







网址:aHR0cHM6Ly93d3cubm1wYS5nb3YuY24vZGF0YXNlYXJjaC9ob21lLWluZGV4Lmh0bWw=
目录
本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请联系作者立即删除!
前言:
关于瑞数,真的不想讲太多了,往期的两篇文章4代5代详细讲解了瑞数的流程,都比较详细(出文章花了好几个小时,比我写作文都认真,很多粉丝都复现了),如果你4代都没有过请忽略这篇文章,因为一些重复的知识不想再啰嗦了,这次会简单的讲解r6的流程(补环境).另外写完这篇文章停更几个月(沉淀一段时间),如果有疑问可以在评论区交流讨论,我看到会及时回复的,另外,结尾附有联系方式,有需要可联系我.
瑞数简介

瑞数动态安全 Botgate(机器人防火墙)以“动态安全”技术为核心,通过动态封装、动态验证、动态混淆、动态令牌等技术对服务器网页底层代码持续动态变换,增加服务器行为的“不可预测性”,实现了从用户端到服务器端的全方位“主动防护”,为各类 Web、HTML5 提供强大的安全保护。瑞数 Botgate 多用于政企、金融、运营商行业,一度被视为反爬天花板.目前版本4.0,5.0,6.0,本章针对6.0
本期教学将带大家补环境过6.0
补环境与扣代码区别:
对于js逆向来说,这是两种常规且实用的手段,也各有优劣势;不管使用哪种方式,我们都是先从网站中将加密JS代码扣出,然后再选择是继续扣代码,将使用到的浏览器环境api进行逻辑替换;还是使用补环境,让加密JS代码仿佛在浏览器环境中运行。
- 扣代码与补环境都依赖对JS的熟练度,扣代码更侧重js语法和代码逻辑,补环境更侧重原型链及BOM、DOM对象的模拟。
- 扣代码熟练度依赖逆向经验,补环境几乎只依赖JS熟练度。
- 扣代码需要调试跟踪大量逻辑,对于rs,如果不解混淆的话,屁股得坐出痔疮;
- 由于瑞数是动态的,扣代码只能扣一份静态的,所以需要找到VM中使用到的所有动态属性进行映射。而补环境是通用的,补的越多,可通杀的网站就越多。
- 扣代码比补环境执行效率高,毕竟补环境的代码数比扣代码多很多,可以通过剔除不需要的环境来缩小差距;
- 扣代码人工耗时远高于补环境。
总而言之,扣代码侧重js语法和代码逻辑,其熟练度依赖于逆向经验,对不同网站要扣的不一样,难以通用,人工效率低,但是程序执行效率高。补环境侧重原型链及浏览器环境模拟,熟练度几乎只依赖对JS的原理掌握程度,对于不同网站补的越多可通杀的网站越多,人工效率巨高,但是程序执行效率不高。
声明
本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请联系作者立即删除!
篇幅较长,坐稳发车咯!
cookie咋生成的就不用管了,反正你是补环境,网上扣代码也有教程,只要你过了它的环境检测点就行了.
整体流程
1 打开网站,可以发现它是rs6代
2 打开无痕模式,提前打开开发者工具,把脚本勾上后输入网址回车,浏览器会在一系列相关文件断下来

