







系列文章目录
文章目录
Abstract
去噪扩散模型(DDMs)在 3D 点云合成中展现出良好效果。为推进 3D DDMs 并使其适用于数字艺术,需满足:(i) 高生成质量,(ii) 操作灵活性(如条件合成和形状插值),(iii) 输出光滑表面或网格的能力。为此,我们提出用于 3D 形状生成的分层潜在点扩散模型(LION)。LION 构建为具有分层潜在空间的变分自编码器(VAE),结合 全局形状潜在表示(global shape latent) 和 点结构潜在空间(point cloud-structrued latent) 。生成时,在这些潜在空间训练两个分层 DDMs。分层 VAE 方法相比直接在点云上操作的 DDMs 性能更优,同时点结构潜在空间仍适用于 DDM 建模。实验表明,LION 在多个 ShapeNet 基准上达到 SOTA。VAE 框架使其易于适应不同任务:LION 擅长多模态形状去噪和体素条件合成,可适配文本 / 图像驱动的 3D 生成。还演示了形状自动编码和潜在形状插值,并结合现代表面重建技术生成光滑网格。我们希望 LION 凭借高质量生成、灵活性和表面重建能力,成为 3D 内容创作的有力工具。项目页面和代码:https://nv-tlabs.github.io/LION。
提示:以下是本篇文章正文内容,下面案例可供参考
Ⅰ INTRODUCTIOIN
3D形状的生成式建模在3D内容创作中有着广泛的应用,并且已经成为一个活跃的研究领域[1 - 52]。然而,要成为数字艺术家可用的工具,3D形状的生成模型必须满足几个标准:(i)生成的形状需要逼真且高质量,没有瑕疵。(ii)模型应支持灵活的交互式使用和优化:例如,用户可能希望优化生成的形状,并合成具有不同细节程度的版本。或者,艺术家可能会提供一个粗糙或有噪声的输入形状,从而引导模型生成多个逼真的高质量输出。同样,用户可能想要对不同的形状进行插值操作。(iii)模型应输出光滑的网格,这是大多数图形软件中的标准表示形式。
现有的3D生成模型基于各种框架构建,包括生成对抗网络(GANs)[1 - 23]、变分自编码器(VAEs)[24 - 30]、归一化流(Normalizing Flows)[31 - 34]、自回归模型(Autoregressive Models)[35 - 38]以及更多[39 - 44]。最近,去噪扩散模型(DDMs)已成为强大的生成模型,不仅在图像合成[53 - 64]方面取得了出色的成果,在基于点云的3D形状生成[45 - 47]中也表现优异。在DDMs中,数据通过扩散过程逐渐受到扰动,同时训练一个深度神经网络进行去噪。当从随机噪声初始化时,这个网络可以以迭代的方式用于合成新的数据[53, 65 - 67]。然而,现有的用于3D形状合成的DDMs难以同时满足上述对于实际有用的3D生成模型所讨论的所有标准。
在这里,我们旨在开发一种基于DDM的3D形状生成模型(Latent Point Diffusion Model, LION),克服这些限制。我们引入了用于3D形状生成的潜在点扩散模型(LION)(见图1)。与之前的3D DDMs类似,LION在点云(point clouds)上进行操作,但它被构建为一个在潜在空间中包含DDMs的VAE。LION包含一个分层的潜在空间(a hierarchical latent space),其中有一个向量值的全局形状潜在变量(vector-valued global shape latent)和另一个点结构的潜在空间(point-structured latent space)。潜在表示通过点云处理编码器(point cloud processing encoders)进行预测,并且在这些潜在空间中训练两个潜在DDMs。LION中的合成过程是通过从分层潜在DDMs中绘制新的潜在样本,然后解码回原始点云空间来实现的。重要的是,我们还展示了如何使用现代表面重建方法[68]增强LION,以合成艺术家期望的光滑形状。LION具有多个优点:
- 表现力Expressivity:通过将点云映射到正则化的潜在空间(regularized latent spaces)中,潜在空间中的DDMs实际上是在学习一个平滑的分布。这比直接在可能复杂的点云上进行训练更容易[58],从而提高了模型的表现力。然而,从原理上讲,点云是DDMs的理想表示形式。因此,我们使用潜在点,即我们的主要潜在表示保留点云结构。以分层的方式为模型添加额外的全局形状潜在变量(additional global shape latent variable加粗样式**)进一步提升了表现力。我们在几个流行的ShapeNet基准测试中对LION进行了验证,并实现了最先进的合成性能。
即不是在点云上训练DDMs,而是在潜在空间中使用latent point训练DDM
- 输出类型多样Varying Output Types:通过使用“Shape As Points”(SAP)[68]几何重建技术扩展LION,我们还可以输出光滑的网格。在LION的自动编码器生成的数据上对SAP进行微调,可以减少合成噪声,并使我们能够生成高质量的几何图形。LION将基于(潜在)点云的建模(这对DDMs来说是理想的)与表面重建(这是艺术家期望的)相结合。
- 灵活性Flexibility:由于LION被构建为一个VAE,它可以轻松适应不同的任务,而无需重新训练潜在的DDMs:我们可以在体素化或有噪声的输入上有效地微调LION的编码器,用户可以提供这些输入作为指导。这实现了多模态体素引导的合成和形状去噪。我们还利用LION的潜在空间进行形状插值和自动编码。可选地,基于CLIP嵌入训练DDMs可以实现图像和文本驱动的3D生成。
总之,我们做出了以下贡献:(i)我们引入了LION,这是一种用于3D形状合成的新型生成模型,它在点云上运行,并基于具有两个潜在DDMs的分层VAE框架构建。(ii)我们通过在广泛使用的ShapeNet基准测试中达到最先进的性能,验证了LION的高合成质量。(iii)即使在没有条件限制的情况下,对多个类进行联合训练时,LION也能实现高质量和多样化的3D形状合成。(iv)我们提出将LION与基于SAP的表面重建相结合。(v)我们通过将其应用于相关任务(如多模态体素引导的合成),展示了我们框架的灵活性。
Ⅱ Background
2. 背景
传统上,去噪扩散模型(DDMs)是以离散步骤discrete-step的方式引入的:给定从数据分布中采样得到的样本
x
0
∼
q
(
x
0
)
x_{0} \sim q(x_{0})
x0∼q(x0) ,DDMs使用马尔可夫固定正向扩散过程,定义为[65, 53]:
q
(
x
1
:
T
∣
x
0
)
:
=
∏
t
=
1
T
q
(
x
t
∣
x
t
−
1
)
,
q
(
x
t
∣
x
t
−
1
)
:
=
N
(
x
t
;
1
−
β
t
x
t
−
1
,
β
t
I
)
q\left(x_{1: T} | x_{0}\right):=\prod_{t = 1}^{T} q\left(x_{t} | x_{t - 1}\right), q\left(x_{t} | x_{t - 1}\right):=\mathcal{N}\left(x_{t} ; \sqrt{1-\beta_{t}} x_{t - 1}, \beta_{t} I\right)
q(x1:T∣x0):=t=1∏Tq(xt∣xt−1),q(xt∣xt−1):=N(xt;1−βtxt−1,βtI)
其中
T
T
T表示步骤数,
q
(
x
t
∣
x
t
−
1
)
q(x_{t} | x_{t - 1})
q(xt∣xt−1)是高斯转移核,它按照方差调度
β
1
,
.
