







概述
摘要: 上文我们对Kube-scheduler的启动流程进行了分析,本文继续探究kube-scheduler执行pod的调度任务的过程。
正文
说明:基于 kubernetes
v1.12.0源码分析
上文讲到kube-scheduler组件通过sched.Run() 启动调度器实例。在sched.Run() 中循环的执行sched.scheduleOne获取一个pod,并执行Pod的调度任务。
源码位置k8s.io/kubernetes/cmd/kube-scheduler/scheduler.go
// Run begins watching and scheduling. It waits for cache to be synced, then starts a goroutine and returns immediately.
func (sched *Scheduler) Run() {
if !sched.config.WaitForCacheSync() {
return
}
// 启动协程循环的执行调度任务
go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything)
}
(sched *Scheduler) scheduleOne
继续探究scheduleOne函数,scheduleOne函数非常关键。函数的第一步就是 getNextPod() 从调度队列podQueue中取出一个待调度 pod
// scheduleOne does the entire scheduling workflow for a single pod. It is serialized on the scheduling algorithm's host fitting.
func (sched *Scheduler) scheduleOne() {
// 从调度队列podQueue中取出一个待调度 pod
pod := sched.config.NextPod()
if pod.DeletionTimestamp != nil {
sched.config.Recorder.Eventf(pod, v1.EventTypeWarning, "FailedScheduling", "skip schedule deleting pod: %v/%v", pod.Namespace, pod.Name)
glog.V(3).Infof("Skip schedule deleting pod: %v/%v", pod.Namespace, pod.Name)
return
}
glog.V(3).Infof("Attempting to schedule pod: %v/%v", pod.Namespace, pod.Name)
// Synchronously attempt to find a fit for the pod.
start := time.Now()
suggestedHost, err := sched.schedule(pod)
if err != nil {
// schedule() may have failed because the pod would not fit on any host, so we try to
// preempt, with the expectation that the next time the pod is tried for scheduling it
// will fit due to the preemption. It is also possible that a different pod will schedule
// into the resources that were preempted, but this is harmless.
if fitError, ok := err.(*core.FitError); ok {
preemptionStartTime := time.Now()
sched.preempt(pod, fitError)
metrics.PreemptionAttempts.Inc()
metrics.SchedulingAlgorithmPremptionEvaluationDuration.Observe(metrics.SinceInMicroseconds(preemptionStartTime))
metrics.SchedulingLatency.WithLabelValues(metrics.PreemptionEvaluation).Observe(metrics.SinceInSeconds(preemptionStartTime))
}
return
}
metrics.SchedulingAlgorithmLatency.Observe(metrics.SinceInMicroseconds(start))
// Tell the cache to assume that a pod now is running on a given node, even though it hasn't been bound yet.
// This allows us to keep scheduling without waiting on binding to occur.
assumedPod := pod.DeepCopy()
// Assume volumes first before assuming the pod.
//
// If all volumes are completely bound, then allBound is true and binding will be skipped.
//
// Otherwise, binding of volumes is started after the pod is assumed, but before pod binding.
//
// This function modifies 'assumedPod' if volume binding is required.
allBound, err := sched.assumeVolumes(assumedPod, suggestedHost)
if err != nil {
return
}
// assume modifies `assumedPod` by setting NodeName=suggestedHost
err = sched.assume(assumedPod, suggestedHost)
if err != nil {
return
}
// bind the pod to its host asynchronously (we can do this b/c of the assumption step above).
