









第一步是在主库上记录二进制日志,在记录二进制日志后,主库会告诉存储引擎可以提交事务了。
下一步,备库将主库的二进制日志复制到其本地的中继日志中。首先,备库会启动一个工作线程,称为I/O线程,I/O线程跟主库建立一个普通的客户端连接,然后在主库上启动一个特殊的二进制转存(binlog dump)线程,这个转存线程会读取主库上的二进制日志中事件。它不会对事件进行轮询,如果该线程追赶上了主库,它将进入睡眠状态,直到主库发送信号量通知其有新的事件产生时才会被唤醒。备库I/O线程会将接收到的事件记录到中继日志中。
备库的SQL线程执行最后一步,该线程从中继日志中读取事件并在备库执行,从而实现备库数据的更新。
这种复制架构最重要的一点是在主库上并发运行的查询在备库只能串行化执行,因为只有一个SQL线程来重放中继日志中的事件。这将会影响主备不同步,虽然有一些针对该问题的解决方案,但大多数用户仍然受制于单线程。
binlog dump线程最开始的时候很可能会去读取仍存储在主库日志缓存或操作系统缓存或磁盘缓存中的事件,因此这时在主库上还没有任何物理磁盘的读操作。但是,当几小时后甚至几天后从库连接到主库上,会首先开始读取几小时或几天之前写入的二进制日志,此时主库很可能不会再有这些数据的缓存,那么读磁盘操作就不可避免的发生了,如果主库没有任何的空闲的I/O资源,这时你可能会感受到主库服务震荡。
下面我们着重讲一下转存(binlog dump)线程的工作原理。
MySQL主从同步的实现中,从库连接到主库,并向主库发送一个COM_BINLOG_DUMP命令。该过程和一个用户访问MySQL的过程类似,主库中的binlog dump线程和用户线程都是由统一的连接管理机制管理,属于同一个线程池。不同的是binlog dump线程会一直存活。
binlog dump线程按照从库请求的binlog名字和pos找到对应的binlog文件,然后读取binlog的envent不断的发往从库,当主库处于空闲状态时,binlog dump线程会在一个信号量(update_cond即主库的binlog更新状态)上等待。
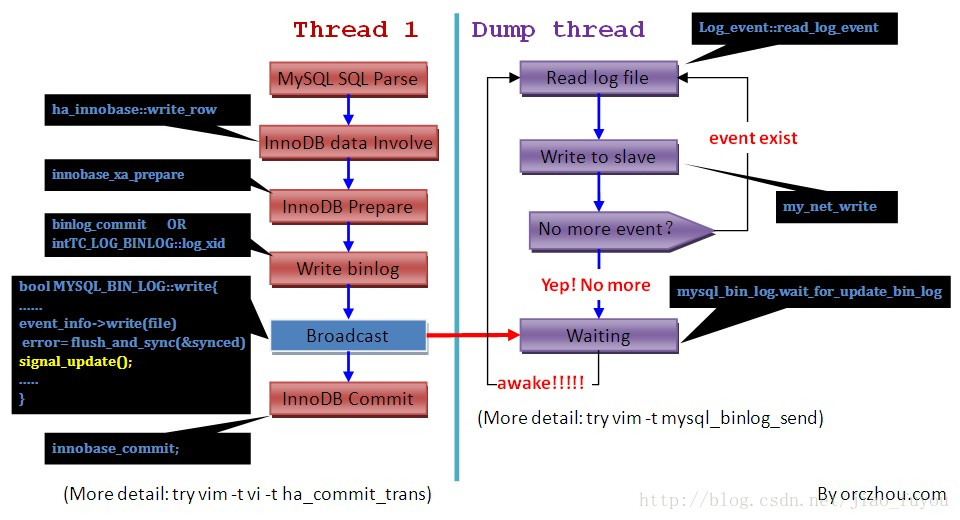
在主库端一旦有新的日志产生后,立刻会发送一次广播,dump线程在收到广播后,则会读取二进制日志并通过网络向备库传输日志,所以这是一个主库向备库不断推送的过程。
新日志在产生后,只需一次广播和网络就会立刻(<1ms)发送到备库,如果主备之间网络较好的话(例如RTT<1ms),备库端的日志也就小于2ms了。所以,一般的(依赖于RTT),备库的实时性都非常好。
但是这种机制存在一个问题,由于binlog dump线程在等待主库中的update_cond信号量时,不能感知到从库的变化,如果从库这时候死亡,或者执行了stop slave,则该binlog dump线程将一直存活。processlist显示线程处于:
Has sent all binlog to slave; waiting for binlog to be updatedHas sent all binlog to slave; waiting for binlog to be updated。
当主库的binlog中有新的写入时激活所有的binlog dump线程,这些线程再次和从库连接时才发现从库已经退出,然后该线程自己也会退出。
设想在一个idle的主库中,一个从库由于网络原因失去了和主库的连接,此时其对应的binlog dump线程依然存活,网络恢复之后,该从库重新连接主库。则主库中将存在两个线程对应同一个从库。MySQL为了避免这个问题,在一个从库向主库发送COM_BINLOG_DUMP命令过程中。会遍历当前的binlog dump线程,如果发现连接上来的从库的server-id和既有线程对应的server-id相同,则将既有的那些server-id相同的线程杀死,防止一个从库对应两个binlog dump线程。
如果server-id相同的两个从库连到同一个idle的主库上。则COM_BINLG_DUMP命令会不断的把另一台从库的binlog dump线程杀死,而从库由于不清楚情况,会不断的重连主库,重连导致的结果是不断的再次杀死其他server-id相同的从库。进入一个死循环。
从库的错误日志中显示类似如下的日志:
