







下载网址 :https://github.com/medcl/elasticsearch-rtf/tree/master
Java API : http://www.ibm.com/developerworks/library/j-use-elasticsearch-java-apps/index.html
Elasticsearch使用和介绍: http://blog.csdn.net/laoyang360/article/details/52244917
Elasticsearch使用中的常见错误:http://itindex.net/detail/51176-elasticsearch-%E9%97%AE%E9%A2%98-%E6%96%B9%E6%B3%95
Elasticsearch介绍
初识:
Elasticsearch 是一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎,可以说Lucene 是当今最先进,最高效的全功能开源搜索引擎框架。
但是 Lucene 只是一个框架,要充分利用它的功能,你需要使用Java,并且在你的程序中集成 Lucene。更糟的是,你需要做很多的学习了解,才能明白它是如何运行的,
Lucene 确实非常复杂。
Elasticsearch 使用 Lucene 作为内部引擎,但是在你使用它做全文搜索时,只需要使用统一开发好的API即可,而并不需要了解其背后复杂的 Lucene 的运行原理。
当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作(特点和优势):
· 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
· 实时分析的分布式搜索引擎。
· 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
· 支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等
这么多的功能被集成到一台服务器上,你可以轻松地通过客户端或者任何你喜欢的程序语言与 ES 的 RESTful API 进行交流。
利用这个REST API你可以同你的集群交互。下面是利用这个API,可以做的几件事情:
- 检查你的集群、节点和索引的健康状态、和各种统计信息
- 管理你的集群、节点、索引数据和元数据
- 对你的索引进行CRUD(创建、读取、更新和删除)和搜索操作
- 执行高级的查询操作,像是分页、排序、过滤、脚本编写(scripting)、小平面刻画(faceting)、聚合(aggregations)和许多其它操作
