







刚看一下,我的上一篇博客竟然是在8.10写的,到今天已经差不多40天了,时间过的可真快,最近太忙,一直没时间整理看过的东西,索性这会没事随便写点。
我的专业是地图学与地理信息,听这个名字就知道少不了要与地理数据打交道,我用spark一般也是处理地理数据,很幸运spark有一个开源的地理数据处理框架 geotrellis,下面是官方对geotrellis的定义
GeoTrellis is a Scala library and framework that uses Spark to work
with raster data. It is released under the Apache 2 License.GeoTrellis reads, writes, and operates on raster data as fast as
possible. It implements many Map Algebra operations as well as vector
to raster or raster to vector operations.GeoTrellis also provides tools to render rasters into PNGs or to store
metadata about raster files as JSON. It aims to provide raster
processing at web speeds (sub-second or less) with RESTful endpoints
as well as provide fast batch processing of large raster data sets
好像我们学什么语言都是从写一个helloworld开始的,这里有一个geotrellis版的helloworld,大家可以看看,代码相当简单,但我第一次看到却一脸懵逼
import geotrellis.raster._
import geotrellis.spark._
object Main {
def helloSentence = "Hello GeoTrellis"
def main(args: Array[String]): Unit = {
println(helloSentence)
}
}
其实就只有一行println(“helllo Geotrellis”),这没什么问题,那问题在哪,前面两个import那来的,我并没有安装geotrellis,项目中也没有其它文件,这些包是怎么引进来的,但是我又能正常运行,这是为什么啊,我心里一万头草泥马奔腾而过,
后来查了很多资料才知道这是一个sbt项目,它所的外部依赖都写在build.sbt这个文件中
libraryDependencies ++= Seq(
"com.azavea.geotrellis" %% "geotrellis-spark" % "0.10.1",
"org.apache.spark" %% "spark-core" % "1.6.1" % "provided",
"org.scalatest" %% "scalatest" % "2.2.0" % "test"
)
这是这个项目引入的依赖库,终于找到geotrellis的引入了,那么前面两个import也就没什么问题了,在那之前我没接触过sbt,所以才会有这样的问题,对sbt有一定接触的人看这个项目肯定没什么问题。解决了geotrellis引入的问题,这个项目也就没什么意思了,接下来看点好玩的。
我们和地理数据打交道的人免不了的一件事就是显示地理数据,那么用geotrellis如何显示地理数据呢,geotrellis的作法是将TIF数据切成瓦片然在在浏览器端进行渲染。 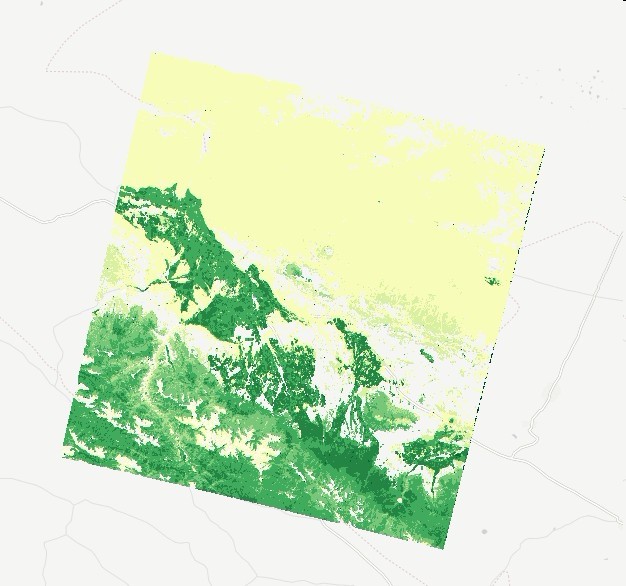 这里是我对NDVI的一个渲染图,下面是一个底图,上面是我自己的瓦片。这个给大家看看样子,今天估且不说,感兴趣的可以看[这里](https://github.com/geotrellis/geotrellis-landsat-tutorial)。我们先说一个最基本的问题,那就是geotrellis如何发起web服务,并且前后端如何交互,这儿也一个个[例子](https://github.com/geotrellis/geotrellis-chatta-demo),我当初看这个看了一周才基本弄懂,这个例子很全面,有切割瓦片,有发起服务,有也前后端交互,但就是因为东西太多看起来不容易。好了,上面两个例子如果大家都能看懂那么我下面的东西大家就不用看了。 下面我们就写一个web版的hello world吧 发起服务的代码很简单 implicit val system = akka.actor.ActorSystem("tutorial-system")