121016 13:42:46 [Note] Slave: connected to master 'MySQLsync@127.0.0.1:6600',replication resumed in log 'MySQL-bin.000019' at position 2345 121016 13:42:46 [Note] Slave: received end packet from server, apparent master shutdown: 121016 13:42:46 [Note] Slave I/O thread: Failed reading log event, reconnecting to retry, log 'MySQL-bin.000019' position 2345
在主库中执行show processlist可以看见两个sql dump线程交替重连,线程ID不断变化说明,之前的线程被杀死并产生新的线程。只有停掉server-id相同的从库,才能保证COM_BINLOG_DUMP正常执行。
从库退出而对应的binlog dump线程不退出,这种现象应该算是一个BUG,但是由于现有MySQL同步的实现中,主库和从库的交互性比较弱,主库只有从网络活动上才能获知从库是否存活,而在主库没有监测到网络活动时从库退出,也没有更好的办法来处理binlog dump线程。为了避免大量的binlog dump线程沦为僵尸。开发人员就在COM_BINLOG_DUMP执行的过程中进行一下清理,将server-id相同的老线程都杀死。而那些在主库idle时从库退出的dump线程则会变成僵尸,一直等到主库有binlog写入事件发生。
复制线程状态
主库binlog dump线程状态
下面列出了主库binlog dump线程State列的最常见的状态。(如果你没有在主服务器上看见任何binlog dump线程,这说明复制没有在运行—即,目前没有连接任何从服务器)
Sending binlog event to slave
二进制日志由各种事件组成,一个事件通常为一个更新加一些其它信息。这个状态表示线程已经从二进制日志读取了一个事件并且正将它发送到从服务器。
Finished reading one binlog; switching to next binlog
线程已经读完二进制日志文件并且正打开下一个要发送到从服务器的日志文件。
Has sent all binlog to slave; waiting for binlog to be updated
线程已经从二进制日志读取所有主要的更新并已经发送到了从服务器。线程现在正空闲,等待由主服务器上新的更新导致的出现在二进制日志中的新事件。
Waiting to finalize termination
线程停止时发生的一个很简单的状态。
备库I/O线程状态
下面列出了从服务器的I/O线程的State列的最常见的状态。该状态也出现在Slave_IO_State列,由SHOW SLAVE STATUS显示。这说明你可以只通过该语句仔细浏览所发生的事情。
Connecting to master
线程正试图连接主服务器。
建立同主服务器之间的连接后立即临时出现的状态。
Registering slave on master
建立同主服务器之间的连接后立即临时出现的状态。
Requesting binlog dump
建立同主服务器之间的连接后立即临时出现的状态。线程向主服务器发送一条请求,索取从请求的二进制日志文件名和位置开始的二进制日志的内容。
Waiting to reconnect after a failed binlog dump request
如果二进制日志转储请求失败(由于没有连接),线程进入睡眠状态,然后定期尝试重新连接。可以使用–master-connect-retry选项指定重试之间的间隔。
Reconnecting after a failed binlog dump request
线程正尝试重新连接主服务器。
Waiting for master to send event
线程已经连接上主服务器,正等待二进制日志事件到达。如果主服务器正空闲,会持续较长的时间。如果等待持续slave_read_timeout秒,则发生超时。此时,线程认为连接被中断并企图重新连接。
Queueing master event to the relay log
