







1、Pandas-DataFrame 基础
import numpy as np
import pandas as pd
# 建立 DataFrame
dic = {'uid': ['001', '002', '003', '006'],
'v01': [824, 12047, 3609, 1372],
'v02': [9, 3, 7, 2]
}
df = pd.DataFrame(dic) # 字典转化为DataFrame
# 外部文件读入DataFrame
dic2 = pd.read_csv('F:/u_value.txt', encoding='utf-8')
# 默认第一行为列名,即header=0 (header=1,配合names=[],指定列名),若第一行即为数据则header=None
# sep delimiter 指定分隔符
# dtype={'uid': object} dtype 指定字段格式
dic2.columns=['A','B','C'] # 修改列名
print(df) # 展示全部行
print(df.head()) # 显示前n行,默认5
ps: 数据左侧0 1 2 3 4 为索引号。
2、 访问 DataFrame 【loc iloc ix】
df_T = df.T # 转制
df.uid df['uid'] # 某一列
df[['uid', 'v01']] # 某(几)列
df.loc[[0,1]] # 索引号为 0 1 的行
df.loc[[0,1],['uid','v01']] # 索引号为 0 1 的某些字段的值
# 筛选访问
df[['uid','v01']][(df.uid.isin(['001', '003']))] #条件为uid.isin(['001', '003'])
df.loc[:, ['uid','v01']][(df.uid.isin(['001', '003']))]
# loc 方式
df.loc[df.uid.isin(['001', '003']), ['uid', 'v01']]
## ps:loc[] 通过索引号索引名、列名进行访问
## iloc[] 通过行列索引号访问3、DataFrame的合并与聚合
# -----合并-----
df_new = pd.merge(df, dic2, how='left', left_on='uid', right_on='A').drop(['A', 'B', 'v02'], axis=1)
df_new = df_new[['uid', 'v01', 'C']] # 列重新排序
df_new.columns = ['uid', 'v01', 'v02']
# how 合并方式,左/右连接
# left_on right_on 连接的字段
# 出现相同名称的字段,分别以加 _x _y 全部出现,可以通过drop删除不必要字段
# 其他字段可通过columns重命名。
df_buff = df_new.append(df_test)
# 将df_new和df_test连个表合成一个表,(有新字段结果就生成新字段)
# ------聚合-----
df_buff.groupby('uid').sum() # 其他值都合计
# 对不同列进行不同的聚合
df_groupby = df_buff.groupby('uid').agg({'uid': [np.size, pd.Series.nunique], 'v01': np.max, 'v02': np.sum})
df_groupby.columns = ['u_cnt', 'u_dis_cnt', 'max_v01', 'sum_v02'] # 重命名聚合列
4、DataFrame的排序
# 排序生成新数据集
df_sort = df_groupby.sort_values(by='max_v01', ascending=False)
# 多列排序 df_groupby.sort_values(['max_v01', 'sum_v02'], ascending=[True, False])
# 在原数据集增加排名列(num)
df_groupby['num'] = df_groupby['max_v01'].rank(ascending=1)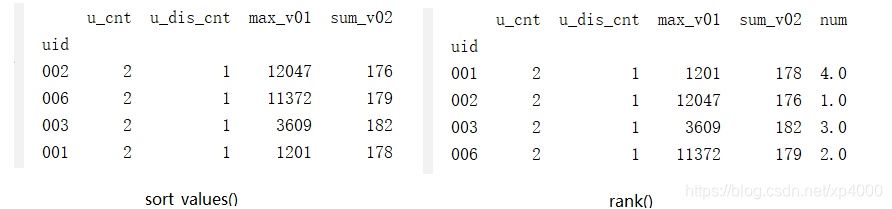
# 分组排序,(sql窗口函数)
df_2_sort['num'] = df_2_sort['v01'].groupby(df_2_sort['uid']).rank(ascending=False, method='first')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









