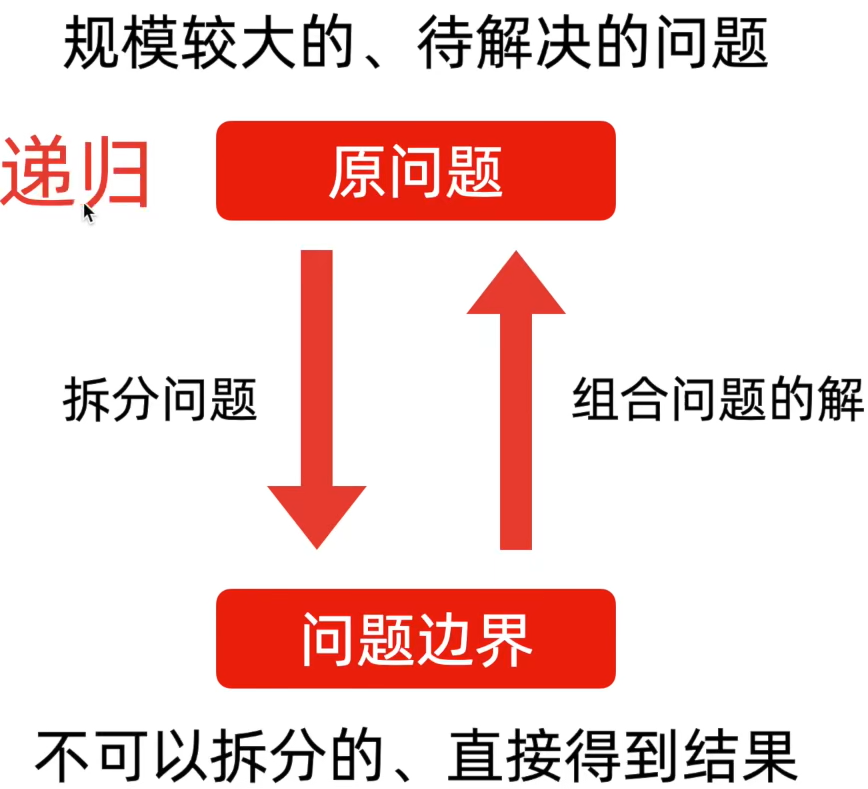
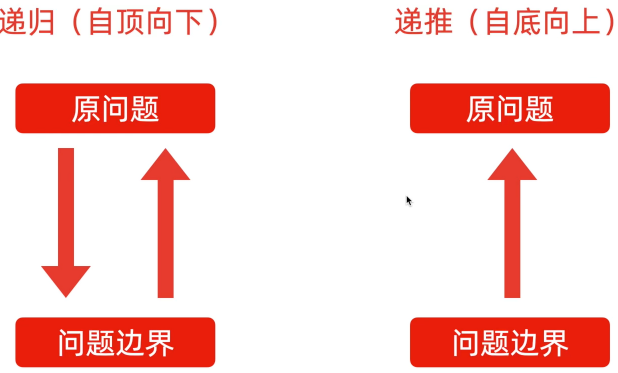
这两个过程是独立的,即递归解决问题时是先拆分到不可以再拆分(拆到问题的边界)之后才开始组合问题的解。而只有由问题边界一步步推导出原问题的解的过程叫做递推。递归是先自顶向下再自底向上,递推只有自底向上。
在计算机中实现递归的数据结构叫做栈,因为它是一种支持后进先出应用场景的线性的数据结构。它可以保证我们拆分问题过程中后拆分的问题先计算出结果。
