






前言:本人刚学习完C++ 和数据结构,目前计划自学冲击蓝桥杯省奖,因此将b站学习视频_bv号:BV1Lb4y1k7k3所涉及题目及其代码,在自学完毕后将心得和代码块稍加总结写成博客,以方便后续的复习
注意:本人在此处的所有心得及其相关代码,其本意都是为了方便后期自我复习,欢迎各位浏览至此的同仁分享出自己的学习心得,以上,共勉。
p1:
题目1:
解法:面向结果编程即printf大法
cout<<"A"<<endl;
cout<<"BBB"<<endl;
题目2:

题目分析:此类题目 需要考虑输出的空格数目 ,而空格数目又与输入的n有关,每行输出的字符只有一个种类,那么利用for循环每行都输出空格(与 n有关)+字符的组合
空格数与n 的关系:利用数学推理法:假设n取2 则第一行空格数目为1(为什么不是2,因为只需要考虑前面就好了,不需要考虑字符后面的空格),假设n取3,则第一行空格数目为2个,第二行空格数目为1,则可以推导出空格数目与 n 的取值为 n-i(i为行数)
每行输出字符与字符数目的与行数的关系:字符数目可以很容易推导得到2*行数-1=每行字符数目,每行字符种类,以ASCII码作为锚点,推导得到A+i-1
利用string语法,分别构造空格数目,空格;字符数目,字符种类的字符串,进行拼接即可
//图形输出
//输入样例 2
// A
// 输出样例 BBB
#include<iostream>
#include<string.h>
using namespace std;
int main()
{
int n;
cin>>n;
for(int i=1;i<=n;i++)
{
string space =string(n-i,' ');
string ch=string (2*i-1, 'A'+i-1);
cout <<space+ch<<endl;
}
return 0;
}
//测试结果:测试通过 题目3: 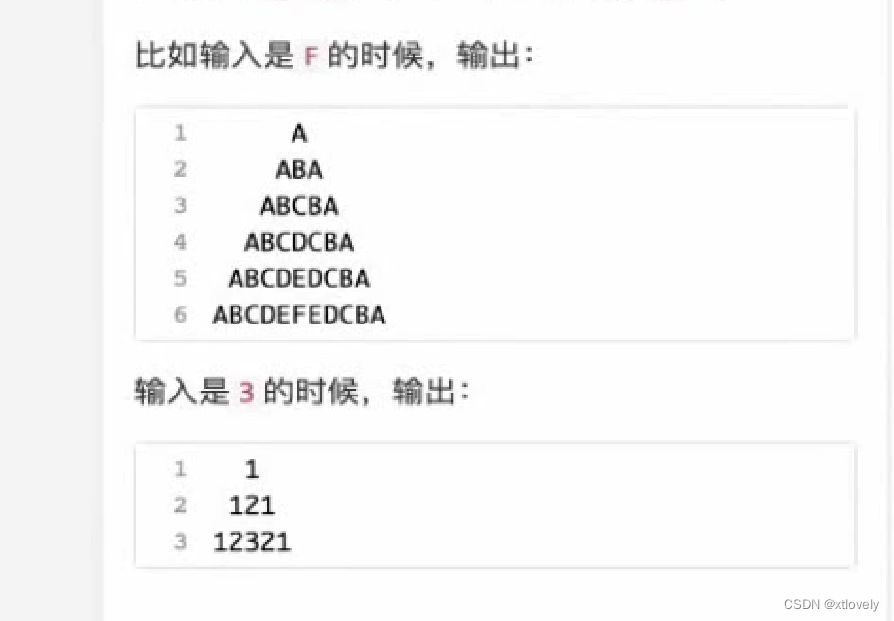
题目分析:题目3与题目2的区别在于,每行的输出不再是以单个字符进行输出,但是每行的字符 数目仍然满足2*i-1的关系(i为行数)
需要解决:当输入的为字符时,计算其行数,利用ASCII码,行数i满足: 输入字符的ASCII码-‘A’的ASCII码+1=行数
举例:当输入字符为C时,根据ASCII码对照表,行数=67-65+1=3,关系成立
接下来该解决每行出现的空格数目问题,由于输入的为字符,则题目2所推导的关系不能用,当一共有三行时,第一行的空格数目为2,第二行空格数目为1,依旧满足 输入字符-‘A’+1的关系
解决完空格问题,开始着手看如何写出每行出现的字符串,分析每行特征,会得到如下关系,先增长后下降,,即由两部分组成
对于第一部分增长的情况 可以利用A+j-1推出(不知道怎么推的记住这个套路就行),递减的部分反过来写就可以
注意:(1)在必须将输出cout强转成char类型,否则会出现输出错误的问题
(2)三个for循环是地位相同的,其逻辑是在 最外层的i为1时,先执行内层的第一个for循环以输出空格,该循环结束后,i=1来到内层第二个for循环,输出递增的字符串,接着来到 第三个for循环执行字符串递减的循环,结束之后跳出来,在最外层i=2继续以上过程
//图形输出进阶
//输出有两种情况:字母或数字
//输入样例:D
//输出样例: A
// ABA
// ABCBA
// ABCDCBA
#include<iostream>
#include<string.h>
using namespace std;
int main()
{
char c;
cin>>c;
if(c>='A'&&c<='Z')
{
for (int i=1;i<=c-'A'+1;i++)
{
for (int j=1;j<=c-'A'+1-i;j++){
cout<<" ";
}//空白字符
for (int j=1;j<=i;j++ )
{
cout<<(char)('A'+j-1);
}
for (int j=i-1;j>=1;j--)
{
cout<<(char)('A'+j-1);
}
cout<<endl;
}
}
else
{
for (int i=1;i<=c-'1'+1;i++)
{
for (int j=1;j<=c-'1'+1-i;j++){
cout<<" ";
}//空白字符
for (int j=1;j<=i;j++ )
{
cout<<(char)('1'+j-1);
}
for (int j=i-1;j>=1;j--)
{
cout<<(char)('1'+j-1);