.
.
,
β
T
\beta_{1}, ..., \beta_{T}
β1,...,βT逐渐向输入添加噪声。选择
β
t
\beta_{t}
βt的值,使得该链在
T
T
T步后近似收敛到标准高斯分布,即
q
(
x
T
)
≈
N
(
x
T
;
0
,
I
)
q(x_{T}) \approx N(x_{T} ; 0, I)
q(xT)≈N(xT;0,I)。DDMs学习一个参数化的反向过程(模型参数为
θ
\theta
θ),用于反转正向扩散:
p
θ
(
x
0
:
T
)
:
=
p
(
x
T
)
∏
t
=
1
T
p
θ
(
x
t
−
1
∣
x
t
)
,
p
θ
(
x
t
−
1
∣
x
t
)
:
=
N
(
x
t
−
1
;
μ
θ
(
x
t
,
t
)
,
ρ
t
2
I
)
p_{\theta}\left(x_{0: T}\right):=p\left(x_{T}\right) \prod_{t = 1}^{T} p_{\theta}\left(x_{t - 1} | x_{t}\right), p_{\theta}\left(x_{t - 1} | x_{t}\right):=\mathcal{N}\left(x_{t - 1} ; \mu_{\theta}\left(x_{t}, t\right), \rho_{t}^{2} I\right)
pθ(x0:T):=p(xT)t=1∏Tpθ(xt−1∣xt),pθ(xt−1∣xt):=N(xt−1;μθ(xt,t),ρt2I)
这个生成性的反向过程也是具有高斯转移核的马尔可夫过程,它使用固定的方差 ρ t 2 \rho_{t}^{2} ρt2。DDMs可以被解释为潜在变量模型(latent variable models),其中 x 1 , . . . , x T x_{1}, ..., x_{T} x1,...,xT是潜在变量,正向过程 q ( x 1 : T ∣ x 0 ) q(x_{1: T} | x_{0}) q(x1:T∣x0)作为固定的近似后验分布,生成性的 p θ ( x 0 : T ) p_{\theta}(x_{0: T}) pθ(x0:T)与之拟合。DDMs通过最小化在 p θ ( x 0 : T ) p_{\theta}(x_{0: T}) pθ(x0:T)下数据 x 0 x_{0} x0的负对数似然的变分上界来进行训练。忽略不相关的常数项,这个目标函数可以表示为[53]:
在DDMs里,把 x 1 , . . . , x T x_{1}, ..., x_{T} x1,...,xT看作潜在变量 。正向扩散过程 q ( x 1 : T ∣ x 0 ) q(x_{1: T} | x_{0}) q(x1:T∣x0)逐步对初始数据 x 0 x_{0} x0添加噪声,将其转化为一系列不同噪声程度的样本 x 1 , . . . , x T x_{1}, ..., x_{T} x1,...,xT。这个过程就像是把
原始数据编码到由这些不同噪声程度样本构成的“潜在空间”中,每个 x t x_{t} xt都是潜在变量的一种体现,代表了原始数据在不同噪声状态下的特征。生成性的反向过程 p θ ( x 0 : T p_{\theta}(x_{0: T} pθ(x0:T)则试图从这些潜在变量中恢复出原始数据 x 0 x_{0} x0,就像VAE中从潜在表示解码出原始数据一样。
m i n θ E t ∼ U { 1 , T } , x 0 ∼ p ( x 0 ) , ϵ ∼ N ( 0 , I ) [ w ( t ) ∥ ϵ − ϵ θ ( α t x 0 + σ t ϵ , t ) ∥ 2 2 ] , w ( t ) = β t 2 2 ρ t 2 ( 1 − β t ) ( 1 − α t 2 ) min _{\theta} \mathbb{E}_{t \sim U\{1, T\}, x_{0} \sim p\left(x_{0}\right), \epsilon \sim \mathcal{N}(0, I)}\left[w(t)\left\| \epsilon-\epsilon_{\theta}\left(\alpha_{t} x_{0}+\sigma_{t} \epsilon, t\right)\right\| _{2}^{2}\right], w(t)=\frac{\beta_{t}^{2}}{2 \rho_{t}^{2}\left(1-\beta_{t}\right)\left(1-\alpha_{t}^{2}\right)} minθEt∼U{1,T},x0∼p(x0),ϵ∼N(0,I)[w(t)∥ϵ−ϵθ(αtx0+σtϵ,t)∥22],w(t)=2ρt2(1−βt)(1−αt2)βt2
α t x 0 + σ t ϵ \alpha_t x_0 + \sigma_t \epsilon αtx0+σtϵ是前向扩散过程第 t t t 步的样本 x t x_t xt,即:
x t = α t x 0 + σ t ϵ ( 由 α t = ∏ s = 1 t ( 1 − β s ) , σ t = 1 − α t 2 导出 ) x_t = \alpha_t x_0 + \sigma_t \epsilon \quad (\text{由 } \alpha_t = \sqrt{\prod_{s=1}^t (1-\beta_s)}, \sigma_t = \sqrt{1-\alpha_t^2} \text{ 导出}) xt=αtx0+σtϵ(由 αt=s=1∏t(1−βs),σt=1−αt2 导出)