1. 索引
索引(index)是Elasticsearch对逻辑数据的逻辑存储,所以它可以分为更小的部分。你可以把索引看成关系型数据库的表。然而,索引的结构是为快速有效的全文索引准备的,
特别是它不存储原始值。
Elasticsearch可以把索引存放在一台机器或者分散在多台服务器上,每个索引有一或多个分片(shard),每个分片可以有多个副本(replica)。
2. 文档
存储在Elasticsearch中的主要实体叫文档(document)。用关系型数据库来类比的话,一个文档相当于数据库表中的一行记录。
文档由多个字段组成,每个字段可能多次出现在一个文档里,这样的字段叫多值字段(multivalued)。每个字段有类型,如文本、数值、日期等。字段类型也可以是复杂类型,一个字段包含其他子文档或者数组。
字段类型在Elasticsearch中很重要,因为它给出了各种操作(如分析或排序)如何被执行的信息。幸好,这可以自动确定,然而,我们仍然建议使用映射。
与关系型数据库不同,文档不需要有固定的结构,每个文档可以有不同的字段,此外,在程序开发期间,不必确定有哪些字段。当然,可以用模式强行规定文档结构。
从客户端的角度看,文档是一个JSON对象。每个文档存储在一个索引中并有一个Elasticsearch自动生成的唯一标识符和文档类型。
文档需要有对应文档类型的唯一标识符,这意味着在一个索引中,两个不同类型的文档可以有相同的唯一标识符。
3. 文档类型
在Elasticsearch中,一个索引对象可以存储很多不同用途的对象。例如,一个博客应用程序可以保存文章和评论。文档类型让我们轻易地区分单个索引中的不同对象。
每个文档可以有不同的结构,但在实际部署中,将文件按类型区分对数据操作有很大帮助。当然,需要记住一个限制,不同的文档类型不能为相同的属性设置不同的类型。
例如,在同一索引中的所有文档类型中,一个叫title的字段必须具有相同的类型。
4. 映射
在有关全文搜索基础知识部分,我们提到了分析的过程:为建索引和搜索准备输入文本。文档中的每个字段都必须根据不同类型做相应的分析。举例来说,对数值字段和从网页抓取的文本字段有不同的分析,
比如前者的数字不应该按字母顺序排序,后者的第一步是忽略HTML标签,因为它们是无用的信息噪音。Elasticsearch在映射中存储有关字段的信息。每一个文档类型都有自己的映射,即使我们没有明确定义。
Elasticsearch 主要概念
现在,我们已经知道Elasticsearch把数据存储在一个或多个索引上,每个索引包含各种类型的文档。我们也知道了每个文档有很多字段,映射定义了Elasticsearch如何对待这些字段。但还有更多,