}
cout<<endl;
}
}
return 0;
}
//测试结果:测试通过 题目4:
题目分析:将+-看成一组,输入 两个数字,行数和列数,用for循环完成行数,在每一行里完成输出+-和|*
此题比较简单,故不再赘述
//造房子
//输入样例 2 2
//输出样例 +-+-+
// |*|*|
// +-+-+
// |*|*|
// +-+-+
#include<iostream>
#include<string.h>
using namespace std;
int main()
{
int m;int n;
cin>>m>>n;
for (int i=1; i<=n ;i++)
{
for (int j=1;j<=m;j++)
{
cout<<"+-";
}
cout<<"+"<<endl;
for (int j=1;j<=m;j++)
{
cout<<"|*";
}
cout<<"|"<<endl;
}
for (int j=1;j<=m;j++)
{
cout<<"+-";
}
return 0;
}
//测试结果:测试通过 题目5:匹配字符串
即统计A字符串里出现了多少次b字符串
题目分析:欲统计出现了多少次,需要先将两个字符串读入
读入方式上有两种
方法一:
char a[100];
char b[100];
int main()
{
int len1 ;
int len2;
len1=strlen(a);
len2=strlen(b);
for(int i=0;i<=len1;i++)
{
cin>>a[i];
}
for(int j=0;j<=len1;j++)
{
cin>>a[j];
}由以上代码可以及将两个字符串读入
也可以 利用fgets语句
char s1[1000];
char s2[1000];
int main()
{
fgets(s1,1000,stdin);//fgsts有三个参数,分别为数组名,数组大小,输方式,一般为stdin即默认输入
fgets(s2,1000,stdin);
}在读入两个字符串之后, 开始循环比较两个字符串,用测试样例来说,a字符串比b 字符串长,则停止条件是i+len2<len1,也就是i<len1-len2时,关于这个循环停止条件,可以如此理解,len1-len2的结果就是len2超出长度,当i读到len1-len2时,再往下读一位,短的字符串已经没有了,因此循环停止条件就是i<len1-len2
bool 类型用来判断if条件是否执行,bool matched=1;这是将matched 先初始化为1
p3:使用sort排序
首先需要提到,sort排序是C++内置的一种排序算法,可以从小到大和从大到小输出,比起手写冒泡算法 ,使用sort排序是一种极为方便的方法,sort排序要首先包含头文件<algorithm>
题目1:统计班上前k名学生的分数 平均数
输入样例:
10//共输入多少个学生成绩
93 85 77 68 59 100 43 94 75 82//学生成绩
4 //前4名学生成绩
题目分析:这种题目的难点本身在于如何在读入10名学生的成绩后 按照从大到小的顺序排好,如果没有sort排序的话,我们需要手写冒泡算法,但是在sort排序里,只需要写入sort(score,score+N,greater<int>())后,数组score内部的顺序就已经排好序了,要注意的是sort排序的写法是起始位置,终止位置,排序方式,在缺省的情况下默认从小到大的方式来排序
本题的起始位置是score[0],简化成了score,虽然我们开了101位数组大小但是显然我们排序的终止位置却决于我们一共输入了 多少成绩,这是显而易见的,在确定好起止位置之后这道题就解决了
#include<iostream>
#include<string.h>
#include<algorithm>
using namespace std;
int score[100];
int main()
{
int N;
int k;
int sum;
cin>>N;
for(int i=0;i<N;i++)
{
cin>>score[i];
}
cin>>k;
sort(score,score+N,greater<int>());//在这一步已经改变了数组内部的顺序
sum=0;
for(int i=0;i<k;i++)
{
sum+=score[i];
}
cout<<sum/k<<endl;
}题目2:把N名学生的成绩放在a数组中,各分数段的人数存到b数组中,不同分数段的学生人数分别存到b[0],b[1]........