go func() {
// Bind volumes first before Pod
if !allBound {
err = sched.bindVolumes(assumedPod)
if err != nil {
return
}
}
err := sched.bind(assumedPod, &v1.Binding{
ObjectMeta: metav1.ObjectMeta{Namespace: assumedPod.Namespace, Name: assumedPod.Name, UID: assumedPod.UID},
Target: v1.ObjectReference{
Kind: "Node",
Name: suggestedHost,
},
})
metrics.E2eSchedulingLatency.Observe(metrics.SinceInMicroseconds(start))
if err != nil {
glog.Errorf("Internal error binding pod: (%v)", err)
}
}()
}
scheduleOne函数较长我们提炼出关键步骤:
sched.config.NextPod()从调度队列podQueue中取出一个待调度 podsched.schedule(pod)执行对pod的调度任务,调度完成会返回一个合适的host(suggestedHost)sched.bind执行 bind ,即将 pod 绑定到 node,并发送post请求给apiserver
// scheduleOne does the entire scheduling workflow for a single pod. It is serialized on the scheduling algorithm's host fitting.
func (sched *Scheduler) scheduleOne() {
// 从调度队列podQueue中取出一个待调度 pod
pod := sched.config.NextPod()
// 执行pod的调度任务,调度完成会返回一个合适的host
suggestedHost, err := sched.schedule(pod)
// bind the pod to its host asynchronously (we can do this b/c of the assumption step above).
go func() {
// 执行 bind ,将 pod 绑定到 node
err := sched.bind(assumedPod, &v1.Binding{
}()
}
接下来,我们分别对获取待调度pod、执行pod调度任务、pod的绑定详细探究
源码如何实现调度任务
(sched *Scheduler) schedule
(sched *Scheduler) schedule 的作用是给定一个待调度pod,利用调度算法,返回一个合适的Host。函数内部直接执行调度任务的是sched.config.Algorithm.Schedule.
// schedule implements the scheduling algorithm and returns the suggested host.
func (sched *Scheduler) schedule(pod *v1.Pod) (string, error) {
// 给定一个pod 和 一个NodeLister,返回一个合适的host
host, err := sched.config.Algorithm.Schedule(pod, sched.config.NodeLister)
if err != nil {
pod = pod.DeepCopy()
sched.config.Error(pod, err)
sched.config.Recorder.Eventf(pod, v1.EventTypeWarning, "FailedScheduling", "%v", err)
sched.config.PodConditionUpdater.Update(pod, &v1.PodCondition{
Type: v1.PodScheduled,
Status: v1.ConditionFalse,
LastProbeTime: metav1.Now(),
Reason: v1.PodReasonUnschedulable,
Message: err.Error(),
})
return "", err
}
return host, err
}
(g *genericScheduler) Schedule
sched.config.Algorithm.Schedule 是一个接口,具体实现是genericScheduler结构的Schedule()方法。

找到genericScheduler结构体的Schedule()方法的源码
// Schedule tries to schedule the given pod to one of the nodes in the node list.
// If it succeeds, it will return the name of the node.
// If it fails, it will return a FitError error with reasons.
func (g *genericScheduler) Schedule(pod *v1.Pod, nodeLister algorithm.NodeLister) (string, error) {
trace := utiltrace.New(fmt.Sprintf("Scheduling %s/%s", pod.Namespace, pod.Name))
defer trace.LogIfLong(100 * time.Millisecond)
// 执行一些检查工作
if err := podPassesBasicChecks(pod, g.pvcLister); err != nil {
return "", err
}
// 获取 所有node信息
nodes, err := nodeLister.List()
if err != nil {
return "", err
}
if len(nodes) == 0 {
return "", ErrNoNodesAvailable
}
// Used for all fit and priority funcs.
// 更新缓存中Node信息
err = g.cache.UpdateNodeNameToInfoMap(g.cachedNodeInfoMap)
if err != nil {
return "", err
}
trace.Step("Computing predicates")
// findNodesThatFit 执行预选算法,过滤出符合的node节点
startPredicateEvalTime := time.Now()
filteredNodes, failedPredicateMap, err := g.findNodesThatFit(pod, nodes)
if err != nil {
return "", err
}
if len(filteredNodes) == 0 {
return "", &FitError{
Pod: pod,
NumAllNodes: len(nodes),
FailedPredicates: failedPredicateMap,
}
}
// 记录数据用于promethues监控采集
metrics.SchedulingAlgorithmPredicateEvaluationDuration.Observe(metrics.SinceInMicroseconds(startPredicateEvalTime))
metrics.SchedulingLatency.WithLabelValues(metrics.PredicateEvaluation).Observe(metrics.SinceInSeconds(startPredicateEvalTime))
trace.Step("Prioritizing")
// 接下来将执行优选算法(打分),选出最优node
startPriorityEvalTime := time.Now()
// When only one node after predicate, just use it.