权重 w ( t ) w(t) w(t) 是从变分下界(ELBO)推导中自然出现的项,其形式为:
w ( t ) = β t 2 2 ρ t 2 ( 1 − β t ) ( 1 − α t 2 ) w(t) = \frac{\beta_t^2}{2 \rho_t^2 (1-\beta_t)(1-\alpha_t^2)} w(t)=2ρt2(1−βt)(1−αt2)βt2
• 分母项: ρ t 2 \rho_t^2 ρt2 是反向过程高斯分布的方差(通常设为 β t \beta_t βt 或 σ t 2 \sigma_t^2 σt2); ( 1 − β t ) ( 1 − α t 2 ) (1-\beta_t)(1-\alpha_t^2) (1−βt)(1−αt2) 来自前向过程参数 α t \alpha_t αt 和 β t \beta_t βt 的累积效应。
• 实际简化: 论文指出,通常将 w ( t ) w(t) w(t) 设为 1(即忽略复杂分母),这种简化: 提高训练稳定性(避免分母趋近零导致数值爆炸)。偏向生成质量(感知上更关注高频细节)。
该公式直接通过 x 0 x_0 x0 和 ϵ \epsilon ϵ 计算 x t x_t xt,无需逐步迭代前向过程。均方误差(MSE)衡量预测噪声 ϵ θ \epsilon_\theta ϵθ 与真实噪声 ϵ \epsilon ϵ 的差距,权重 w ( t ) w(t) w(t) 调节不同时间步的重要性。
变分上界的理论背景
目标是最大化数据 x 0 x_0 x0 的似然 p θ ( x 0 ) p_\theta(x_0) pθ(x0),但直接计算似然困难(需积分所有潜在变量):
log p θ ( x 0 ) = log ∫ p θ ( x 0 : T ) d x 1 : T \log p_\theta(x_0) = \log \int p_\theta(x_{0:T}) \, dx_{1:T} logpθ(x0)=log∫pθ(x0:T)dx1:T
通过引入变分分布 q ( x 1 : T ∣ x 0 ) q(x_{1:T} | x_0) q(x1:T∣x0),构建证据下界(ELBO):
log p θ ( x 0 ) ≥ ELBO = E q ( x 1 : T ∣ x 0 ) [ log p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) ] \log p_\theta(x_0) \geq \text{ELBO} = \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log \frac{p_\theta(x_{0:T})}{q(x_{1:T}|x_0)} \right] logpθ(x0)≥ELBO=Eq(x1:T∣x0)[logq(x1:T∣x0)pθ(x0:T)]
最小化负的ELBO(即变分上界)等价于最大化数据似然。即最小化变分上界等价于让生成分布 p θ p_\theta pθ 尽可能匹配前向过程 q q q
其中 α t = ∏ s = 1 t ( 1 − β s ) \alpha_{t}=\sqrt{\prod_{s = 1}^{t}(1-\beta_{s})} αt=∏s=1t(1−βs) , σ t = 1 − α t 2 \sigma_{t}=\sqrt{1-\alpha_{t}^{2}} σt=1−αt2是经过 t t t步后可处理的扩散分布 q ( x t ∣ x 0 ) = N ( x t ; α t x 0 , σ t 2 I ) q(x_{t} | x_{0})=N(x_{t} ; \alpha_{t} x_{0}, \sigma_{t}^{2} I) q(xt∣x0)=N(xt;αtx0,σt2I)的参数。此外,公式(3)采用了广泛使用的参数化形式 μ θ ( x t , t ) : = 1 1 − β t ( x t − β t 1 − α t 2 ϵ θ ( x t , t ) ) \mu_{\theta}(x_{t}, t):=\frac{1}{\sqrt{1-\beta_{t}}}(x_{t}-\frac{\beta_{t}}{\sqrt{1-\alpha_{t}^{2}}} \epsilon_{\theta}(x_{t}, t)) μθ(xt,t):=1−βt1(xt−1−αt2βtϵθ(xt,t))。通常的做法是将 w ( t ) w(t) w(t)设为1,而不是公式(3)中的值,这通常有助于提升生成输出的感知质量。在公式(3)的目标函数中,对于扩散过程中的所有可能步骤 t t t,模型 ϵ θ \epsilon_{\theta} ϵθ实际上是在被训练来预测对观察到的扩散样本 x t x_{t} xt进行去噪所需的噪声向量 ϵ \epsilon ϵ。训练完成后,DDMs可以通过祖先采样以迭代方式进行采样:
x
t
−
1
=
1
1
−
β
t
(
x
t
−
β
t
1
−
α
t
2
ϵ
θ
(
x
t
,
t
)
)
+
ρ
t
η
x_{t - 1}=\frac{1}{\sqrt{1-\beta_{t}}}\left(x_{t}-\frac{\beta_{t}}{\sqrt{1-\alpha_{t}^{2}}} \epsilon_{\theta}\left(x_{t}, t\right)\right)+\rho_{t} \eta
xt−1=1−βt1(xt−1−αt2βtϵθ(xt,t))+ρtη
这里
η
∼
N
(
η
;
0
,
I
)