3 这是我写文章的时候的第一个文件,这个顺序好像会变,昨天调的时候都不是这样的,不过影响不大
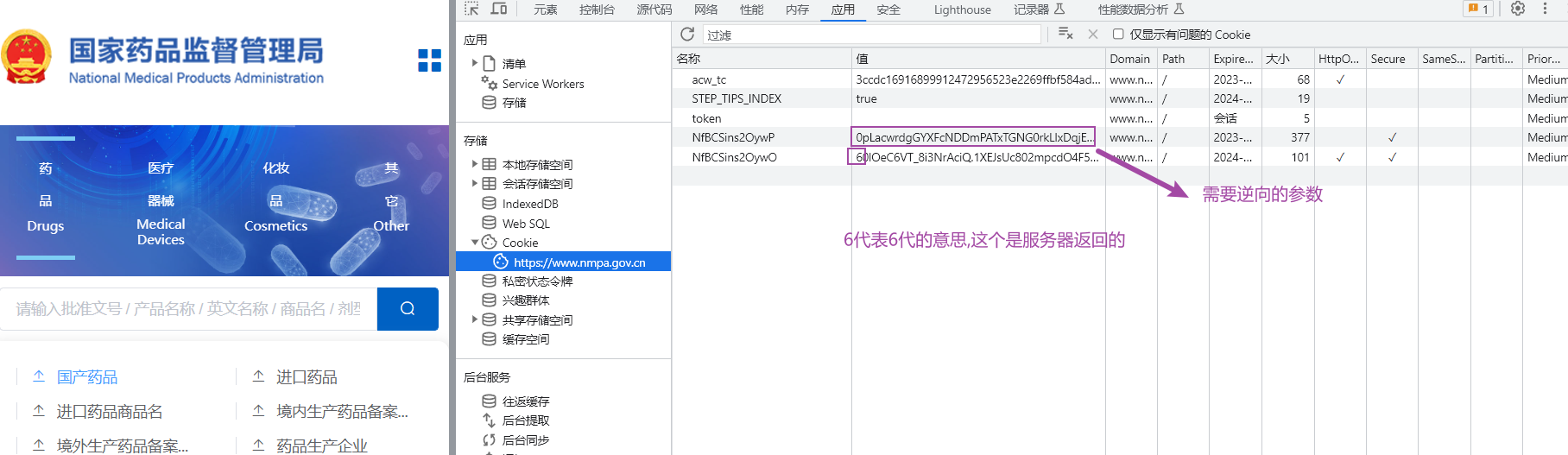
4 如图所示,此时需要注意应用的cookie值变化,这样你才能摸清楚cookie是哪些文件生成的,这样也可以方便你写爬虫程序,开发语音没有要求,推荐py.
5 接着f8继续执行
6 接着来看cookie,这两个都是服务器返回的,写pc程序得模拟携带这两个cookie值

7 接着执行 ,需要实时查看cookie的变化
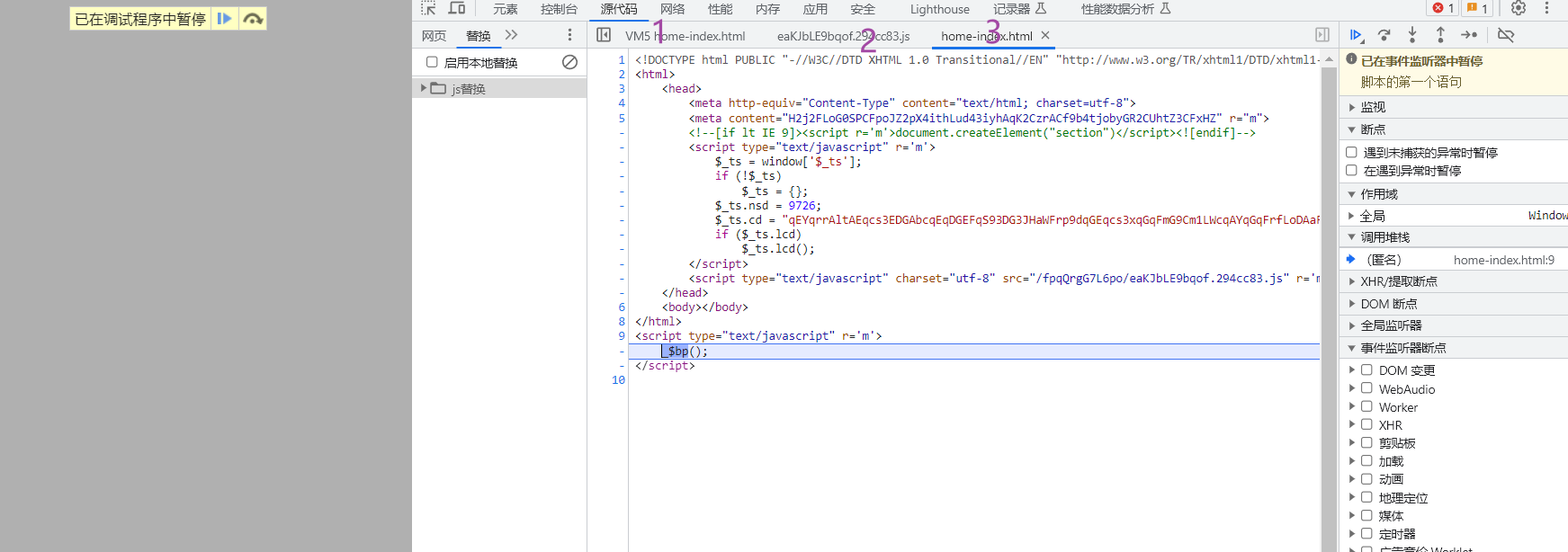 8 这里我执行3次就有结果了,但我昨天调的时候都不是这样的,中间还有其他文件,不过这个影响不大,只要实时注意cookie的变化就行了
8 这里我执行3次就有结果了,但我昨天调的时候都不是这样的,中间还有其他文件,不过这个影响不大,只要实时注意cookie的变化就行了