// 如果最优的节点只有一个,就直接返回该节点
if len(filteredNodes) == 1 {
metrics.SchedulingAlgorithmPriorityEvaluationDuration.Observe(metrics.SinceInMicroseconds(startPriorityEvalTime))
return filteredNodes[0].Name, nil
}
metaPrioritiesInterface := g.priorityMetaProducer(pod, g.cachedNodeInfoMap)
// PrioritizeNodes 执行优选算法(打分),选出最优的node
priorityList, err := PrioritizeNodes(pod, g.cachedNodeInfoMap, metaPrioritiesInterface, g.prioritizers, filteredNodes, g.extenders)
if err != nil {
return "", err
}
metrics.SchedulingAlgorithmPriorityEvaluationDuration.Observe(metrics.SinceInMicroseconds(startPriorityEvalTime))
metrics.SchedulingLatency.WithLabelValues(metrics.PriorityEvaluation).Observe(metrics.SinceInSeconds(startPriorityEvalTime))
trace.Step("Selecting host")
// selectHost 从最优的node列表中选出,最优的一个node节点
return g.selectHost(priorityList)
}
代码较长,老规矩我们提炼出精华。(g *genericScheduler) Schedule的工作主要有3点:
g.findNodesThatFit(pod, nodes)从nodes列表中过滤出适合pod调度的node列表,即所谓的“预选”。PrioritizeNodes对node列表中的node执行"打分",选出分数最高的node列表(因为可能出现一些node的分数最高且相同,所以返回的是多个node的列表),即所谓的"“优选”。- .
selectHost(priorityList)从最优列表中选出一个最最最合适的node节点。
// Schedule tries to schedule the given pod to one of the nodes in the node list.
// If it succeeds, it will return the name of the node.
// If it fails, it will return a FitError error with reasons.
func (g *genericScheduler) Schedule(pod *v1.Pod, nodeLister algorithm.NodeLister) (string, error) {
// 1. 获取所有node信息
nodes, err := nodeLister.List()
// 2. findNodesThatFit 执行预选算法,过滤出符合的node节点
filteredNodes, failedPredicateMap, err := g.findNodesThatFit(pod, nodes)
// When only one node after predicate, just use it.
// 2.1 如果最优的节点只有一个,就直接返回该节点
if len(filteredNodes) == 1 { return filteredNodes[0].Name, nil}
// 3. PrioritizeNodes 执行优选算法(打分),选出最优的node