\eta \sim N(\eta ; 0, I)
η∼N(η;0,I)。此外,在最后一步采样中,公式(4)中的噪声注入通常会被省略。
DDMs也可以用连续时间框架来表示[67, 69]。在这种表述中,扩散和反向生成过程由微分方程描述。这种方法允许基于常微分方程(ODEs)进行确定性采样和编码。我们将在3.1节中使用这个框架,并在附录B中更详细地回顾这种方法。
ⅢHierarchical Latent Point Diffusion Models 分层潜在点扩散模型
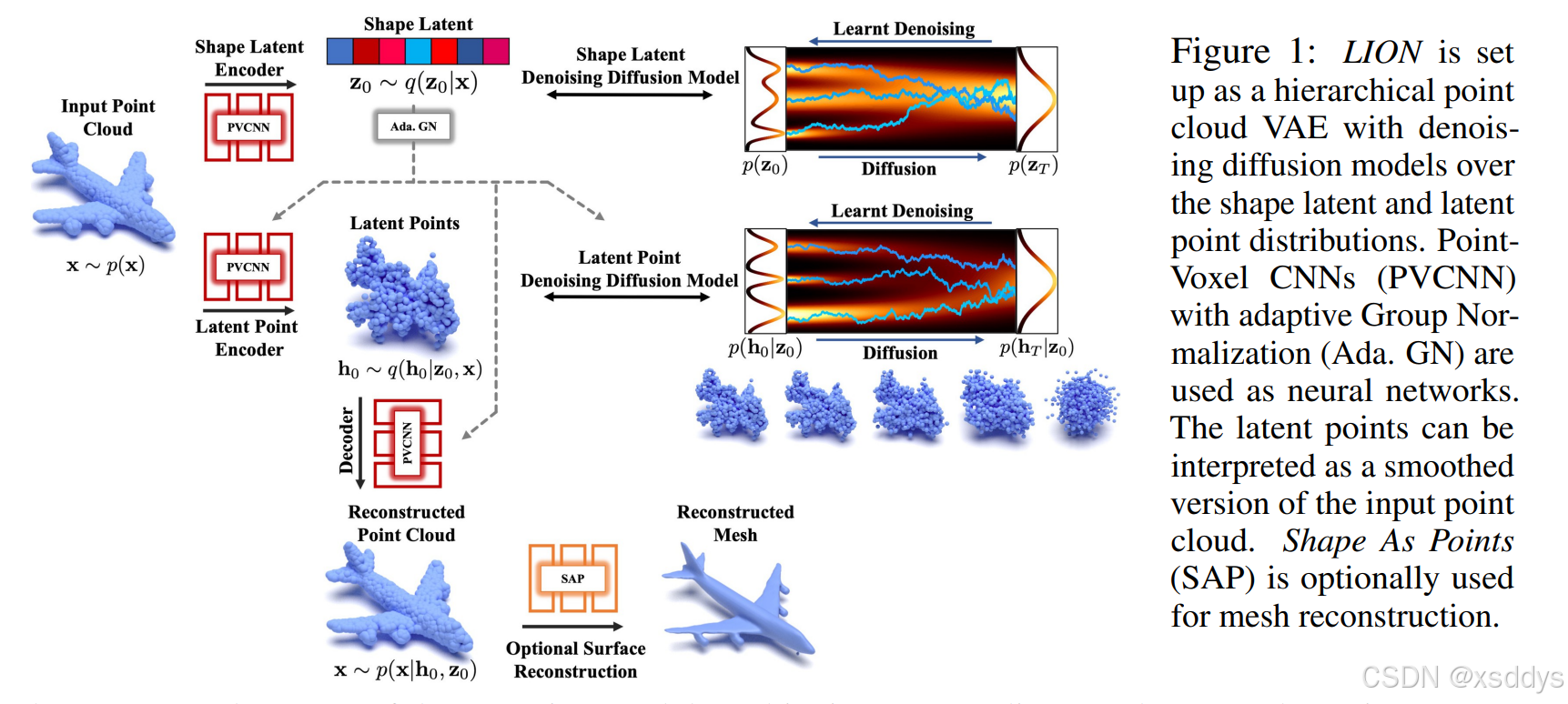
LION的运作流程如下:
- 输入阶段
将输入点云 x ∼ p ( x ) \mathbf{x} \sim p(\mathbf{x}) x∼p(x)作为起始数据,这是具有三维坐标的点的集合,代表3D形状的一种表示形式 。- 编码阶段
- 全局形状潜在变量编码:输入点云通过基于点 - 体素卷积神经网络(PVCNN)的形状潜在编码器(Shape Latent Encoder)进行处理,得到全局形状潜在变量 z 0 \mathbf{z}_0 z0 , z 0 ∼ q ( z 0 ∣ x ) \mathbf{z}_0 \sim q(\mathbf{z}_0|\mathbf{x}) z0∼q(z0∣x) ,这里使用自适应组归一化(Ada. GN )技术 。
- 潜在点编码:同时,输入点云还会通过潜在点编码器(Latent Point Encoder,同样基于PVCNN ),在以 z 0 \mathbf{z}_0 z0和输入点云 x \mathbf{x} x为条件下,得到潜在点云 h 0 \mathbf{h}_0 h0 , h 0 ∼ q ( h 0 ∣ z 0 , x ) \mathbf{h}_0 \sim q(\mathbf{h}_0|\mathbf{z}_0, \mathbf{x}) h0∼q(h0∣z0,x) 。潜在点云 h 0 \mathbf{h}_0 h0可以看作是输入点云的平滑版本。
- 扩散与去噪阶段
- 全局形状潜在变量处理:对全局形状潜在变量Shape Latent z 0 \mathbf{z}_0 z0 ,通过形状潜在去噪扩散模型(Shape Latent Denoising Diffusion Model)进行操作。在扩散过程中,从初始分布 p ( z 0 ) p(\mathbf{z}_0) p(z0)逐渐转变为 p ( z T ) p(\mathbf{z}_T) p(zT) ;在去噪过程中,模型学习将噪声样本恢复到原始状态,实现从噪声中重建有意义的全局形状潜在表示 。
- 潜在点处理:对于潜在点云 h 0 \mathbf{h}_0 h0 ,利用潜在点去噪扩散模型(Latent Point Denoising Diffusion Model) 。同样经历从初始分布 p ( h 0 ∣ z 0 ) p(\mathbf{h}_0|\mathbf{z}_0) p(h0∣z0)到 p ( h T ∣ z 0 ) p(\mathbf{h}_T|\mathbf{z}_0) p(hT∣z0)的扩散,以及反向的去噪过程,学习从噪声中恢复潜在点云的准确表示 。
- 解码与重建阶段
- 点云重建:经过处理的潜在点云( h 0 \mathbf{h}_0 h0和全局形状潜在变量 z 0 \mathbf{z}_0 z0 ,通过基于PVCNN的解码器(Decoder) ,得到重建点云 x ∼ p ( x ∣ h 0 , z 0 ) \mathbf{x} \sim p(\mathbf{x}|\mathbf{h}_0, \mathbf{z}_0) x∼p(x∣h0,z0),这是对原始输入点云的重建 。
- 可选的网格重建:如果需要得到网格形式的3D模型,可使用“Shape As Points(SAP)”方法进行可选的表面重建(Optional Surface Reconstruction) ,将重建点云转换为重建网格(Reconstructed Mesh)。
我们首先正式介绍LION,然后在3.1节讨论其各种应用和扩展,最后在3.2节总结其独特优势。LION的可视化见图1。
我们对由
N
N
N个点组成、点的
x
y
z
xyz
xyz坐标在
R
3
\mathbb{R}^3
R3空间中的点云
x
∈
R
3
×
N
\mathbf{x} \in \mathbb{R}^{3 \times N}
x∈R3×N进行建模。LION被构建为一个分层变分自编码器(VAE),在潜在空间中包含去噪扩散模型(DDMs) 。它使用一个向量值的全局形状潜在变量
z
0
∈
R
D
z
\mathbf{z}_0 \in \mathbb{R}^{D_z}
z0∈RDz(a vector-valued global shape latent) ,以及一个点云结构的潜在变量
h
0
∈
R
(
3
+
D
h
)
×
N
\mathbf{h}_0 \in \mathbb{R}^{(3 + D_h) \times N}
h0∈R(3+Dh)×N(a point cloud-structured latent)。具体而言,
h
0
\mathbf{h}_0
h0是一个潜在点云,由
N
N
N个
x
y
z
xyz
xyz坐标在
R
3
\mathbb{R}^3
R3空间中的点组成。此外,每个潜在点可以携带额外的
D
h
D_h
Dh个潜在特征。LION的训练分两个阶段进行:首先,我们将其作为具有标准高斯先验的常规VAE进行训练;然后,我们在潜在编码上训练潜在DDMs。