题目分析:这道题目的流程很清晰:开一个成绩数组--再开一个人数数组--写入成绩--使用sort排序由大到小--利用for循环从0到N依次判断每个成绩所属的区间--分别让对应的b数组数字加1即可
#include<string.h>
#include<iostream>
#include<algorithm>
using namespace std;
int score[100];
int b[100];
int main()
{
int N;
cin>>N;
for(int i=0;i<N;i++)
{
cin>>score[i];
}
sort (score,score+N,greater<int>());
for(int i=0;i<N;i++)
{
cout<<score[i];
}
for(int i=0;i<N;i++)
{
if(score[i]==100)
{
b[1]++;
}
else if(score[i]<=90)
{
b[2]++;
}
else if(score[i]>=80)
{
b[3]++;
}
else if(score[i]>=70)
{
b[4]++;
}
else if(score[i]>=60)
{
b[5]++;
}
}
for(int i=0;i<=6;i++)
{
cout<<b[i]<<endl;
}
}题目3: 输入n个整数,要求将这些数字按照3的余数大小排序,余3的数越大约先输出,否则按照两个数的较大值先输出
题目分析:这道题的亮点在于自定义了一种比较方法,也就是bool cmp(),同时在sort排序里声明了这种排序方式sort (num,num+N,cmp),前面几道题的greather也是这种类型
关于bool cmp(int a,int b),与函数有相似点又有不同,首先是数据类型的不同,他是bool 类型,所以他的返回值类型只有两种,其次,他的作用只是在sort排序中使用,不像函数一样定义好之后可以在主函数中复用,最后,自定义比较方法的定义是在main 函数之前,而函数在主函数里定义
回归本题,自定义的比较方法逻辑清晰,如果两个数余3的值不相等,返回两个数里余3值较大的那个,否则返回两个数里较大的那个
#include<iostream>
#include<string.h>
#include<algorithm>
#include<cmath>
using namespace std;
int num[105];
bool cmp(int a ,int b)
{
if(a%3!=b%3){
return a%3<b%3;
}
else
{
return a<b;
}
}
int main()
{
int N;
cin>>N;
for(int i=0;i<N;i++)
{
cin>>num[i];
}
sort(num,num+N,cmp);
for(int i=0;i<N;i++)
{
cout<<num[i];
}
return 0;
} 题目4:结构体的定义
结构体语法是(以构造一个学生的信息结构体为例子)
struct student()
{
string name;
int score[10];
}
而结构体与类的区别在于
类存储在堆上,结构体存储在栈上,类的继承和多态在结构体上无法使用
题目5:一个学生有一个姓名和四科的成绩,这样的学生有3个,将他们按照姓名的顺序排序并输出
题目分析:利用结构体,里面有学生的姓名和成绩,成绩由于是4科所以开4个数组,在利用两个循环分别读入姓名和成绩后,创建cmp自定义的排序方法,逻辑是返回两个名字中较大的那个
特别注意:结构体与类class一样,使用前要进行实例化
除此之外这道题目没有其他的难点
#include<iostream>
#include<string>
#include<algorithm>
using namespace std;
struct student{
string name;
int score[4];
};
bool cmp(student x,student y)
{
return x.name<y.name;
}
int main()
{
student stu[3];
for (int i=0;i<3;i++){
cin>>stu[i].name;
for (int j=0;j<4;j++){
cin>>stu[i].score[j];
}
}
sort(stu,stu+3,cmp);
for (int i=0;i<3;i++){
cout<<stu[i].name<<" :";
for (int j=0;j<4;j++){
cout<<stu[i].score[j]<<" ";
}
}
}题目6:有N名同学,进行了4门考试,要求找出这N名学生的前3名
题目分析:要求找出前三名,首先需要输入这N 名学生的姓名和 成绩,分别是for(int i=0;i<N;i++)和(int j=0;j<3;j++),同时需要创捷结构体里面有学生的姓名和成绩,接下来就是sort排序,要进行sort排序的前置条件是实例化和创建比较方法
先说bool cmp(student x,student y) ,在之前的自定义比较方法里,数据类型一般是int ,这里用student 的原因也很简单,因为最终要传进去的是两个结构体,这两个结构体的数据类型就是student
再说实例化,使用结构体就需要实例化,到主函数里输出输出都是stu[i].name;试想假如不实例化那么输出输出根本就没有对象。
#include<iostream>
#include<string>
#include<algorithm>
using namespace std;
int score[2000];
struct student{
char name[100];
int score[4];
};
bool cmp(student x,student y)