priorityList, err := PrioritizeNodes(pod, g.cachedNodeInfoMap, metaPrioritiesInterface, g.prioritizers, filteredNodes, g.extenders)
// 4. selectHost 从最优的node列表中选出,最优的一个node节点
return g.selectHost(priorityList)
}
g.findNodesThatFit和PrioritizeNodes 内容较多后面写一个文章单独分析。
(g *genericScheduler) Schedule的执行流程如图所示
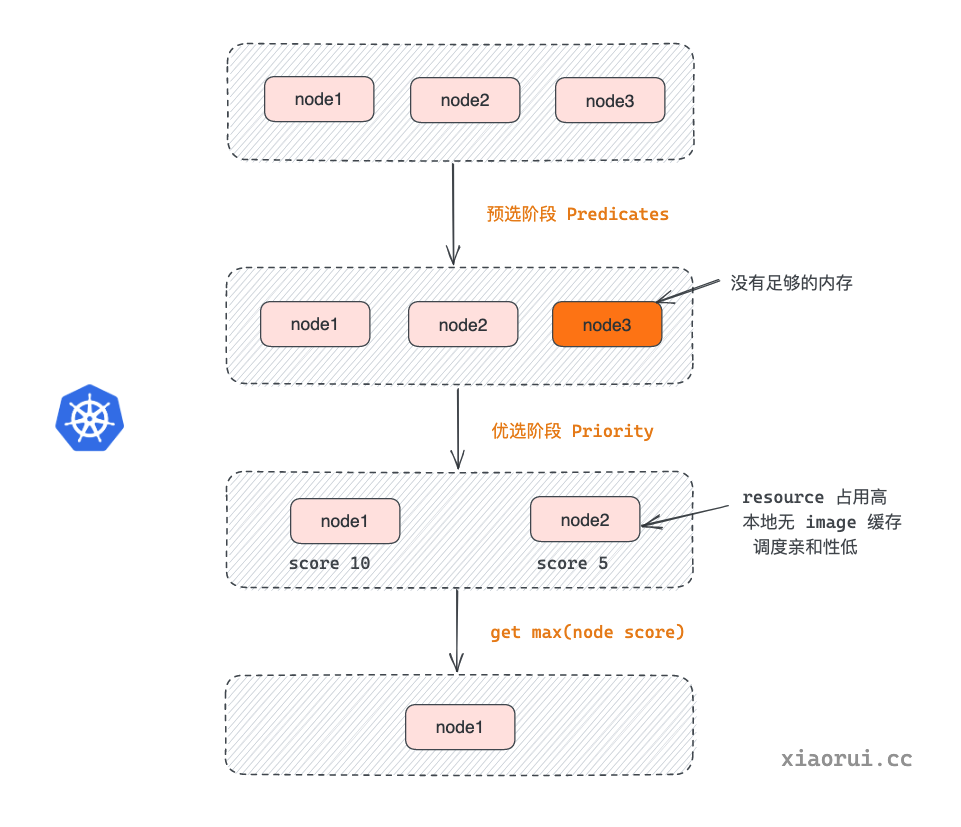
(图片来自网络,如有侵权,请联系作者删除)
(g *genericScheduler) selectHost
柿子挑软的捏。selectHost逻辑最简单,所以先分析它。 selectHost的任务是从优选列表中选出``一个最优node,注意如果有多个node最大且分数一样时,会通过索引累计方式,避免多次调度到同一个宿主`。
// selectHost takes a prioritized list of nodes and then picks one
// in a round-robin manner from the nodes that had the highest score.
func (g *genericScheduler) selectHost(priorityList schedulerapi.HostPriorityList) (string, error) {
if len(priorityList) == 0 {
return "", fmt.Errorf("empty priorityList")
}
// findMaxScores 从 priorityList 计算出最大分数的一个或多个 node 的索引
maxScores := findMaxScores(priorityList)
// 重要!!!通过索引累计方式,避免多次调度到同一个宿主
ix := int(g.lastNodeIndex % uint64(len(maxScores)))
g.lastNodeIndex++
return priorityList[maxScores[ix]].Host, nil
}
findMaxScores
findMaxScores 对 priorityList 遍历,找出分数最大node的索引并放入一个列表,如果最大分数有相同的,就都会放入列表。
// findMaxScores returns the indexes of nodes in the "priorityList" that has the highest "Score".
func findMaxScores(priorityList schedulerapi.HostPriorityList) []int {
maxScoreIndexes := make([]int, 0, len(priorityList)/2)
maxScore := priorityList[0].Score
for i, hp := range priorityList {
if hp.Score > maxScore {
maxScore = hp.Score
// 如果 node 的 score大于 maxScore就把所有放入列表 maxScoreIndexes
maxScoreIndexes = maxScoreIndexes[:0]
maxScoreIndexes = append(maxScoreIndexes, i)
} else if hp.Score == maxScore {
maxScoreIndexes = append(maxScoreIndexes, i)
}
}
return maxScoreIndexes
}
源码如何实现从调度队列中获取待调度pod
schduleOne函数执行的第一步sched.config.NextPod(),作用是从调度队列podQueue中取出一个待调度pod。那么问题来了,podQueue是如何初始化的呢?是如何将数据放到队列里面去的呢?