First Stage Training. Initially, LION is trained by maximizing a modified variational lower bound on
the data log-likelihood (ELBO) with respect to the encoder and decoder parameters φ and ξ [70, 71]:
Here, the global shape latent z0 is sampled from the posterior distribution qφ(z0|x), which is
parametrized by factorial Gaussians, whose means and variances are predicted via an encoder network.
The point cloud latent h0 is sampled from a similarly parametrized posterior qφ(h0|x, z0), while also
conditioning on z0 (φ denotes the parameters of both encoders). Furthermore, pξ(x|h0, z0) denotes
the decoder, parametrized as a factorial Laplace distribution with predicted means and fixed unit scale
parameter (corresponding to an L1 reconstruction loss). λz and λh are hyperparameters balancing
reconstruction accuracy and Kullback-Leibler regularization (note that only for λz = λh = 1 we are
optimizing a rigorous ELBO). The priors p(z0) and p(h0) are N (0, I). Also see Fig. 1 again
第一阶段训练。最初,LION通过相对于编码器和解码器参数
ϕ
\boldsymbol{\phi}
ϕ和
ξ
\boldsymbol{\xi}
ξ最大化数据对数似然的修正变分下界(ELBO)来进行训练[70, 71]:
L
ELBO
(
ϕ
,
ξ
)
=
E
p
(
x
)
,
q
ϕ
(
z
0
∣
x
)
,
q
ϕ
(
h
0
∣
x
,
z
0
)
[
log
p
ξ
(
x
∣
h
0
,
z
0
)
−
λ
z
D
KL
(
q
ϕ
(
z
0
∣
x
)
∣
p
(
z
0
)
)
−
λ
h
D
KL
(
q
ϕ
(
h
0
∣
x
,
z
0
)
∣
p
(
h
0
)
)
]
\begin{align*} \mathcal{L}_{\text{ELBO}}(\boldsymbol{\phi}, \boldsymbol{\xi}) & = \mathbb{E}_{p(\mathbf{x}), q_{\boldsymbol{\phi}}(\mathbf{z}_0|\mathbf{x}), q_{\boldsymbol{\phi}}(\mathbf{h}_0|\mathbf{x}, \mathbf{z}_0)} \big[ \log p_{\boldsymbol{\xi}}(\mathbf{x}|\mathbf{h}_0, \mathbf{z}_0) \\ & \quad - \lambda_{\mathbf{z}} D_{\text{KL}} \big( q_{\boldsymbol{\phi}}(\mathbf{z}_0|\mathbf{x}) \big| p(\mathbf{z}_0) \big) - \lambda_{\mathbf{h}} D_{\text{KL}} \big( q_{\boldsymbol{\phi}}(\mathbf{h}_0|\mathbf{x}, \mathbf{z}_0) \big| p(\mathbf{h}_0) \big) \big] \end{align*}
LELBO(ϕ,ξ)=Ep(x),qϕ(z0∣x),qϕ(h0∣x,z0)[logpξ(x∣h0,z0)−λzDKL(qϕ(z0∣x)
p(z0))−λhDKL(qϕ(h0∣x,z0)
p(h0))]
这里,global shape latent
z
0
\mathbf{z}_0
z0从后验分布posterior distribution
q
ϕ
(
z
0
∣
x
)
q_{\boldsymbol{\phi}}(\mathbf{z}_0|\mathbf{x})
qϕ(z0∣x)中采样,该分布由因子高斯分布参数化,其均值和方差由一个编码器网络预测。点云潜在变量
h
0
\mathbf{h}_0
h0从同样参数化的后验分布
q
ϕ
(
h
0
∣
x
,
z
0
)
q_{\boldsymbol{\phi}}(\mathbf{h}_0|\mathbf{x}, \mathbf{z}_0)
qϕ(h0∣x,z0)中采样,同时以
z
0
\mathbf{z}_0
z0为条件
(
ϕ
(\boldsymbol{\phi}
(ϕ表示两者的参数)。此外,解码器
p
ξ
(
x
∣
h
0
,
z
0
)
p_{\boldsymbol{\xi}}(\mathbf{x}|\mathbf{h}_0, \mathbf{z}_0)
