







实例要求:
爬取小猪短租的房源链接以及每条房源链接的详情
详情爬取信息要求如下图:
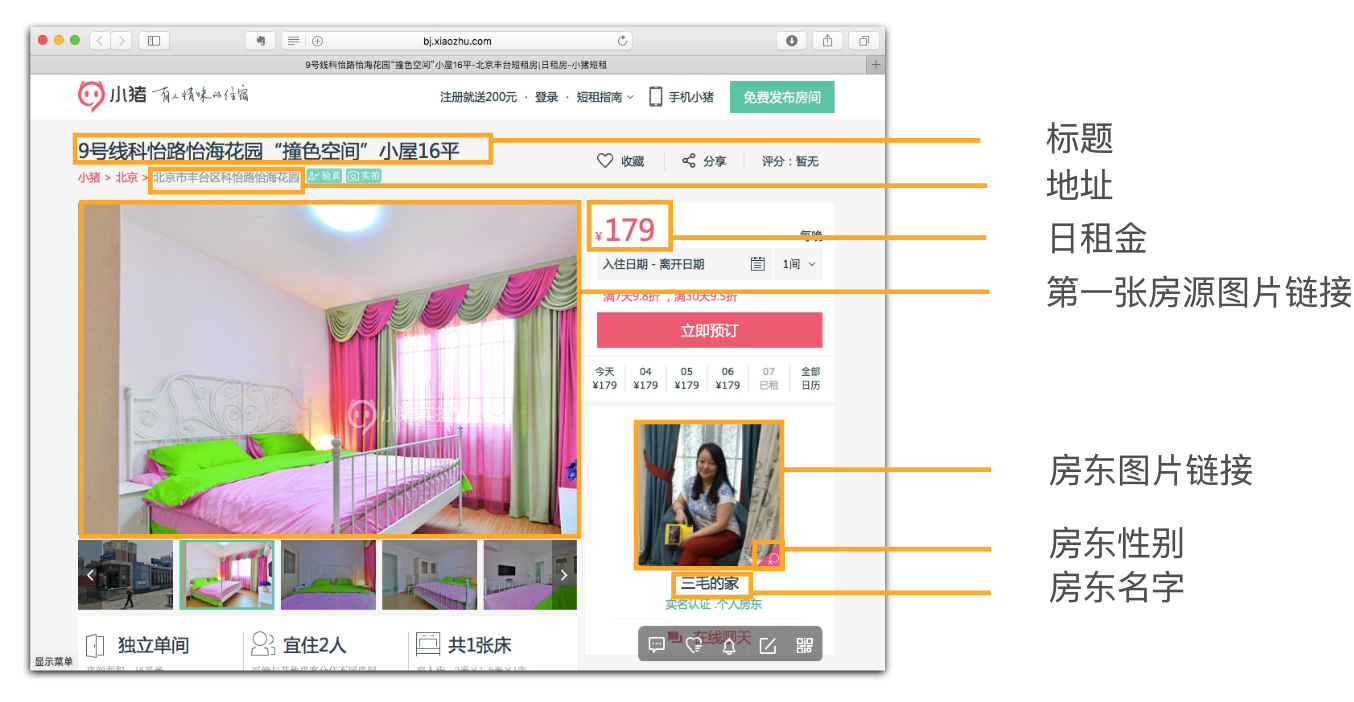
爬取代码如下:
from bs4 import BeautifulSoup
import requests
import time
urls = ['http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(str(i)) for i in range(1,14,1)]
def get_info(concrete_url):
wb_data = requests.get(concrete_url)
soup = BeautifulSoup(wb_data.text)
first_imgs = soup.select('div.pho_show_big > div[valign="middle"] > img')
titles = soup.select('div.pho_info > h4')
addresses = soup.select('span.pr5')
daymoneys = soup.select('div.day_l > span')
hostimgs = soup.select('div.member_pic > a[target="_blank"] > img')
sexes = soup.select('div.member_pic > div')
hostnames=soup.select('a.lorder_name')
for first_img, title, address, daymoney, hostimg, hostsex, hostname in zip(first_imgs,titles,addresses,daymoneys,hostimgs,sexes,hostnames):
if hostsex.get('class')[0]=='member_ico1':
hostsexone = '男'
if hostsex.get('class')[0]=='member_ico':
hostsexone = '女'
if hostsex.get('class')[0]=='':
hostsexone = ' 暂无'
concreteinfo={
'房源图片':first_img.get('src'),
'房屋标题': title.get_text(),
'地址':address.get_text().strip(),
'日租金':daymoney.get_text(),
'房东照片':hostimg.get('src'),
'房东性别':hostsexone,
'房东名字':hostname.get_text()
}
print(concreteinfo)
def get_urllist(url):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text)
url_fangzis = soup.select('a.resule_img_a')
for url_fangzi in url_fangzis:
data={
'url':url_fangzi.get('href')
}
get_info(data.get('url'))
time.sleep(4)
for url_one in urls:
get_urllist(url_one)
爬取结果如下:



















 1240
1240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