从一开始,Elasticsearch就被设计为能处理数以亿计的文档和每秒数以百计的搜索请求的分布式解决方案。这归功于几个重要的概念,我们现在将更详细地描述。
1. 节点和集群
Elasticsearch可以作为一个独立的单个搜索服务器。不过,为了能够处理大型数据集,实现容错和高可用性,Elasticsearch可以运行在许多互相合作的服务器上。这些服务器称为集群(cluster),
形成集群的每个服务器称为节点(node)。
2. 分片
当有大量的文档时,由于内存的限制、硬盘能力、处理能力不足、无法足够快地响应客户端请求等,一个节点可能不够。在这种情况下,数据可以分为较小的称为分片(shard)的部分
(其中每个分片都是一个独立的Apache Lucene索引)。每个分片可以放在不同的服务器上,因此,数据可以在集群的节点中传播。当你查询的索引分布在多个分片上时,
Elasticsearch会把查询发送给每个相关的分片,并将结果合并在一起,而应用程序并不知道分片的存在。此外,多个分片可以加快索引。
3. 副本(复制)
为了提高查询吞吐量或实现高可用性,可以使用分片副本。副本(replica)只是一个分片的精确复制,每个分片可以有零个或多个副本。换句话说,Elasticsearch可以有许多相同的分片,其中之一被自动选择去更改索引操作。这种特殊的分片称为主分片(primary shard),其余称为副本分片(replica shard)。在主分片丢失时,例如该分片数据所在服务器不可用,集群将副本提升为新的主分片。
4. 时光之门
Elasticsearch处理许多节点。集群的状态由时光之门控制。默认情况下,每个节点都在本地存储这些信息,并且在节点中同步。
面向文档
应用中的对象很少只是简单的键值列表,更多时候它拥有复杂的数据结构,比如包含日期、地理位置、另一个对象或者数组。
总有一天你会想到把这些对象存储到数据库中。将这些数据保存到由行和列组成的关系数据库中,就好像是把一个丰富,信息表现力强的对象拆散了放入一个非常大的表格中:你不得不拆散对象以适应表模式
(通常一列表示一个字段),然后又不得不在查询的时候重建它们。
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。
在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。这种理解数据的方式与以往完全不同,这也是Elasticsearch能够执行复杂的全文搜索的原因之一。
ES数据架构的主要概念(与关系数据库Mysql对比)
(1)关系型数据库中的数据库(DataBase),等价于ES中的索引(Index)