pξ(x∣h0,z0)由具有预测均值和固定单位尺度参数(对应
L
1
L_1
L1重建损失)的因子拉普拉斯分布参数化。
λ
z
\lambda_{\mathbf{z}}
λz和
λ
h
\lambda_{\mathbf{h}}
λh是平衡重建精度和Kullback - Leibler正则化的超参数(注意,仅当
λ
z
=
λ
h
=
1
\lambda_{\mathbf{z}} = \lambda_{\mathbf{h}} = 1
λz=λh=1时,我们才在优化严格的ELBO)。先验分布
p
(
z
0
)
p(\mathbf{z}_0)
p(z0)和
p
(
h
0
)
p(\mathbf{h}_0)
p(h0)是
N
(
0
,
I
)
\mathcal{N}(0, \mathbf{I})
N(0,I)。也可再次参考图1。
Second Stage Training. In principle, we could use the VAE’s priors to sample encodings and
generate new shapes. However, the simple Gaussian priors will not accurately match the encoding
distribution from the training data and therefore produce poor samples (prior hole problem [58, 72–
79]). This motivates training highly expressive latent DDMs. In particular, in the second stage we
freeze the VAE’s encoder and decoder networks and train two latent DDMs on the encodings z0 and
h0 sampled from qφ(z0|x) and qφ(h0|x, z0), minimizing score matching (SM) objectives similar to
Eq. (2):
第二阶段训练。原则上,我们可以使用VAE的先验来采样编码并生成新形状。然而,简单的高斯先验不能准确匹配来自训练数据的编码分布,这会导致样本出现先验空洞问题(prior hole problem)[58, 72 - 79] 。这促使我们训练高度表达性的潜在DDMs。具体来说,我们冻结VAE的编码器和解码器网络,并在从
q
ϕ
(
z
0
∣
x
)
q_{\boldsymbol{\phi}}(\mathbf{z}_0|\mathbf{x})
qϕ(z0∣x)和
q
ϕ
(
h
0
∣
x
,
z
0
)
q_{\boldsymbol{\phi}}(\mathbf{h}_0|\mathbf{x}, \mathbf{z}_0)
qϕ(h0∣x,z0)采样得到的编码
z
0
\mathbf{z}_0
z0和
h
0
\mathbf{h}_0
h0上训练两个潜在DDMs,最小化类似于公式(2)的得分匹配(SM)目标:
L
SM
(
θ
)
=
E
t
∼
U
{
1
,
T
}
,
p
(
x
)
,
q
ϕ
(
z
0
∣
x
)
,
ϵ
∼
N
(
0
,
I
)
[
∥
ϵ
−
ϵ
θ
(
z
t
,
t
)
∥
2
2
]
L
SM
+
(
ψ
)
=
E
t
∼
U
{
1
,
T
}
,
p
(
x
)
,
q
ϕ
(
z
0
∣
x
)
,
q
ϕ
(
h
0
∣
x
,
z
0
)
,
ϵ
∼
N
(
0
,
I
)
[
∥
ϵ
−
ϵ
ψ
(
h
t
,
z
0
,
t
)
∥
2
2
]
\begin{align*} \mathcal{L}_{\text{SM}}(\boldsymbol{\theta}) & = \mathbb{E}_{t \sim U\{1, T\}, p(\mathbf{x}), q_{\boldsymbol{\phi}}(\mathbf{z}_0|\mathbf{x}), \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})} \big[ \| \boldsymbol{\epsilon} - \boldsymbol{\epsilon}_{\boldsymbol{\theta}}(\mathbf{z}_t, t) \|_2^2 \big] \\ \mathcal{L}_{\text{SM}^+}(\boldsymbol{\psi}) & = \mathbb{E}_{t \sim U\{1, T\}, p(\mathbf{x}), q_{\boldsymbol{\phi}}(\mathbf{z}_0|\mathbf{x}), q_{\boldsymbol{\phi}}(\mathbf{h}_0|\mathbf{x}, \mathbf{z}_0), \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})} \big[ \| \boldsymbol{\epsilon} - \boldsymbol{\epsilon}_{\boldsymbol{\psi}}(\mathbf{h}_t, \mathbf{z}_0, t) \|_2^2 \big] \end{align*}