线程已经读取一个事件,正将它复制到中继日志供SQL线程来处理。
Waiting to reconnect after a failed master event read
读取时(由于没有连接)出现错误。线程企图重新连接前将睡眠master-connect-retry秒。
Reconnecting after a failed master event read
线程正尝试重新连接主服务器。当连接重新建立后,状态变为Waiting for master to send event。
Waiting for the slave SQL thread to free enough relay log space
正使用一个非零relay_log_space_limit值,中继日志已经增长到其组合大小超过该值。I/O线程正等待直到SQL线程处理中继日志内容并删除部分中继日志文件来释放足够的空间。
Waiting for slave mutex on exit
线程停止时发生的一个很简单的状态。
I/O线程的State列也可以显示语句的文本。这说明线程已经从中继日志读取了一个事件,从中提取了语句,并且正在执行语句
备库SQL线程状态
下面列出了从服务器的SQL线程的State列的最常见的状态。
Reading event from the relay log
线程已经从中继日志读取一个事件,可以对事件进行处理了。
Has read all relay log; waiting for the slave I/O thread to update it
线程已经处理了中继日志文件中的所有事件,现在正等待I/O线程将新事件写入中继日志。
Waiting for slave mutex on exit
线程停止时发生的一个很简单的状态。
复制过滤器
复制过滤器选项允许你仅复制服务器上一部分数据,不过这可能没有想象中那么好用。有两种复制过滤方式:主库上过滤二进制日志,备库上过滤中继日志事件。主要有以过滤选项:
Binlog_do_db
Binlog_ignore_db
Replicate_do_db
Replicate_do_table
Replicate_ignore_db
Replicate_ignore_table
Replicate_rewrite_db
Replicate_wild_do_table
Replicate_wild_ignore_table
要理解这些选项,最重要是弄清楚*_do_db和*_ignore_db在主库和备库上的意义,它们可能不会按照你所设想的那样工作。你可能会认为它会根据目标数据库名过滤,但实际上过滤的是当前的默认数据库(如果使用的是基于语句的复制,就会有这样的问题,但基于行的复制方式则不会)。也就是说,如果在主库上执行如下语句:
Mysql>USE test;
Mysql>DELETE FROM sakila.file
*_do_db和*_ignore_db都会在数据库test上过滤DELETE语句,而不是在sakila上。这通常不是想要的结果,可能会导致执行或忽略错误的语句。
Binlog_do_db和Binlog_ignore_db不仅可能会破坏复制,还可能会导致从某个时间点的备份进行数据恢复时失败。在大多数据情况下都不应该使用这些参数。
更好的办法是阻止一些特殊的语句被复制,通常是设置SQL_LOG_BIN=0,虽然这种方法也有它的缺点。总地来说,除非万不得已,不要使用复制过滤,因为它很容易中断复制并导致问题,在需要灾难恢复时也会带来极大的不方便。
定制的复制方案
选择性复制
每个备库可以通选项replcate_wild_do_tab或replcate_wild_ignore_table来过滤需要复制的库或表,注意前面我们说过,不要使用*_do_db和*_ignore_db参数。
分离功能
将OLAP的数据分离到备库上
数据归档
可以在备库上实现数据归档,也就是说可以在备库上保留主库上删除过的数据。
第一种方法是先将SQL_LOG_BIN设置为0,然后再进行删除数据。这种方法不需要在备库上做任何配置,因为SQL语句根本没有记录到二进制日志中。
第二种方法是在清理数据之前对主库上的特定数据库使用USE语句,然后在备库上用replcate_ignore_db过滤掉该库的复制。这种方法,备库要去读事件判断后过滤。