(2)一个数据库下面有N张表(Table),等价于1个索引Index下面有N多类型(Type),
(3)一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多Field组成。
(4)在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在ES中:Mapping定义索引下的Type的字段处理规则,
即索引如何建立、索引类型、是否保存原始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等。
(5)在数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT/POST、删Delete、改_update、查GET.
Windows上安装和使用
版本: Windows64位 Elasticsearch-1.7.1
注意:安装elasticsearch时,必须确保正确安装java环境(jdk),而且不同的elasticsearch的版本所需要的jdk版本也不同
在这里我用的版本是Elasticsearch-1.7.1的,所以需要jdk版本1.7+就可以了
安装步骤:
安装Elasticsearch
1.解压(D:\elasticsearch-1.7.1)
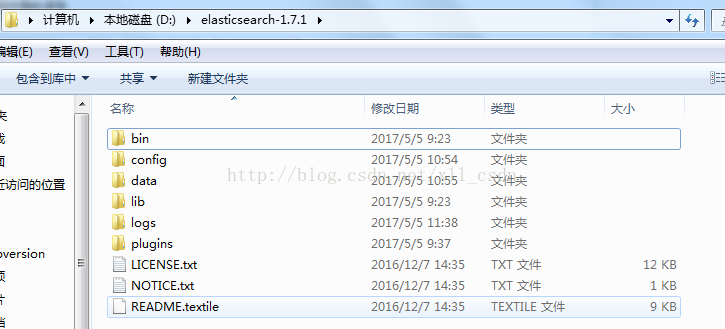
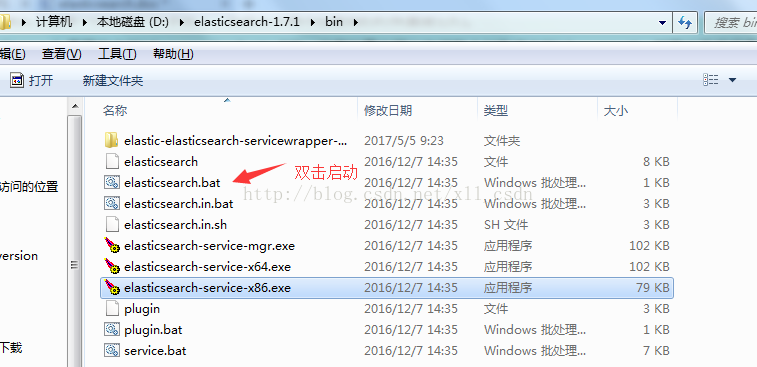
2.启动( 进入解压的bin目录下 )
1).第一种启动:
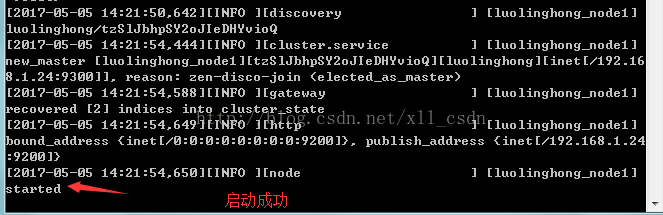
启动成功:
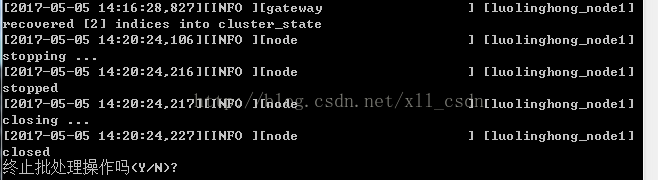
(但这种启动,在你Ctrl+C的时候选择Y,就会停止并退出这个窗口)
2).第二种启动: (cmd进入解压文件并到bin目录下)
执行:
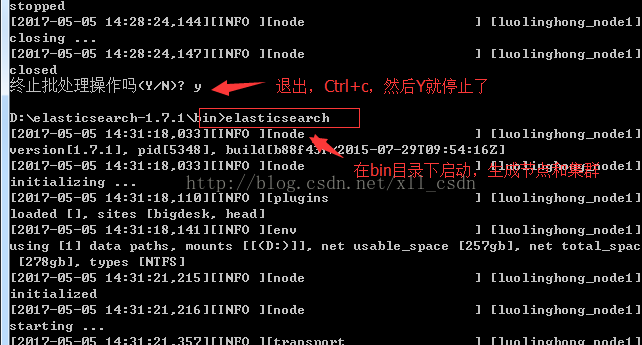
(这种启动,在你Ctrl+C的时候选择Y会停止,但可以再继续操作其他命令)
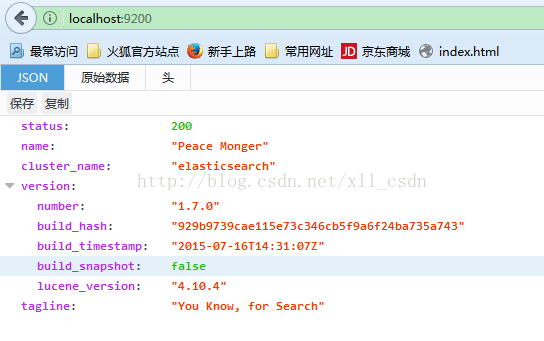
3).测试启动 (在浏览器输入localhost:9200)
安装Elasticsearch插件
1).插件elasticsearch-head安装:
elasticsearch-head是一个elasticsearch的集群管理工具,它是完全由html5编写的独立网页程序,你可以通过插件把它集成到es。