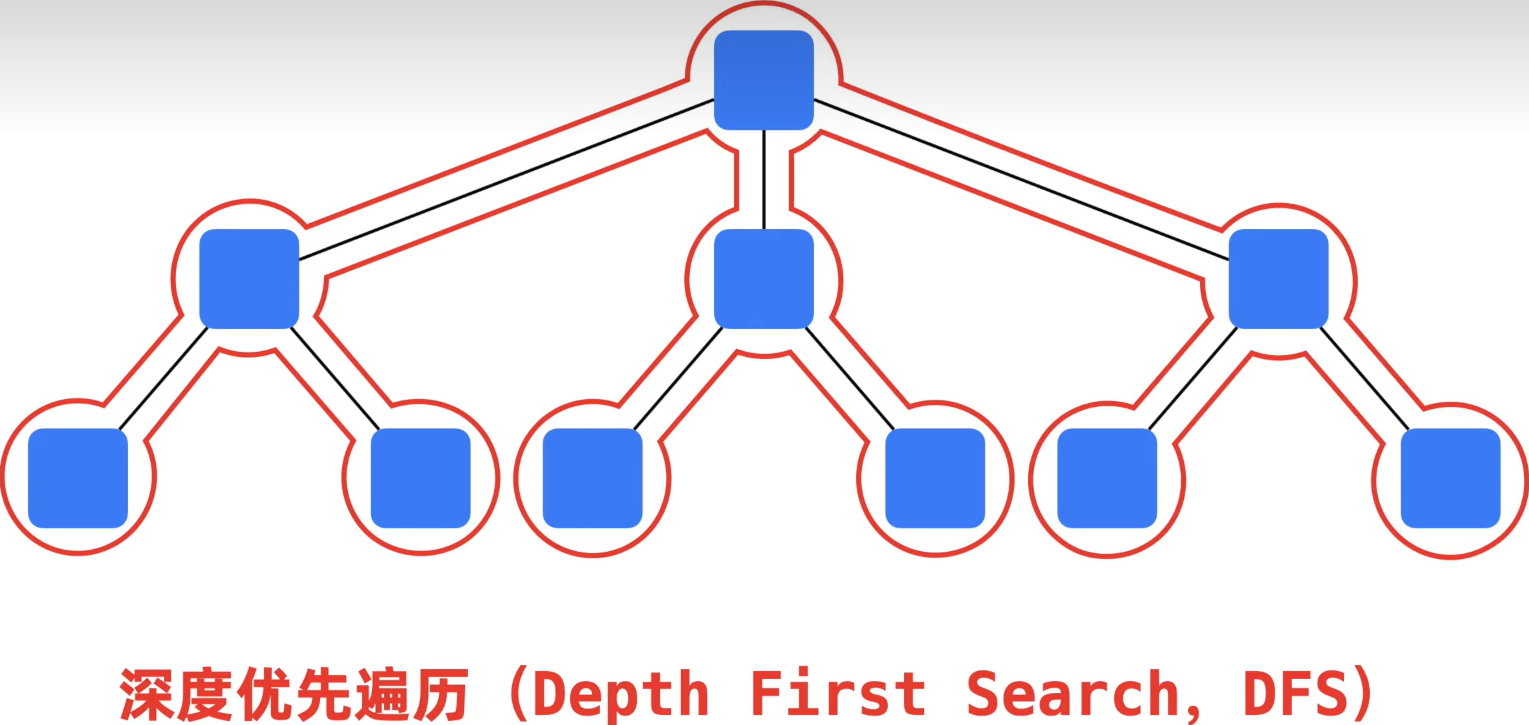
如果原问题和子问题之间是线性结构那么直接进行拆分然后组合就可以了,但是如果它们之间是树形结构,那么其是按照深度优先遍历的方式进行拆分和组合的(即递归),在遍历时,程序需要记住哪些节点还没有访问过,这一操作就是通过栈来实现的(没访问的节点先放入栈中然后访问其他的节点,利用的就是后进先出的特性,这样我们访问后面的节点不会影响前面的节点,等到其需要访问时再取出来)。
递归总结:



时间复杂度
时间复杂度是一个动态的概念,它表示随着输入规模的增大,程序的运行时间增加的快慢。

具体时间复杂度的表示法是使用大O表示法,求法如下:

时间复杂度的极限定义如下:

g(N)就是大O括号中的内容,f(N)就是具体的我们代码的复杂度,我们可以找出一个其上界即cg(N),这里c是一个常数对于时间复杂度来说并不重要。所以g(N)就是我们要求的时间复杂度。

插入排序:

循环不变量:
循环不变量是一个性质:在循环过程中保持不变的性质。
这里的量并不是指变量,在循环过程中变量的值虽然会发生变化,但是循环过程中会有一些性质保持不变,这些性质就是循环不变量,这里的量指的是一些断言(可以判断真假的语句),循环不变量有以下性质:

循环开始前表示一个基本的情况,循环过程中说明一个递推的情况,这就推出了循环结束时这个断言依旧成立。而循环结束之后成立的这件事情往往就是我们要求的结论。前两个性质是原因,最后一个性质是结果。


这里保持中应该是使得nums[0…i+1)有序,这样下次开始前就保存了性质。
这两个例子都说明了循环不变量,其实它非常简单,因为我们这两个排序都是一次排定一个元素在数组头部,所以我们很容易就可以分析出来循环不变量。
后面的查找并且移动数组元素和这里排序是一样的,如果是闭区间则表示当前i可以取到,也就是i包含在循环不变量的区间中,那么i表示符合循环不变量的元素,即已经处理过的符合要求的元素,如果是开区间则表示i娶不到,即i是即将要处理的元素的位置。
归并排序:
归并排序是使用的是递归算法,这个算法的思想是分治思想(拆分问题与组合问题的解),递归结构即代码执行的方式为深度优先遍历的方式进行执行的。
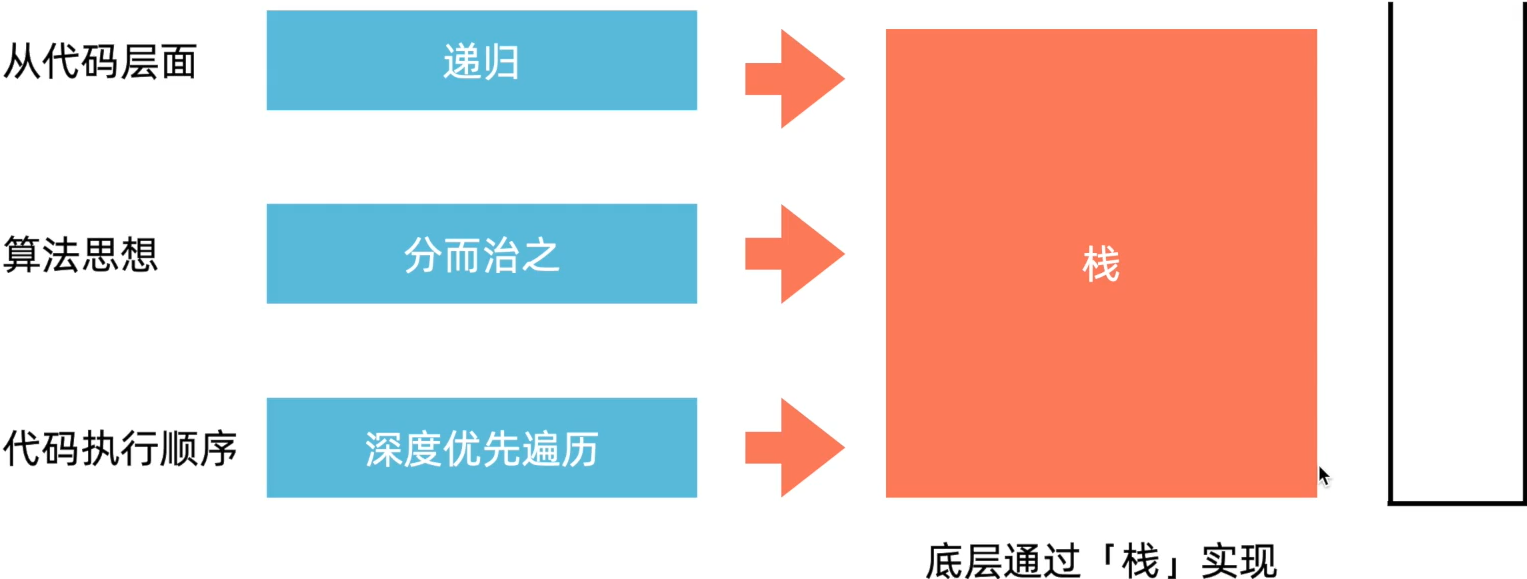
深度优先遍历的递归具体执行时代码入栈顺序为先执行的代码后入栈,后执行的代码先入栈,因为栈的结构是后进先出即后来的代码先执行。
快速排序:
快速排序也是利用的分治的思想,使用的递归算法来实现的。最普通的快速排序是从前向后遍历元素,选定一个pivot(切分)元素,以这个元素为界进行划分区间(<或者>=),简单记忆就是六个字:大放过小替换。这种方法的pivot元素取的是数组区间的left下标的元素,这种方法有一个缺点就是数组如果是顺序或者倒序的,那么效率会非常低。

然后我们可以通过随机(Random)选取切分元素来改进这种方法。但是随机选取无法处理如果数组中有很多相同元素时的情况,因为随机选取的很可能是一个在数组中有很多重复元素的元素。因此我们又引进了新的优化算法。
双路快排:

双路快排是区间两个指针(左右指针),然后相向遍历区间,左指针遇到第一个不小于pivot元素的元素时停下,然后开始移动右指针,右指针一直移动到第一个不大于pivot元素的元素时停下,然后交换这两个元素。
在最后退出整个遍历区间的循环时:

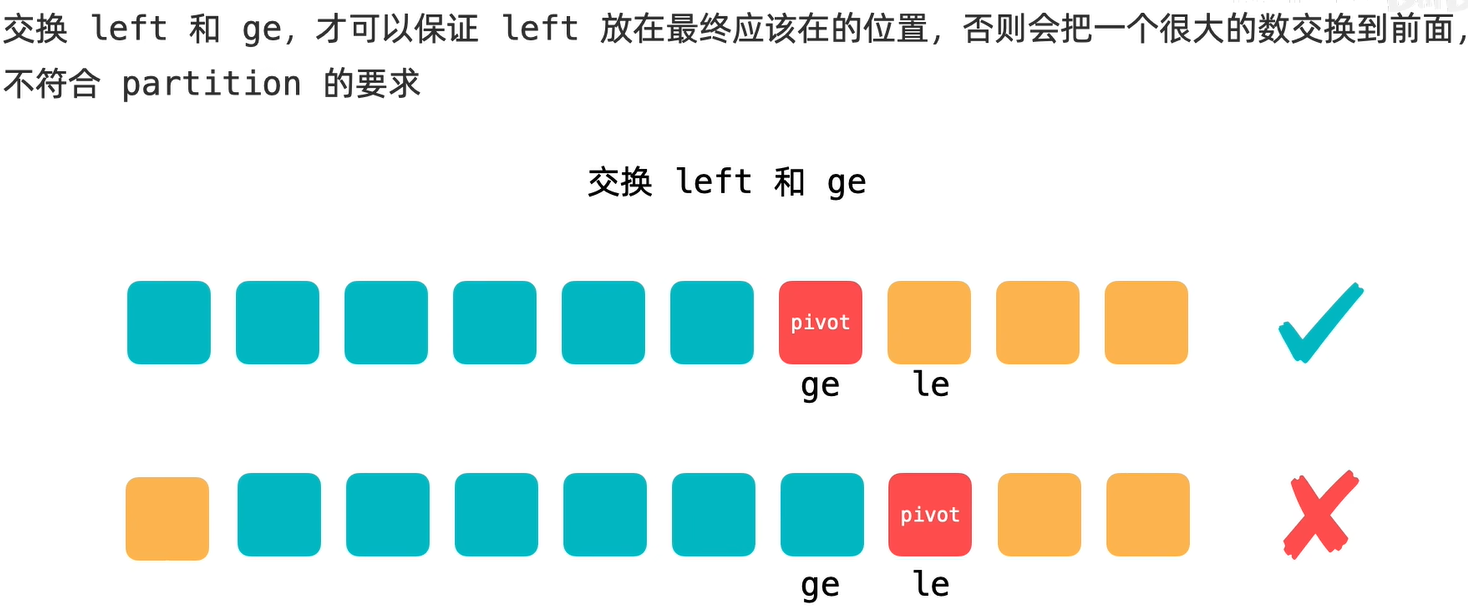
因为ge的访问在le之后。
三路快排:


具体操作如下:

三路快排之所以快是因为我们把所有等于pivot元素的元素都挤到了数组的中间,那么下次划分区间时我们就能递归处理更小的数组区间,这样执行效率就会大大提高。


总结:
快速排序不同于归并排序,它虽然也是递归但是它并不是分治算法的思想而是减治算法的思想,因为它在划分子问题上直接处理数组所以并不需要合并这一步骤,所以快速排序算法的思想是分治算法的特例——减治算法(逐渐的缩小待排序的区间)。
递归是一种逆向思维,它并不是直接解决一个较大的原问题,而是把这个原问题转换为规模更小的子问题,然后再逐个的解决这些子问题,子问题解决之后再利用子问题的结果组合成规模更大的子问题的结果,知道原问题得到了解决,这就是一种逆向思维。
如果我们把递归的结构画出来,其实就会发现它就是一个树结构,递归的过程就相当于遍历这个树,遍历的方法就是深度优先遍历,其中我们刚刚学的归并排序和快速排序都需要我们保存暂时还没有解决的问题,保存这些问题的结构就是栈数据结构。所以递归是空间换时间的思想的体现。
感谢耐心看到这里的同学,觉得文章对您有帮助的话希望同学们不要吝啬您手中的赞,动动您智慧的小手,您的认可就是我创作的动力!
之后还会勤更自己的学习笔记,感兴趣的朋友点点关注哦。















 265
265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