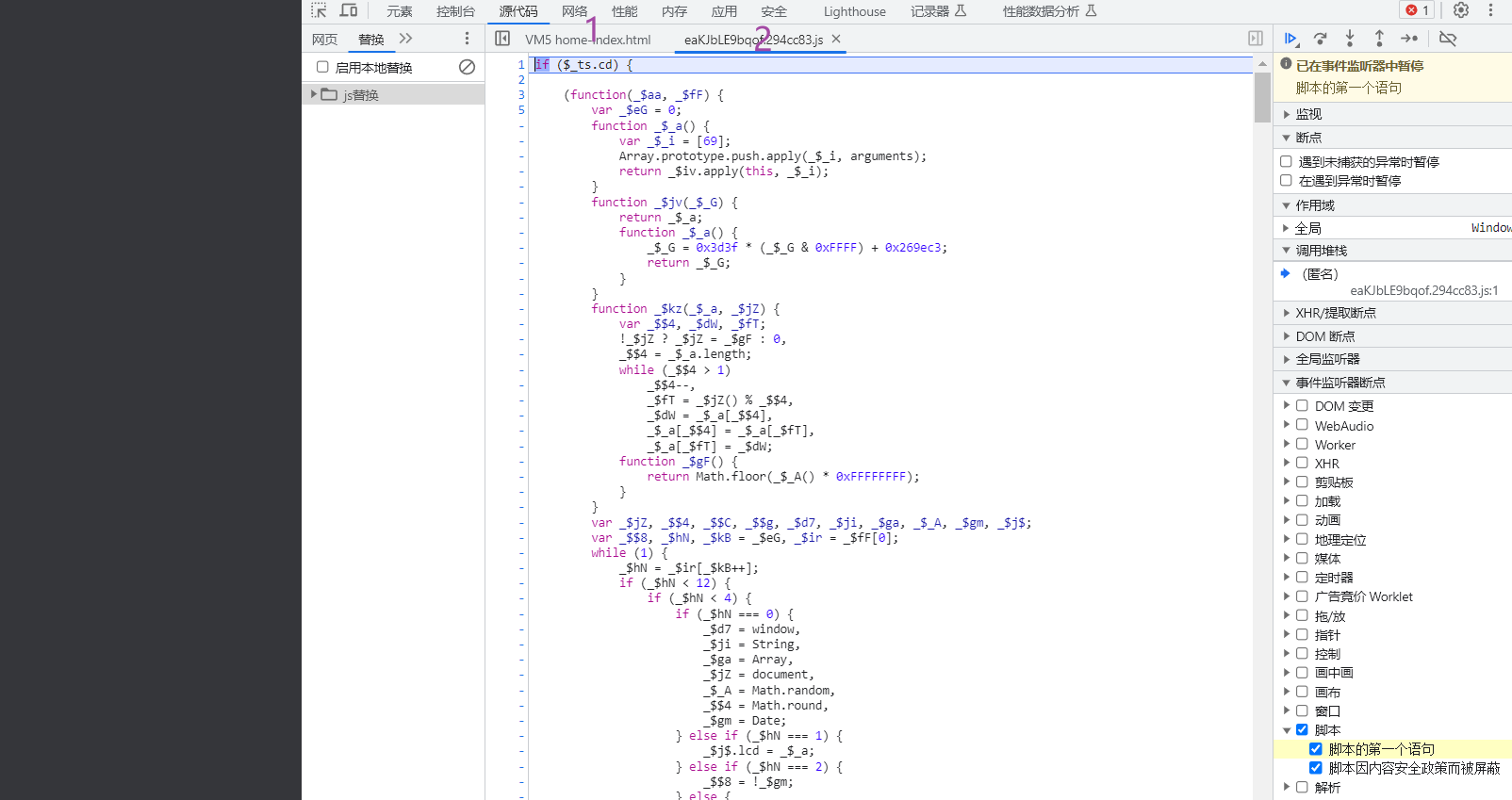
9 再来看抓包请求,外链js可以固定,content和ts属性每次都要换,还有ts属性一定要和content对应,否则你怎么补都是错的(非常重要)
10 接下来的内容就是补环境了,把这3个放在node里跑,缺啥补啥就行了,上代理补好点,node和浏览器一起调,这里我不想写了,和5代补的流程差不多,写5代的补环境调试了很久(太费劲了),可以参考5代的之前的文章,可以提示一下要补window,document,location,navigator,createment,getElememtByTagName,主要就是这些了,location和navigator简单,直接浏览器复制就行了,关键是dom
11 贴一张结果图吧


文章老是莫名被某sdn删掉,然后还审核不通过,后面估计发自己博客了


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