在cmd命令行中进入安装目录,再进入 bin目录,运行以下命令:
plugin -install mobz/elasticsearch-head
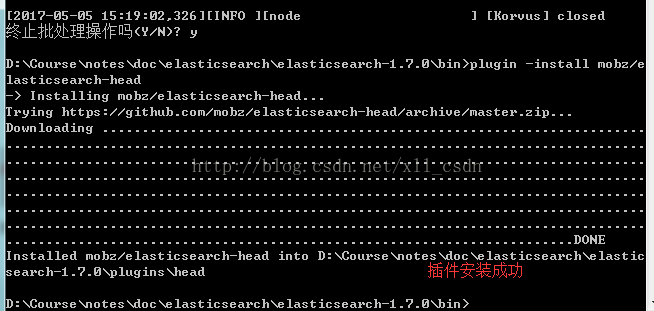
然后安装成功后,\plugins目录下会有head的文件夹。
在浏览器中输入:http://localhost:9200/_plugin/head/,可以看到效果。
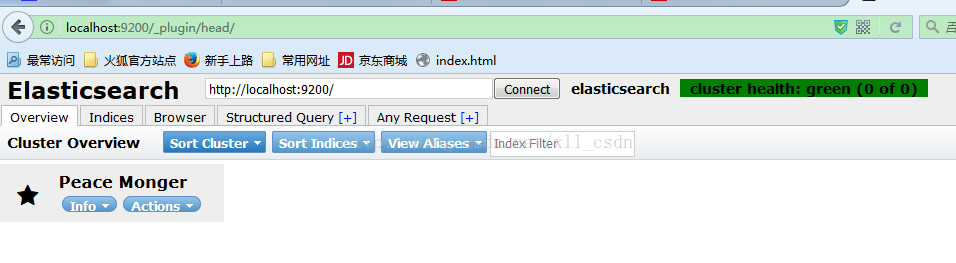
2).插件elasticsearch-bigdesk安装:
bigdesk是elasticsearch的一个集群监控工具,可以通过它来查看es集群的各种状态,如:cpu、内存使用情况,索引数据、搜索情况,http连接数等。
在cmd命令行中进入安装目录,再进入 bin目录,运行以下命令:
plugin -install lukas-vlcek/bigdesk
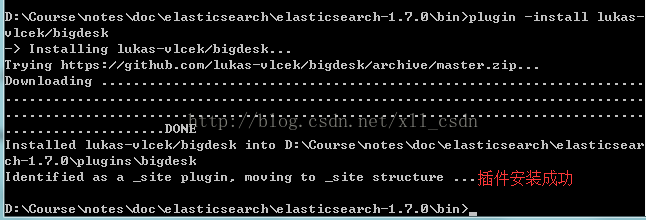
然后安装成功后,在浏览器中输入:http://localhost:9200/_plugin/bigdesk/,可以看到效果。
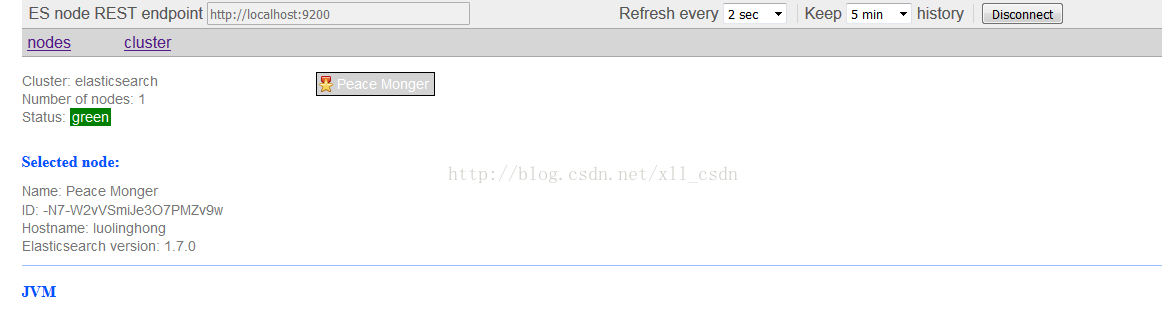
注意:插件安装成功后,都需要启动elasticsearch才能访问
节点和集群配置
修改配置文件(节点)
以上都是默认配置启动时,生成的集群和节点,以下就是修改的做法
进入解压文件的config下
文件内容如下:
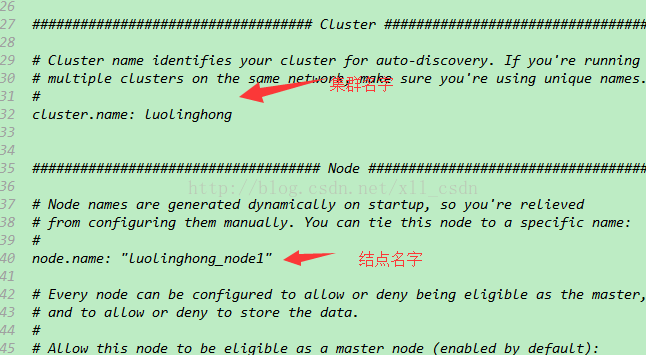
修改后重启(注意将 # 解开)

搭建集群
一个节点也是可以叫集群的,现在弄2个节点的集群。
集群和节点
节点(node)是一个运行着的Elasticsearch实例。
集群(cluster)是一组具有相同cluster.name的节点集合,他们协同工作,共享数据并提供故障转移和扩展功能,当然一个节点也可以组成一个集群。
关于 cluster.name 的解释: 这个在config配置文件 elasticsearch.yml 里面可以自己修改,我的集群就叫luolinghong
步骤:
1. 将解压目录复制一份,并改名

修改复制的文件里面的config配置文件 elasticsearch.yml

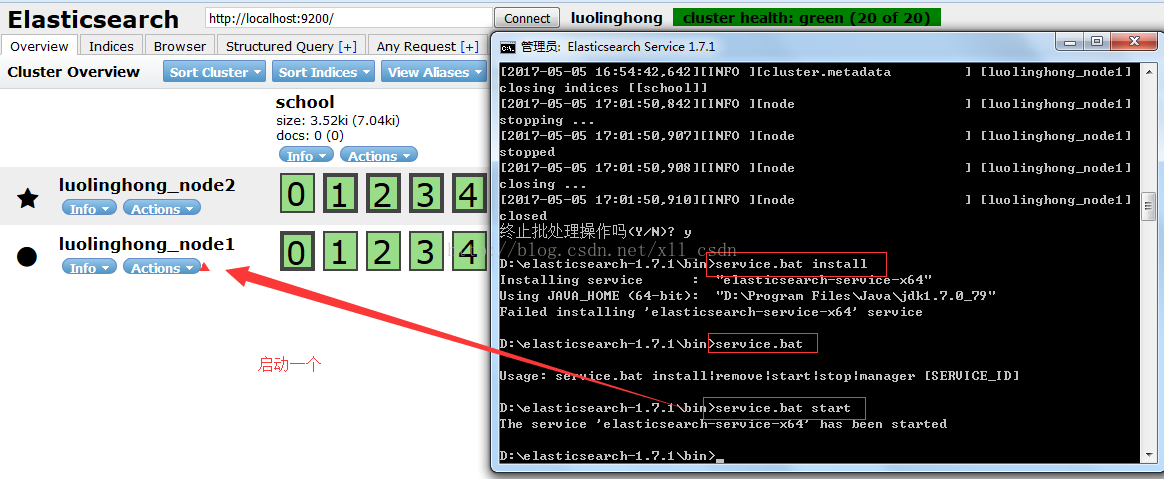
2.启动两个解压文件
3.访问,如图:
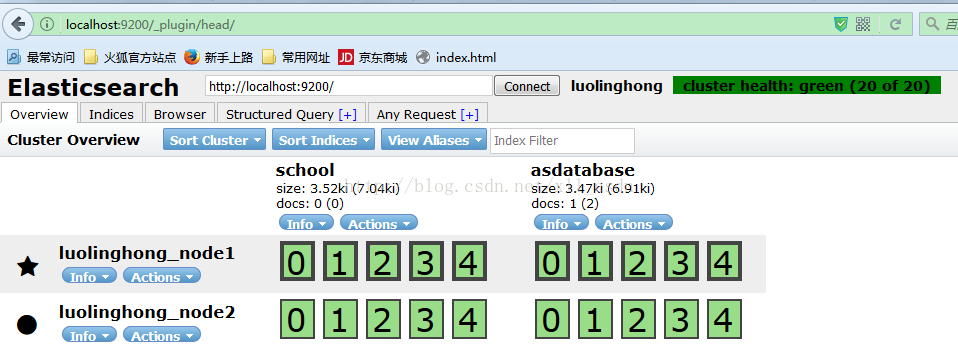
集群:
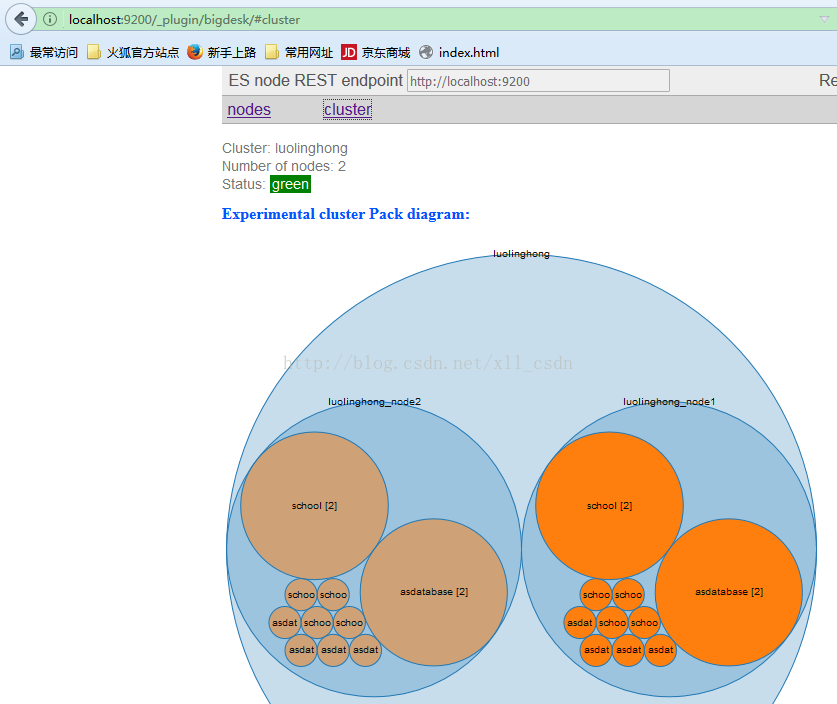
此时集群搭建成功!