第三种方法是利用binlog_ignore_db在主库上过滤事件,最好不要用这种方法,这是种很危险的操作
复制的管理和维护
测试备库延迟
虽然SHOW SLAVE STATUS输出的Seconds_behind_master列理论上显示了备库的延时,但由于各样的原因,并不总是准确的:
1.备库Seconds_Behind_Master值是通过将服务器当前的时间戳与二进制日志中的事件时间戳相对比得到的,所以只有在执行事件时才能报告延时。
2.如果备库复制线程没有运行,就会报延迟null。
3.一些错误(例如主备的max_allowed_packet不匹配,或者网络不稳定)可能中断复制并且/或者停止复制线程,备库有时可能无法计算延时。如果发生这种情况备库会报0或者null
4.一个大事务可能会导致延迟波动,例如,有一个事务更新数据长达一个小时,最后提交。这条更新将比它实际发生时间要晚一个小时才记录到二进制日志中。当备库执行这条语句时,会临时地报告备库延迟为一个小时,然后又很快变成0
5.如果分发主库落后了,并且其本身也有已经追赶上它的备库,备库的延迟将显示为0,而事实上和源主库是有延迟的。
解决办法是不要看这个值,最好的办法是使用heartbeat record,这是一个在主库上会每秒更新一次的时间戳。用备份当前时间减去心跳时间戳来比较。包含在Percona Toolkit里的pt-heartbeat脚本是“复制心跳”最流行的一种实现。
确定主备是否一致
复制延时或网络问题并总是会让主备数据不完全一致。主备一致应该是一种规范,而不是例外,也就是说,检查你的主备一致性应该是一个日常工作,特别是是当使用备库来做备份时尤为重要。
Percona Toolkit里的pt-table-checksum能够用于确认主备库数据是否一致。
如果系统在备库出现延迟时就无法很好地工作,那么应用程序也许就不应该用到复制。但是也有一些办法可以让备库跟上主库。
最简单的办法是配置InnoDB
使其不要那么频繁地刷新磁盘,这样事务提交的更快些。设置innodb_flush_log_at_trx_commit=2来实现。还可以在备库上禁止二进制日志记录,把innodb_locks_unsafe_for_binlog设置为1,并把MyISAM的delay_key_write设置为ALL。但是这些设置以牺牲安全换取速度。如果需要将备库提升为主库,记得把这些选项设置回安全值。
不要重要写操作中代价较高的部分
重构应用程序或者优化查询通常是最好的保持备库同步的办法。如果可以把工作转移备库,那么就只有一台备库需要执行,然后我们可以把写的结果回传到主库,例如,通过执行LOAD DATA INFILE。
在复制之外并行写入
所有写操作都应该从主库传递到备库?如果能确定一些写入可以轻易地在复制之外执行,就可以并行化这些操作以利用备库的写入容量。例如,一些归档数据,可以在主备上分别进行归档操作。
为复制线程预取缓存
通过程序实现,在SQL线程更新前提前读取中继日志并将其转化为SELECT语句执行。这会使服务器将数据从磁盘加载到内存中,这样SQL线程执行到相应语句时,就无需从磁盘读取数据。
限制主库过大的包
修改主库max_allowed_packet值,太大的包会使二进制事务变的复杂。
MySQL二进制日志转存线程并没有通过轮询的方式从主库请求事件,而是由主库来通知备库新的事件,因为前者低效且缓慢。从主库读取一个二进制日志事件是一个阻塞型网络调用,当主库记录事件后,马上就开始发送。因此可以说,只要复制转存线程被唤醒并且能够通过网络传输数据,事件就会很快到达备库。
MySQL复制的高级特性
我们在这里着重讲下MySQL5.5版本的半同步复制和复制心跳两项新特性。
半同步复制在提交过程中增加了一个延迟:当提交事务时,在客户端接收到查询结束反馈前必须保证二进制日志已经传输到至少一台备库上。主库将事务提交到磁盘上之后会增加一些延迟。同样的,这也增加了客户端延迟,因此其执行大量事务的速度不会比将这些事务传递给备库的速度更快。
关于半同步,有一些普遍的误解,下面是它不会去做的:
在备库提示其已经收到事件前,会阻塞主库上的事务提交。事实上在主库上已经完成事务提交,只有通知客户端被延迟了。
直到备库执行完事务后,才不会阻塞客户端。备库在接收到事务后发送反馈而非完成事务后发送。
半同步不总能够工作。如果备库一直没有回应已收到事件,会超时并转化为正常的异步复制模式。(试想一下,如果主备网络断了,那么半同步将直接导致性能问题)
