






第一次等待异步内容加载,会下载chrome,网址原因,会报错
test0001.py :
from requests_html import HTMLSession
# 创建一个HTMLSession对象
session = HTMLSession()
# 用session打开一个URL
url = 'https://www.baidu.com/'
# hd = {"User-agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:92.0) Gecko/20100101 Firefox/92.0"}
response = session.get(url)
# 让浏览器渲染页面,等待异步内容加载
response.html.render()
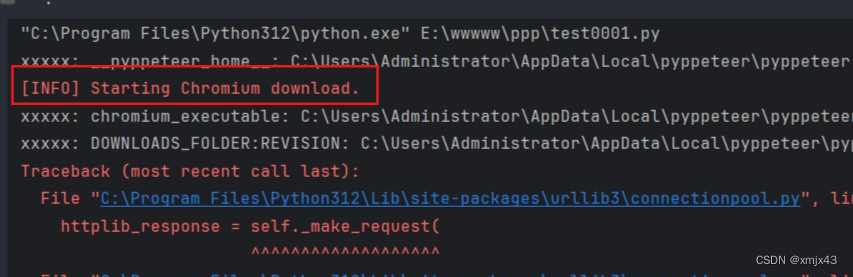
查看python安装目录下的chromium_downloader.py文件
........\Python312\Lib\site-packages\pyppeteer\chromium_downloader.py
打印执行地址
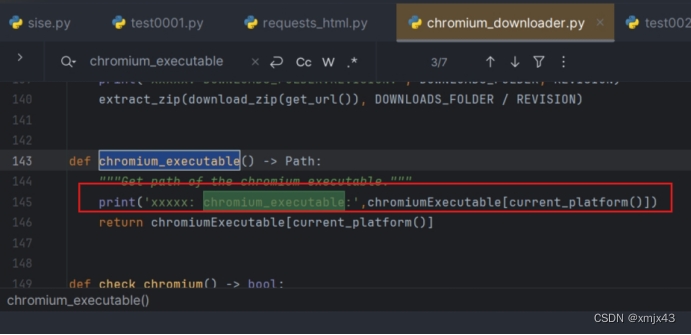
再次执行test0001.py 脚本,可以看到执行路径,手动下载一个chrome(CNPM Binaries Mirror (npmmirror.com)),解压后放到对应目录
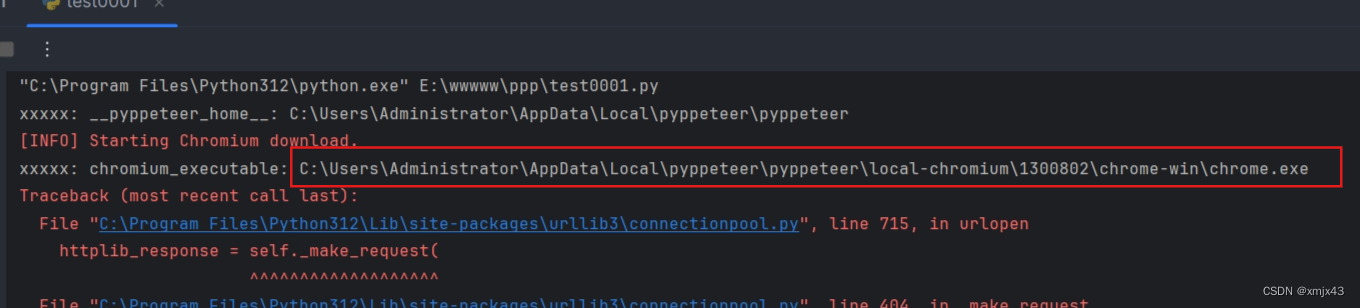
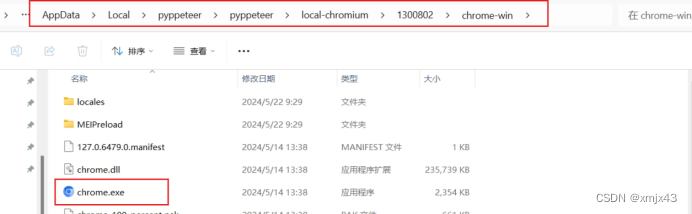
再次执行,正常运行
参考:https://blog.csdn.net/qq_51825761/article/details/136657125


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