关闭ES
1。上面介绍的ctrl+c是简单的关闭单个节点的方法。
2。杀掉服务器进程也是可以的,(参考Linux上的kill命令和Windows上的任务管理器)
3。下面看如何关闭整个集群。可以执行以下命令来关掉整个集群:
curl -XPOST http://localhost:9200/_cluster/nodes/_shutdown
head插件上,可以在页面直接操作,关闭节点。但是集群的关闭是没有直接提供快捷操作按钮的。
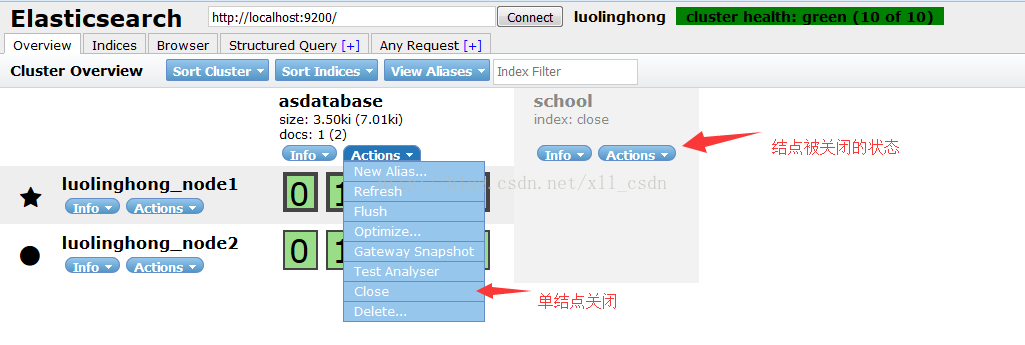
curl
在这里介绍一下curl在windows 64位的使用
下载curl http://curl.haxx.se/download.html
使用方式一:在curl.exe目录中使用
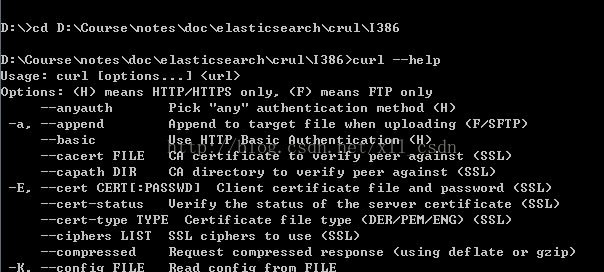
1. 解压下载后的压缩文件,通过cmd命令进入到curl.exe所在的目录。
由于我们使用的是windows 64位 的系统,因此可以使用I386下的curl.exe工具。
进入到该目录后,执行curl --help测试:
如图:
测试命令,前提是你的es服务打开了: curl -XGEThttp://localhost:9200/_cluster/state/nodes?pretty
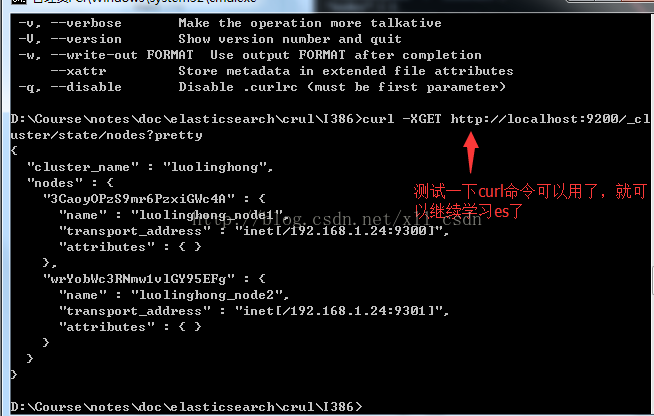
以上就是curl命令可以使用了,所以我们就可以使用
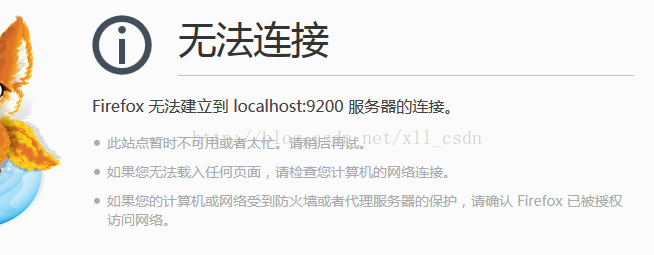
curl -XPOST http://localhost:9200/_cluster/nodes/_shutdown 命令关闭es集群了,如图:

关闭后就无法连接了,如图:
Elasticsearch 作为系统服务运行
在Windows上运行系统服务
转到Elasticsearch的安装目录,到bin子目录下,执行: service.bat install
如果你想看看所有被service.bat脚本文件暴露出来的命令,在相同目录下执行: service.bat
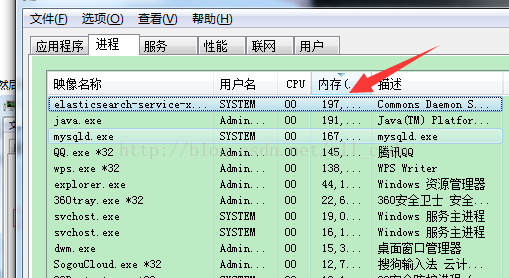
例如,为了启动Elasticsearch,可执行如下命令: service.bat start
然后查看任务管理器,看到出现了elasticsearch的服务已经出现了。因为刚刚已经启动了
Java的使用
1.首先安装Elasticsearch,配置相关文件,并启动服务
2.创建项目,导入相关Jar包
3.创建ElasticsearchUtils类,里面包括初始化操作和创建索引、更新索引、删除索引、查询索引
4.注意用完之后一定要将Client关闭
package elasticserarch.utils;
import org.elasticsearch.action.index.IndexRequestBuilder;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.ImmutableSettings;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.index.query.QueryBuilder;
public class ElasticsearchUtils {
private Client client;
/**
* 连接es
* @param clusterName 集群名字
* @param ipAddress IP地址
* ES操作服务器的两种方式,一种是使用Node方式,即本机也启动一个ES,然后跟服务器的ES进行通信,这个node甚至还能存储
* 下面介绍的这一种,通过一个对象使用http协议跟服务器进行交互。
*/
@SuppressWarnings("resource")//去除黄色警告
public ElasticsearchUtils(StringclusterName, StringipAddress) {
Settings settings = ImmutableSettings