我们先将视线回到server.go中的run()函数,会执行NewSchedulerConfig(c) 获取调度配置。
Run
// Run runs the Scheduler.
func Run(c schedulerserverconfig.CompletedConfig, stopCh <-chan struct{}) error {
// 代码省略
// Build a scheduler config from the provided algorithm source.
schedulerConfig, err := NewSchedulerConfig(c)
if err != nil {
return err
}
// 代码省略
}
NewSchedulerConfig
NewSchedulerConfig 调用了 CreateFromProvider 函数。进一步查找 CreateFromProvider 函数
// NewSchedulerConfig creates the scheduler configuration. This is exposed for use by tests.
func NewSchedulerConfig(s schedulerserverconfig.CompletedConfig) (*scheduler.Config, error) {
// 代码省略
source := s.ComponentConfig.AlgorithmSource
var config *scheduler.Config
switch {
case source.Provider != nil:
// Create the config from a named algorithm provider.
sc, err := configurator.CreateFromProvider(*source.Provider)
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler using provider %q: %v", *source.Provider, err)
}
config = sc
// 代码省略
}
(c *configFactory) CreateFromProvider
CreateFromProvider 调用了 CreateFromKeys 函数
// Creates a scheduler from the name of a registered algorithm provider.
func (c *configFactory) CreateFromProvider(providerName string) (*scheduler.Config, error) {
glog.V(2).Infof("Creating scheduler from algorithm provider '%v'", providerName)
provider, err := GetAlgorithmProvider(providerName)
if err != nil {
return nil, err
}
// 注意
return c.CreateFromKeys(provider.FitPredicateKeys, provider.PriorityFunctionKeys, []algorithm.SchedulerExtender{})
}
(c *configFactory) CreateFromKeys
源码位置kubernetes/pkg/scheduler/factory/factory.go
在CreateFromKeys函数中终于找到NextPod的定义,我们继续查找c.getNextPod()
// Creates a scheduler from a set of registered fit predicate keys and priority keys.
func (c *configFactory) CreateFromKeys(predicateKeys, priorityKeys sets.String, extenders []algorithm.SchedulerExtender) (*scheduler.Config, error) {
glog.V(2).Infof("Creating scheduler with fit predicates '%v' and priority functions '%v'", predicateKeys, priorityKeys)
if c.GetHardPodAffinitySymmetricWeight() < 1 || c.GetHardPodAffinitySymmetricWeight() > 100 {
return nil, fmt.Errorf("invalid hardPodAffinitySymmetricWeight: %d, must be in the range 1-100", c.GetHardPodAffinitySymmetricWeight())
}
predicateFuncs, err := c.GetPredicates(predicateKeys)
if err != nil {
return nil, err
}
priorityConfigs, err := c.GetPriorityFunctionConfigs(priorityKeys)
if err != nil {
return nil, err
}
priorityMetaProducer, err := c.GetPriorityMetadataProducer()
if err != nil {
return nil, err
}
predicateMetaProducer, err := c.GetPredicateMetadataProducer()
if err != nil {
return nil, err
}
// Init equivalence class cache
if c.enableEquivalenceClassCache {
c.equivalencePodCache = equivalence.NewCache()
glog.Info("Created equivalence class cache")
}
// 重要!!! 创建通用调度器
algo := core.NewGenericScheduler(
c.schedulerCache,
c.equivalencePodCache,
c.podQueue,
predicateFuncs,
predicateMetaProducer,
priorityConfigs,
priorityMetaProducer,
extenders,
c.volumeBinder,
c.pVCLister,
c.alwaysCheckAllPredicates,
c.disablePreemption,
c.percentageOfNodesToScore,
)
podBackoff := util.CreateDefaultPodBackoff()
return &scheduler.Config{
SchedulerCache: c.schedulerCache,
Ecache: c.equivalencePodCache,
// The scheduler only needs to consider schedulable nodes.
