






在论文“A Speaker-Independent, Syntax-Directed, Connected Word Recognition System Based on Hidden Markov Models and Level Building”中提到动态规划来解决HMM连接词识别问题,文中提到:

上面的一步已经实现,在第二层的动态规划中,有点迷惑了。。
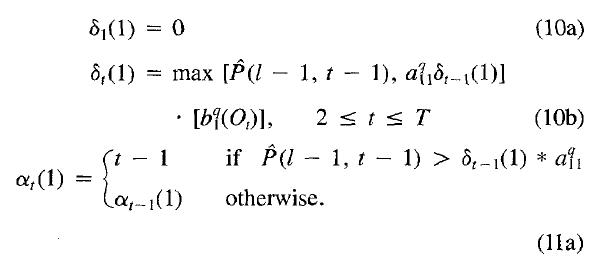
详细的代码如下:
function [Pr,Br,Wr] = levelBuilding(hmms,O)
% hmms:HMM模型集合
% O:观测序列
% 返回值: Pr:最佳累积距离;Br:最佳累积距离对应的帧;Wr:最佳词序列
T= size(O,1); %语音帧数,观测序列长度
K=length(hmms);%HMM模型个数
L=7; %最大层数,即词数
%At level l=1
%Initialization
P=-inf(L,T,K);
B=zeros(L,T,K);
Pr=-inf(L,T); %保存最优概率
Br=zeros(L,T);
Wr=zeros(L,T);
delta=cell(1,K);
fai=cell(1,K); %记录状态
init=cell(1,K);
trans=cell(1,K);
%初始化
for i=1:K
hmm=hmms{i}.hmm; %第i个隐马尔可夫模型的状态数
delta{i}=zeros(T,hmm.N); %第i个模型的token
%初始化第i个模型的第一个状态的概率,转换为对数形式
fai{i}= zeros(T,hmm.N);
init{i}=hmm.init;
trans{i}=hmm.trans;
ind1 = find(init{i}>0);
ind0 = find(init{i}<=0);
init{i}(ind0) = -inf;
init{i}(ind1) = log(init{i}(ind1));
%初始化第i个模型的的转移概率
ind1 = find(trans{i}>0);
ind0 = find(trans{i}<=0);
trans{i}(ind0) = -inf;
trans{i}(ind1) = log(trans{i}(ind1));
end
x = O(1,:);
for k=1:K
for i=1:hmms{k}.hmm.N %每个HMM的状态数
delta{k}(1,i) = init{k}(i) + log(mixture(hmms{k}.hmm.mix(i),x)); %初始化前向概率矩阵,初始状态概率乘以t=1时观测序列的输出概率
end
end
delta1=delta; %保存初始值,以免迭代覆盖
for t=2:T %从第二个观测序列开始
for k=1:K
for j = 1:hmms{k}.hmm.N %对该模型的所有状态
[delta{k}(t,j), fai{k}(t,j)]= max(delta{k}(t-1,:) + trans{k}(:,j)');%找出t-1时刻所有状态最大的前向概率与转移的矩阵kk
x = O(t,:);
delta{k}(t,j) = delta{k}(t,j) + log(mixture(hmms{k}.hmm.mix(j),x)); %记录第k个词的最大距离
end
P(1,t,k)=delta{k}(t,hmms{k}.hmm.N);
B(1,t,k)=0; %保存帧号还是0??
end
[pm,q]=max(P(1,t,1:K));
Pr(1,t)=pm;
Br(1,t)=B(1,t,q);
Wr(1,t)=q;
end
%%%%%%%%%%%%%%%%%%%%%%level=1 End%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%level=2 开始。。。。。
%Initialization
delta2(1,1:4)=0; belta(1,1:4)=0;
for l=2:L
for t=2:T %从第二个观测序列开始
temp=-inf; wi=0;
for k=1:K
if trans{k}(1,1)+delta2(t-1,1)>temp
temp=trans{k}(1,1)+delta2(t-1,1);
wi=k;
end
end
%[pb,ind]=max(trans{1:K}(1,1)+delta2(t-1,1));
x=O(t,:);
[va,ind]=max([Pr(l-1,t-1) temp]);
delta2(t,1)=va+log(mixture(hmms{wi}.hmm.mix(1),x));
if ind==1
belta(t,1)=t-1;
else
belta(t,1)=belta(t-1,1);
end
%%递归
for k=1:K
for j = 1:hmms{k}.hmm.N %对该模型的所有状态
[vm,vd]=max(delta2(t-1,:)+ trans{k}(:,j)');
x=O(t,:);
delta2(t,j)=vm+log(mixture(hmms{k}.hmm.mix(j),x));
belta(t,j)=belta(t-1,vd);
end
P(l,t,k)=delta2(t,hmms{k}.hmm.N);
B(l,t,k)=belta(t,hmms{k}.hmm.N); %保存帧号还是0??
end
%%结束递归
end
[pm,q]=max(P(l,t,1:K));
Pr(l,t)=pm;
Br(l,t)=B(l,t,q);
Wr(l,t)=q;
end
% disp(delta2);
end















 2196
2196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