LSM(θ)LSM+(ψ)=Et∼U{1,T},p(x),qϕ(z0∣x),ϵ∼N(0,I)[∥ϵ−ϵθ(zt,t)∥22]=Et∼U{1,T},p(x),qϕ(z0∣x),qϕ(h0∣x,z0),ϵ∼N(0,I)[∥ϵ−ϵψ(ht,z0,t)∥22]
其中
z
t
=
α
t
z
0
+
σ
t
ϵ
\mathbf{z}_t = \alpha_t \mathbf{z}_0 + \sigma_t \boldsymbol{\epsilon}
zt=αtz0+σtϵ且
h
t
=
α
t
h
0
+
σ
t
ϵ
\mathbf{h}_t = \alpha_t \mathbf{h}_0 + \sigma_t \boldsymbol{\epsilon}
ht=αth0+σtϵ是扩散后的潜在编码。此外,
θ
\boldsymbol{\theta}
θ表示全局形状潜在DDM
ϵ
θ
(
z
t
,
t
)
\boldsymbol{\epsilon}_{\boldsymbol{\theta}}(\mathbf{z}_t, t)
ϵθ(zt,t)的参数,
ψ
\boldsymbol{\psi}
ψ表示在潜在点云(注意以
z
0
\mathbf{z}_0
z0为条件)上训练的条件DDM
ϵ
ψ
(
h
t
,
z
0
,
t
)
\boldsymbol{\epsilon}_{\boldsymbol{\psi}}(\mathbf{h}_t, \mathbf{z}_0, t)
ϵψ(ht,z0,t)的参数。
这段的意思大致是,我们凭借VAE的先验高斯分布完全可以干这件事情(采样重建),但是由于VAE的先验高斯分布太简单而DDMs具有更好的表达性,因此我们额外在VAE的潜在空间训练了两个DDMs。但是据DDMs最后添加完噪声后也是一个纯粹的高斯分布,去噪的时候也是从高斯分布中采样。为什么DDMs相对于VAE的先验高斯分布来说具有更好的表达性呢?
一种可能的答案如下:第一是因为DDMs可能会学习到更复杂的多种分布叠加的表示比如数据的多模态特性(即数据可能由多个不同分布混合而成),从而丰富潜在空间表达能力。 第二是DDMs生成(去噪)是一个迭代过程,每次迭代都根据当前噪声状态调整预测,逐步逼近真实数据。相比之下VAE是直接一步到位从先验高斯中采样。
生成。有了潜在DDMs,我们可以正式定义一个分层生成模型 p ξ , θ , ψ ( x , h 0 , z 0 ) = p ξ ( x ∣ h 0 , z 0 ) p θ ( h 0 ∣ z 0 ) p ψ ( z 0 ) p_{\boldsymbol{\xi}, \boldsymbol{\theta}, \boldsymbol{\psi}}(\mathbf{x}, \mathbf{h}_0, \mathbf{z}_0) = p_{\boldsymbol{\xi}}(\mathbf{x}|\mathbf{h}_0, \mathbf{z}_0) p_{\boldsymbol{\theta}}(\mathbf{h}_0|\mathbf{z}_0) p_{\boldsymbol{\psi}}(\mathbf{z}_0) pξ,θ,ψ(x,h0,z0)=pξ(x∣h0,z0)pθ(h0∣z0)pψ(z0) ,其中 p θ ( h 0 ∣ z 0 ) p_{\boldsymbol{\theta}}(\mathbf{h}_0|\mathbf{z}_0) pθ(h0∣z0)是全局形状潜在DDM的分布, p ψ ( h 0 ∣ z 0 ) p_{\boldsymbol{\psi}}(\mathbf{h}_0|\mathbf{z}_0) pψ(h0∣z0)是对表示点云结构的潜在变量进行建模的DDM, p ξ ( x ∣ h 0 , z 0 ) p_{\boldsymbol{\xi}}(\mathbf{x}|\mathbf{h}_0, \mathbf{z}_0) pξ(x∣h0,z0)是LION的解码器。我们可以按照公式(4)分层采样潜在DDMs,然后使用解码器将潜在点转换回原始点云空间。
网络架构和DDM参数化。让我们简要总结关键的实现选择。在点云 x \mathbf{x} x上操作的编码器网络,以及解码器和潜在点DDM,都基于点 - 体素卷积神经网络(Point-Voxel CNNs,PVCNNs)[80]实现,遵循Zhou等人[46]的方法。PVCNN有效地将基于点的PointNet [81, 82]的点云处理与具有强空间感应偏差的卷积相结合。全局形状潜在DDM的网络架构使用带有全连接层(实现为 1 × 1 1 \times 1 1×1卷积)的ResNet [83] 。在PVCNN层中,所有对全局形状潜在变量的条件操作都通过自适应组归一化[84]实现。此外,遵循Vahdat等人[58]的方法,我们在两个潜在DDM中使用混合得分参数化。这意味着得分模型被参数化,以预测对解析标准高斯得分的残差校正。这在第一阶段训练期间有利于潜在编码趋向标准高斯分布(详细信息见附录D)。
3.1 应用与扩展
在此,我们探讨LION如何用于不同的相关应用以及进行扩展。
多模态生成Multimodal Generation:我们能够合成给定形状的不同变体,以可控的方式实现多模态生成。具体来说,给定一个形状,即其点云
x
\mathbf{x}
x,我们将其编码到潜在空间中。然后,在扩散过程中,将其编码
z
0
\mathbf{z}_0
z0和
h
0
\mathbf{h}_0
h0扩散少量步数
τ
<
T
\tau < T
τ<T ,得到中间状态
z
τ
\mathbf{z}_\tau
zτ和
h
τ
\mathbf{h}_\tau