NodeLister: &nodeLister{c.nodeLister},
Algorithm: algo,
GetBinder: c.getBinderFunc(extenders),
PodConditionUpdater: &podConditionUpdater{c.client},
PodPreemptor: &podPreemptor{c.client},
WaitForCacheSync: func() bool {
return cache.WaitForCacheSync(c.StopEverything, c.scheduledPodsHasSynced)
},
// 重要!!!从调度队列中取出一个 待调度 pod
NextPod: func() *v1.Pod {
return c.getNextPod()
},
Error: c.MakeDefaultErrorFunc(podBackoff, c.podQueue),
StopEverything: c.StopEverything,
VolumeBinder: c.volumeBinder,
// 定义调度队列
SchedulingQueue: c.podQueue,
}, nil
}
getNextPod() 的逻辑很简单,就是从调度队列podQueue中Pop()出一个待调度的pod。podQueue是一个优先级队列,如果待调度pod在spec中配置了优先级,pop()会弹出优先级高的pod执行调度任务。
func (c *configFactory) getNextPod() *v1.Pod {
// 从调度队列从弹出一个待调度的pod
pod, err := c.podQueue.Pop()
if err == nil {
glog.V(4).Infof("About to try and schedule pod %v/%v", pod.Namespace, pod.Name)
return pod
}
glog.Errorf("Error while retrieving next pod from scheduling queue: %v", err)
return nil
}
到此,我们明白了,shed.run()启动s时会启动informer,informer中定义了pod事件handler回调函数,handler会将待调度的pod放入调度队列podQueue。 而消费调度队列里面的pod,则是sheduleOne方法通过c.podQueue.Pop()取出一个待调度pod。
源码如何实现bind操作
scheduleOne选出一个 node 之后,调度器会创建一个v1.Binding 对象, Pod 的 ObjectReference 字段的值就是选中的 suggestedHost 的名字。
下面代码片段是scheduleOne中关于bind操作的内容
// 构建一个 v1.Binding 对象
err := sched.bind(assumedPod, &v1.Binding{
ObjectMeta: metav1.ObjectMeta{Namespace: assumedPod.Namespace, Name: assumedPod.Name, UID: assumedPod.UID},
Target: v1.ObjectReference{
Kind: "Node",
Name: suggestedHost,
},
})
v1.Binding资源类型的介绍
v1.Binding 是 Kubernetes API 的一个对象类型,用于将一个或多个 Pod 绑定到一个特定的节点上。为了将 Pod 绑定到特定的节点上,可以使用 v1.Binding 对象。该对象需要指定 Pod 的名称和命名空间,以及要绑定到的节点名称。
(b *binder) Bind 代码很多,但核心的就一行:
err := sched.config.GetBinder(assumed).Bind(b)
调用Binder接口的Bind方法。进一可以看到,Bind方法 是利用clientset向apiserver发起一个Bind的POST请求
// bind binds a pod to a given node defined in a binding object. We expect this to run asynchronously, so we
// handle binding metrics internally.
func (sched *Scheduler) bind(assumed *v1.Pod, b *v1.Binding) error {
bindingStart := time.Now()
// If binding succeeded then PodScheduled condition will be updated in apiserver so that
// it's atomic with setting host.
