







 本文详细介绍了Apache HBase,一个基于Hadoop和HDFS的分布式数据库,强调其作为NoSQL与RDBMS之间的系统,具备高可靠性、高性能、列存储等特点。内容涵盖HBase的逻辑结构、物理存储、分布式系统架构,以及在Hadoop生态中的角色。文中还讨论了HRegion、Store、HFile等核心概念,以及Master Server、Region Server和Zookeeper的角色和功能。
本文详细介绍了Apache HBase,一个基于Hadoop和HDFS的分布式数据库,强调其作为NoSQL与RDBMS之间的系统,具备高可靠性、高性能、列存储等特点。内容涵盖HBase的逻辑结构、物理存储、分布式系统架构,以及在Hadoop生态中的角色。文中还讨论了HRegion、Store、HFile等核心概念,以及Master Server、Region Server和Zookeeper的角色和功能。
HBase调研分享文档
Ver1.0 by谢柯2015/7/20
一、HBase简介
HBase官方定义: Apache HBase™ is the Hadoop database, a distributed,scalable, big data store
HBase是bigtable的开源山寨版本。是建立的HDFS之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。它介于Nosql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。
与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
HBase中的表一般有这样的特点:
1) 大:一个表可以有上亿行,上百万列
2) 面向列: 面向列(族)的存储和权限控制,列(族)独立检索。
3) 稀疏: 对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
4) 可伸缩性scalability:对多个服务器负载进行均衡操作的特性。
5) 多维有序映射的键值存储。
HBase在Hadoop生态系统中的位置:
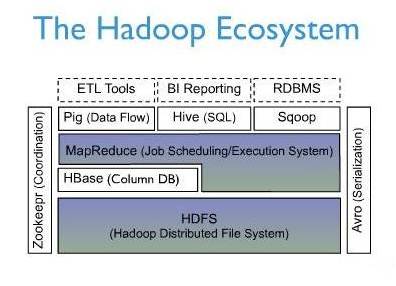
HDFS为HBase提供了高可靠性的底层存储支持,MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制,还有Hive等作为数据仓库工具提供类似SQL语句的查询服务。
二、HBase表逻辑结构术语介绍
HBase以表的形式存储数据,表有行和列组成。列划分为若干个列族(row family),如下:

1) Row Key行键:Row Key是用来检索记录的主键,可以是任意字符串(最大长度是 64KB,实际应用中长度一般为10-100bytes)。HBase数据都是以字符串的形式存储的,数据也按照Row Key的字典序(byte order)排序存储,如int型排序应为1,10,100,11,12…,一般补零。
2) Column Family列族:HBase表中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 490
490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