val service =system.actorOf(Props(classOf[HelloWorld]), "tutorial")
IO(Http) ! Http.Bind(service, "localhost", 8088)
这行代码的意思就是发起一个service服务,服务的地址是localhost,端口是8088,然后在浏览器输入localhost:8088就可能看到服务的内容了,其中tutorial是服务名,服务的具体内容在HelloWorld中定义。HelloWorld是一个类,是那么重点来了,这个类如何定义呢,它是这样的
class HelloWorld extends Actor with HttpService{
override def actorRefFactory = context
override def receive = runRoute(root)
def root = get {
pathEndOrSingleSlash {
getFromFile("static/helloworld.html")
}
}
}
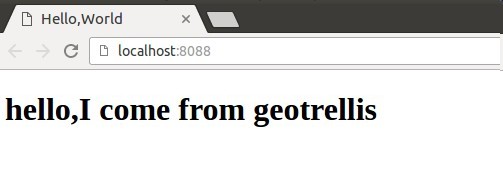
我段代码就是告诉我们网页去哪找,我们在static目录下有一个helloworld的HTML文件,是不是很简单?它的效果是这样的
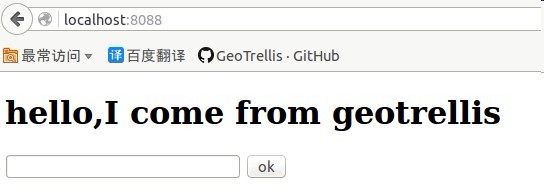
现在可以显示了,我们再来看看如何交互,比如我们输入自己的名字,然后显示问候语。
现在我们网页是这样的
当我们在文本框输入内容点击OK 后它变成这样
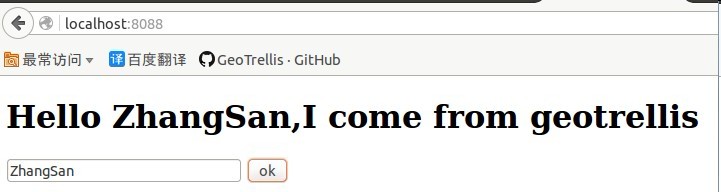
它的整个过程是这样的,我点击OK把文本框中的值zhangsan传给后台,后台经过处理后变成<h1>Hello zhangsan,I come from geotrellis</h1>再传回来,然后把后台传回来的值写到网页。虽然很简单,但整个过程包含了前端传到后台——后台处理——后台传到前端的过程,了解这个过程后,我们自然可以写更复杂的处理程序。
接下来我们看看它是怎么实现的,首先看服务器代码,现在它变成了这样
def root = get {
path("ok")(ok)~
pathEndOrSingleSlash {
getFromFile("static/helloworld.html")
}~
pathPrefix("") {
getFromDirectory("./static")
}
}
def ok=parameters(
'name
)
{(name)=>
val arr=s"""{"rst":[{"v":"<h1>Hello $name,I come from geotrellis</h1>"
}]}"""
complete(arr)
}
}
和前面相比它多了一个函数ok,和两行代码,函数ok当然是处理前端传回来的值
pathPrefix("") {
getFromDirectory("./static")
}
代码的意思是网页中引用的内容所在的目录,即js,css,图片等所在的目录。
path("ok")(ok)
这一行代码就是定义的一个服务ok,它有一个参数name,我们可以在前端调用它。
再来看看前端的代码
<script type="text/javascript">
function getName(){
var myname=document.getElementById("name").value
$.ajax({
url: 'ok',
data: { 'name' : myname},
dataType: "json",
success: function(r) {
document.getElementById("box").innerHTML=r.rst[0].v
}
});
}
</script>
$.ajax是jquery中的函数,作用是调用一个ajax服务,服务的地址是ok,因为我们在后端定义了一个服务ok,data是传到后台的数据,因为ok服务有一个参数name,我们在调用时必须传给后台,然后如果调用成功,我们在回调函数中可以处理后台传回的值。
好了,今天的博客就写到这儿,这点东西写了两个半小时了。我希望它不只是记录了我学习的经历,同时也能帮到其它人,毕竟geotrellis的资料现在还是非常少的。
















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











