重心法
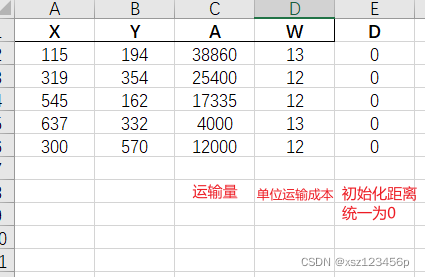
数据准备-格式
import numpy as np
from matplotlib import pyplot as plt
import pandas as pd
def init_factory():
data = [281.84548388749425, 288.61186536195504]
return data
def cost(x_d, y_d, data):
cost = np.sum(data.loc[:, 'A'].to_numpy() * data.loc[:, 'W'].to_numpy() * data.loc[:, 'D'].to_numpy())
return cost
file = "data1.xlsx"
data = pd.read_excel(file)
iteration = 10000
x_factory = init_factory()[0]
y_factory = init_factory()[1]
opt_x_factory = 0
opt_y_factory = 0
low_cost = 100
for k in range(iteration):
print("第{0}次迭代".format(k +1))
distance= np.sum((data.loc[:, ['X', 'Y']].to_numpy() - np.array([x_factory, y_factory]))**2, axis=1)**0.5
data.loc[:, 'D'] = np.reshape(distance, (-1, 1))
T_0 = cost(x_factory, y_factory, data)
print("工厂位置为:(x, y)=({0}, {1})".format(x_factory, y_factory))
print(data)
before_x_factory = x_factory
before_y_factory = y_factory
WC_j = np.sum(data.loc[:, 'A'].to_numpy()*data.loc[:, 'W'].to_numpy()/data.loc[:, 'D'].to_numpy())
WCX_j = np.sum(data.loc[:, 'A'].to_numpy() * data.loc[:, 'W'].to_numpy() * data.loc[:, 'X'].to_numpy()/data.loc[:, 'D'].to_numpy())
WCY_j = np.sum(data.loc[:, 'A'].to_numpy()*data.loc[:, 'W'].to_numpy()*data.loc[:, 'Y'].to_numpy()/data.loc[:, 'D'].to_numpy())
x_factory = WCX_j / WC_j
y_factory = WCY_j / WC_j
distance= np.sum((data.loc[:, ['X', 'Y']].to_numpy() - np.array([x_factory, y_factory]))**2, axis=1)**0.5
data.loc[:, 'D'] = np.reshape(distance, (-1, 1))
T_1 = cost(x_factory, y_factory, data)
if T_0 < T_1:
opt_x_factory = before_x_factory
opt_y_factory = before_y_factory
low_cost = T_0
print("------------end-----------------")
break
print("最优工厂位置为:(x, y)=({0}, {1})".format(opt_x_factory, opt_y_factory))
print("最低成本:{0}".format(low_cost))
























 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