hτ,此过程仅破坏局部细节。从这个中间状态
τ
\tau
τ开始,以
z
τ
\mathbf{z}_\tau
zτ和
h
τ
\mathbf{h}_\tau
hτ为起点运行反向生成过程,可得到具有不同细节的原始形状变体(例如,见图2)。我们将此过程称为“扩散 - 去噪”(详细内容见附录C.1)。类似技术已应用于图像编辑[85]。

用于体素条件合成和去噪的编码器微调Encoder Fine-tuning for Voxel-Conditioned Synthesis and Denoising:在实际应用中,使用3D生成模型的艺术家可能对期望的形状有一个大致的概念。例如,他们或许能够快速构建一个粗糙的体素化形状,然后由生成模型添加逼真的细节。在LION中,我们可以支持这类应用:使用与公式(5)类似的ELBO,但解码器保持冻结状态,我们可以微调LION的编码器网络,使其将体素化形状作为输入(我们只需在体素化形状的表面放置点),并将其映射到相应的潜在编码 z 0 \mathbf{z}_0 z0和 h 0 \mathbf{h}_0 h0,以重建原始的非体素化点云。现在,用户可以利用微调后的编码器对体素化形状进行编码,并生成合理的细节形状。重要的是,这可以与“扩散 - 去噪”过程自然结合,以清理不完美的编码,并生成不同的可能细节形状(见图4)。
此外,这种方法具有通用性。除了体素条件合成,我们还可以在有噪声的形状上微调编码器网络,以进行多模态形状去噪,同样也可能与“扩散 - 去噪”相结合。由于LION基于带有额外编码器和解码器的VAE框架,它能够轻松支持这些应用,而无需重新训练潜在DDMs,这与之前直接在点云上训练DDMs的工作[46, 47]不同。技术细节见附录C.2。
形状插值Shape Interpolation:LION还支持形状插值。我们可以将不同的点云编码到LION的分层潜在空间中,并使用概率流常微分方程(ODE,见附录B)进一步将其编码到潜在DDMs的高斯先验中,在此我们可以安全地进行球面插值,并期望在插值路径上得到有效的形状。我们可以使用中间编码来生成插值形状(见图7;详细内容见附录C.3)。
表面重建:虽然点云是DDMs理想的3D表示形式,但艺术家可能更倾向于网格输出。因此,我们提议将LION与现代几何重建方法相结合(见图2、图4和图5)。我们使用“Shape As Points (SAP)” [68]方法,该方法基于可微泊松表面重建,经过训练能够从含噪点云中提取光滑的网格。此外,我们在LION的自动编码器生成的训练数据上对SAP进行微调,以更好地调整SAP在LION生成的点云中的噪声分布。具体来说,我们将形状编码到潜在空间中,运行几步仅轻微修改某些细节的“扩散 - 去噪”操作,然后再解码回来。潜在空间中的“扩散 - 去噪”会在生成的点云中产生类似于无条件合成时观察到的噪声(详细内容见附录C.4)。
3.2 LION的优势
我们现在总结LION的独特优势。LION作为一个在潜在空间中包含DDMs的分层VAE,其结构灵感来源于图像上的潜在DDMs [57, 58, 77] 。这个框架具有以下关键优势:
(i)表现力:首先训练一个VAE,将潜在编码正则化,使其近似服从标准高斯分布,而这也是DDMs扩散过程最终收敛的平衡分布,这使得DDMs的建模任务更简单:它们只需对实际编码分布与自身高斯先验之间的剩余差异进行建模 [58] 。这提升了模型的表现力,而额外的解码器网络进一步增强了这种表现力。然而,从原理上讲,点云是DDM框架的理想表示形式,因为它们易于进行扩散和去噪,且存在强大的点云处理架构。因此,LION使用点云潜在变量,结合了潜在DDMs和3D点云的优势。我们的点云潜在变量可被视为原始点云的平滑版本,更易于建模(见图1)。此外,带有额外全局形状潜在变量的分层VAE架构进一步提高了LION的表现力,并且在由形状潜在变量和潜在点捕捉到的整体形状与局部细节之间实现了自然分离(5.2节)。
(ii)灵活性:LION的VAE框架的另一个优势是其编码器可以针对各种相关任务进行微调,如前所述,并且它还能轻松实现形状插值。其他直接在点云上运行的3D点云DDMs [47, 46] ,在开箱即用的情况下,无法同时提供如此高的灵活性和表现力(见5.1节和5.4节的定量比较)。
(iii)网格重建:如前所述,虽然点云对DDMs来说是理想的,但艺术家可能更喜欢网格输出。正如上面所解释的,我们提议将LION与现代表面重建技术 [68] 结合使用,再次融合两者的优点——一个对DDMs来说理想的基于点云的VAE架构,以及对合成点云进行操作的平滑几何重建方法,以生成实际可用的平滑表面,这些表面可以轻松转换为网格。
Reference
提示:这里对文章进行总结:
[58]. Arash Vahdat, Karsten Kreis, and Jan Kautz. Score-based generative modeling in latent space. In Advances in Neural Information Processing Systems, 2021.
[80]. Zhijian Liu, Haotian Tang, Yujun Lin, and Song Han. Point-voxel cnn for efficient 3d deep learning. In Advances in Neural Information Processing Systems, 2019.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