.settingsBuilder()
//设置集群名称
.put("cluster.name", clusterName)
.put("client.transport.ignore_cluster_name",false)
.put("node.client", true).put("client.transport.sniff",true)
.build();
client = new TransportClient(settings).addTransportAddress(new InetSocketTransportAddress(ipAddress, 9300)); //此处端口号为9300
}
/**
* 创建索引
* @param indexName 索引名称,相当于数据库名称
* @param typeName 索引类型,相当于数据库中的表名
* @param id id名称,相当于每个表中某一行记录的标识
* @param jsonDatajson数据
*/
public void createIndex(StringindexName, StringtypeName, String id,String jsonData) {
IndexRequestBuilder requestBuilder =client.prepareIndex(indexName,typeName,id).setRefresh(true);//设置索引名称,索引类型,id
//创建索引库 需要注意的是.setRefresh(true)这里一定要设置,否则第一次建立索引查找不到数据
requestBuilder.setSource(jsonData).execute().actionGet();//创建索引
}
/**
* 执行搜索
* @param indexname 索引名称
* @param type 索引类型
* @param queryBuilder 查询条件
* @return
*/
public SearchResponse searcher(StringindexName, StringtypeName,
QueryBuilder queryBuilder) {
SearchResponse searchResponse =client.prepareSearch(indexName)
.setTypes(typeName).setQuery(queryBuilder).execute()
.actionGet();//执行查询
return searchResponse;
}
/**
* 更新索引
* @param indexName 索引名称
* @param typeName 索引类型
* @param id id名称
* @param jsonDatajson数据
*/
public void updateIndex(StringindexName, StringtypeName, String id,
String jsonData) {
UpdateRequest updateRequest =new UpdateRequest();
updateRequest.index(indexName);//设置索引名称
updateRequest.id(id);//设置id
updateRequest.type(typeName);//设置索引类型
updateRequest.doc(jsonData);//更新数据
client.update(updateRequest).actionGet();//执行更新
}
/**
* 删除索引
* @param indexName
* @param typeName
* @param id
*/
public void deleteIndex(StringindexName, StringtypeName, String id) {
client.prepareDelete(indexName,typeName,id).get();
client.close();
}
}