事实上半同步复制在某些场景下确实能够提供足够的灵活性以改善性能,在主库关闭sync_binlog的情况下保证更加安全。写入远程的内存(一台备库反馈)比写入本地的磁盘(写入并刷新)要更快。有人进行过测试,使用半同步复制相比在主库上进行强持久化的性能有两倍改善。在任何系统上都没有绝对的持久化,只有更高的持久化层次,并且看起来半同步复制应该是一种比其他替代方案开销更小的系统数据持久化方法。
配置半同步复制
在Master上安装Master插件:
master> INSTALL PLUGIN rpl_semi_sync_master SONAME "semisync_master.so";
在每台Slave上安装Slave插件:
slave> INSTALL PLUGIN rpl_semi_sync_slave SONAME "semisync_slave.so";
在主库上[MySQLd]配置中增加:
rpl_semi_sync_master_enabled = 1
rpl_semi_sync_master_timeout=milliseconds
#同步复制超时时间,超时后恢复到异步复制
rpl_semi_sync_master_wait_no_slave={ON|OFF}
#如果设为OFF,则当Master没有任何Slave时恢复异步复制,否则等待到超时
在备库上[MySQLd]配置中增加:
rpl_semi_sync_slave_enabled = 1
另外有两个跟踪级别的配置变量:
rpl_semi_sync_master_trace_level = 32
rpl_semi_sync_slave_trace_level = 32
监控半同步复制,可以查看以下几个状态变量信息
Rpl_semi_sync_master_clients,master连接了多了半同步slave
Rpl_semi_sync_master_status,master半同步复制状态
Rpl_semi_sync_slave_status,slave半同步复制状态
另外还有几个状态变量:
Rpl_semi_sync_master_net_avg_wait_time
Rpl_semi_sync_master_net_wait_time
Rpl_semi_sync_master_net_waits
Rpl_semi_sync_master_no_times
Rpl_semi_sync_master_no_tx
Rpl_semi_sync_master_timefunc_failures
Rpl_semi_sync_master_tx_avg_wait_time
Rpl_semi_sync_master_tx_wait_time
Rpl_semi_sync_master_tx_waits
Rpl_semi_sync_master_wait_pos_backtraverse
Rpl_semi_sync_master_wait_sessions
Rpl_semi_sync_master_yes_tx
Rpl_status
除了半同步复制,MySQL5.5还提供了复制心跳,保证备库一直与主库相联系,避免悄无声息地断开连接。如果出现断开的网络连接,备库会注意到丢失的心跳数据。在备库可以用CHANGE MASTER TO MASTER_HEARTBEAT_PERIOD = interval来启动心跳监控,interval是每隔多长时间探测一下是否落后主服务器,主服务器是否在线。
其它复制技术
MySQL的复制之所以慢,主要是因为备库上的SQL线程是单线程顺序执行的。如果能够让其并行执行,那么就会快很多。
MySQL5.6增加了多线程(并行)复制以减少当前单线程复制的瓶颈,但是它是基于分库实现的,就是说一个线程只能对应该一个库。
还有就是自己实现一个SLAVE,模拟备库I/O线程,连接主库,读取二进制日志到本地,然后结合自己业务特点,表结构等,实现并行SQL更新,因为是针对自身业务,比如可以按表来分多线程,表里可以加上主键限制,保证事务的顺序执行。
如淘宝的MySQL多线程同步MySQL-Transfer开源补丁















 756
756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