// 调用Binder接口的Bind方法
err := sched.config.GetBinder(assumed).Bind(b)
// 检查cache中对应pod的状态,确认是否bind成功
if err := sched.config.SchedulerCache.FinishBinding(assumed); err != nil {
glog.Errorf("scheduler cache FinishBinding failed: %v", err)
}
// 如果没有bind绑定成功,则记录错误原因
if err != nil {
glog.V(1).Infof("Failed to bind pod: %v/%v", assumed.Namespace, assumed.Name)
if err := sched.config.SchedulerCache.ForgetPod(assumed); err != nil {
glog.Errorf("scheduler cache ForgetPod failed: %v", err)
}
sched.config.Error(assumed, err)
sched.config.Recorder.Eventf(assumed, v1.EventTypeWarning, "FailedScheduling", "Binding rejected: %v", err)
sched.config.PodConditionUpdater.Update(assumed, &v1.PodCondition{
Type: v1.PodScheduled,
Status: v1.ConditionFalse,
LastProbeTime: metav1.Now(),
Reason: "BindingRejected",
})
return err
}
// 记录metrics监控数据
metrics.BindingLatency.Observe(metrics.SinceInMicroseconds(bindingStart))
metrics.SchedulingLatency.WithLabelValues(metrics.Binding).Observe(metrics.SinceInSeconds(bindingStart))
sched.config.Recorder.Eventf(assumed, v1.EventTypeNormal, "Scheduled", "Successfully assigned %v/%v to %v", assumed.Namespace, assumed.Name, b.Target.Name)
return nil
}
Bind 是调用了clientset向apiserver发起一个Bind的POST请求
// Bind just does a POST binding RPC.
func (b *binder) Bind(binding *v1.Binding) error {
glog.V(3).Infof("Attempting to bind %v to %v", binding.Name, binding.Target.Name)
// 通过clientset向apiserver发起一个Bind的POST请求
return b.Client.CoreV1().Pods(binding.Namespace).Bind(binding)
}
补充内容: apiserver收到bind请求后
当apiserver 收到这个 Binding object 请求后,将会更新 Pod 对象的下列字段:
设置 pod.Spec.NodeName
添加 annotations
设置 PodScheduled status 为 True
// k8s.io/kubernetes/pkg/registry/core/pod/storage/storage.go
// assignPod assigns the given pod to the given machine.
// 处理 api 收到到binding RESTful 请求
func (r *BindingREST) assignPod(ctx context.Context, podID string, machine string, annotations map[string]string, dryRun bool) (err error) {
// 设置pod的 host 和 Annotation 信息
if _, err = r.setPodHostAndAnnotations(ctx, podID, "", machine, annotations, dryRun); err != nil {
err = storeerr.InterpretGetError(err, api.Resource("pods"), podID)
err = storeerr.InterpretUpdateError(err, api.Resource("pods"), podID)
if _, ok := err.(*errors.StatusError); !ok {
err = errors.NewConflict(api.Resource("pods/binding"), podID, err)
}
}
return
}
// k8s.io/kubernetes/pkg/registry/core/pod/storage/storage.go
func (r *BindingREST) setPodHostAndAnnotations(ctx context.Context, podID, oldMachine, machine string,
annotations map[string]string, dryRun bool) (finalPod *api.Pod, err error) {
podKey := r.store.KeyFunc(ctx, podID)
r.store.Storage.GuaranteedUpdate(ctx, podKey, &api.Pod{}, false, nil,
storage.SimpleUpdate(func(obj runtime.Object) (runtime.Object, error) {
pod, ok := obj.(*api.Pod)
// 设置 pod.Spec.NodeName
pod.Spec.NodeName = machine
if pod.Annotations == nil {
pod.Annotations = make(map[string]string)
}
// 更新 pod 的 annotations
for k, v := range annotations {
pod.Annotations[k] = v
}
// 设置pod 的 pod.status.conditions中的status值为truez
podutil.UpdatePodCondition(&pod.Status, &api.PodCondition{
Type: api.PodScheduled,
Status: api.ConditionTrue,
})
return pod, nil
}), dryRun, nil)
}
更新pod.spec.Nodename后,将数据写入到etcd,之后 被指定调度的node节点上的 kubelet监听到这个事件,kubelet接下来会在该机器上创建pod.
总结
经过分析scheduleOne函数会循环的从调度队列sheduling_Queue`,取出pop()待调度的pod, 之后利用`sched.schedule()执行调度任务,选出最佳的sugestHost。 最后sched.bind()通过clientset向apiserver发起绑定bind的POST请求。至此,完成了一个完成的pod调度过程,流程如图所示。



















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