package elasticserarch.test;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import elasticserarch.utils.ElasticsearchUtils;
public class Test {
public static void main(String[]args) {
//创建对象,设置集群名称和IP地址
ElasticsearchUtils es = new ElasticsearchUtils("luolinghong","localhost");
String indexName = "asdatabase";//索引名称 (相当于数据库名称)索引名称不能大写,否则报错
String typeName = "AsTableName";//类型名称 (相当于数据库中的表名)
String id = "1";
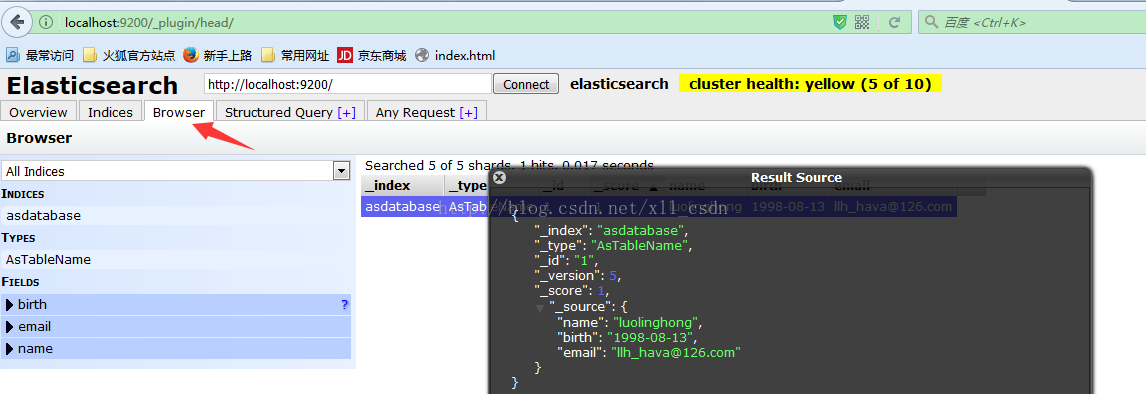
String jsonData = "{" + "\"name\":\"luolinghong\","
+ "\"birth\":\"1998-08-13\"," +"\"email\":\"llh_hava@126.com\""
+ "}";//json数据
//1.创建索引(ID可自定义也可以自动创建,此处使用自定义ID)
es.createIndex(indexName,typeName,id, jsonData);
System.out.println("创建索引成功!!");
//2.执行查询
//(1)创建查询条件
QueryBuilder queryBuilder = QueryBuilders.termQuery("name","luolinghong"); //搜索name为luolinghogn的数据
//(2)执行查询
long start=System.currentTimeMillis();
System.out.println("查询开始时间: "+start);
SearchResponse searchResponse =es.searcher(indexName,typeName,queryBuilder);
//(3)解析结果
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHitsearchHit :searchHits) {
String name = (String) searchHit.getSource().get("name");
String birth = (String) searchHit.getSource().get("birth");
String email = (String) searchHit.getSource().get("email");
System.out.println("名字:"+name +" 生日:"+birth+" 邮箱:"+email);
}
long end=System.currentTimeMillis();
long count=end-start;
System.out.println("查询结束时间:"+end +" 总用时:"+count);
System.out.println("已查询!!");
//3.更新数据
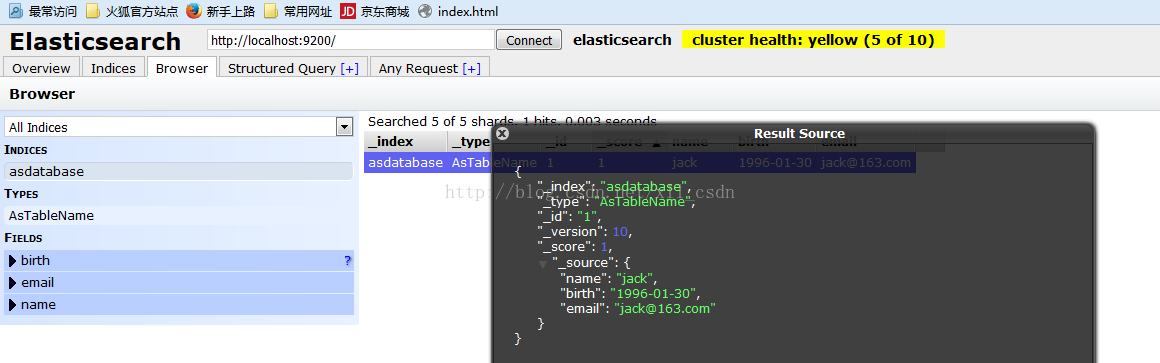
jsonData = "{" + "\"name\":\"jack\"," + "\"birth\":\"1996-01-30\","
+ "\"email\":\"jack@163.com\"" +"}";//json数据
es.updateIndex(indexName,typeName,id, jsonData);
//4.删除数据
es.deleteIndex(indexName,typeName,id);
}
}
创建索引成功,如图所示:
索引被更新,如图所示:















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