{
int sumx=x.score[0]+x.score[1]+x.score[2]+x.score[3];
int sumy=y.score[0]+y.score[1]+y.score[2]+y.score[3];
return sumx>sumy;
}
student stu[50];
int main()
{
int N;
cin>>N;
for(int i=0;i<N;i++)
{
cin>>stu[i].name;
for(int j=0;j<4;j++)
{
cin>>stu[i].score[j];
}
}
sort (stu,stu+N,cmp);
for(int i=0;i<3;i++)
{
cout<<stu[i].name;
}
}p4:枚举算法(暴力破解)
题目一:回文数,例如12321这种无论是从前往后还是从后往前都是一样顺序的就是回文数,因此给定一个五位或者六位数,找出这里面所有的回文数,输入一个n,则这些回文数字各数位之和等于n
题目分析:这个六位数或者五位数比较好生成,利用for循环搞一下就可以,本题的 精妙之处在于while和bool 的使用,同时bool里面的for循环的判断条件也是精准而迅速,下面逐一分析
首先在生成五位或六位数且读入n之后,本应直接在主函数的for循环内来写判断条件,但是如此一来就牵扯到两个问题:1.每一位判断完之后的退位问题 2.判断每一位是否是回文的问题,比较复杂,所以干脆利用自定义的judge函数来完成
因此本题核心在于judge函数里:1.dight数组的作用是把每一个数位都清理出来,由于最大只有6位数,所以dight的大小开6位足够,接着利用while循环不断将每一位的和加到sum 里面,剥离数字n的每一位的操作就是n%10,n/10;接下来把每一位剥离下来放到dight数组而且每一位的和sum已经得出,判断它的和是否等于输入的n,如果不等直接退出,如果相等,判断他是否是回文:将这个数一分为二,首位和末尾相等,依次类推。
bool函数和while 函数放在这里异常合适
#include<iostream>
#include<string.h>
#include<algorithm>
#include<cmath>
using namespace std;
int n;
int digit[6];
bool judge(int x){
int m=0,sum=0;
while (x){
digit[m++]=x%10;
sum+=x%10;
x/=10;
}
if (sum!=n)
{
return 0;
}
for(int i=0;i<m/2;i++){
if(digit[i]!=digit[m-1-i]){
return 0;
}
}
return 1;
}
int main()
{
bool f=0;
cin>>n;
for (int i=10000;i<1000000;i++)
{
if (judge(i)){
cout<<i<<endl;
f=1;
}
}
if(!f){
cout<<-1<<endl;
}
return 0;
} 题目二:玫瑰花数,如果一个四位数他的每个位上的数字4次幂之和等于他本身,那么我们就称这个数字是玫瑰花数,找出所有的玫瑰花数
题目分析:很清晰的一道题,同样在生成数的for循环里利用自定义的rose函数来完成,亮点是对每一位的剥离,对个位直接%10,十位除10露出末位3,用10取余拿到十位,依次类推。定义ans来计算他们的和,判断每一个ans是否相等,此题完成
//一个四位数,他的每一位上的数字的4次幂之和等于他本身,找出所有的四叶玫瑰数
#include<iostream>
#include<string.h>
#include<algorithm>
#include<cmath>
using namespace std;
bool rose(int i)
{
int a=i/1000;
int b=i/100%10;
int c=i/10%10;
int d=i%10;
int ans=a*a*a*a+b*b*b*b+c*c*c*c+d*d*d*d;
if(ans==i){
return 1;
}
else {
return 0;
}
}
int main()
{
int n;
cin>>n;
if(n<1000||n>9999){
cout<<"错误"<<endl;
}
else {
for(int i=1000;i<=n;i++)
{
if(rose(i)){
cout<<i<<endl;
}
}
}
}
题目三:生日蜡烛问题,某人每年都举办一次生日派对,并且每年都要吹熄与年龄相同根数的蜡烛,现在算起来他一共吹熄了236根蜡烛,那么他是从多少岁开始过生日派对的
题目分析:首先我们需要枚举这个人开始过生日的年龄,从0到200,接下来一次枚举他从某岁到某岁之间会吹多少蜡烛,如果这个数目超过236,由于无法确定循环的次数,所以用到while 循环
跳出while 循环后,如果蜡烛数目恰好等于236说明枚举条件成立,变量i 的值就是他开始过生日的年龄,can 用于记录蜡烛数目,j是一个累加变量
//生日蜡烛问题
#include<iostream>
#include<string.h>
#include<algorithm>
#include<cmath>
using namespace std;
int main(){
for(int i=1;i<=200;i++)
{
int can,j=i;
while (can<236&&j<=200){
can+=j;
j++;
}
if(can==236){
cout<<i<<endl;
}
}
return 0;
}题目4:奖券数目,某次抽奖活动的奖券号码是五位数,要求其中不出现带4的号码,计算一下,在n到m之间(是五位数),在不重复的条件下可以发行多少张
题目分析:
//奖券数目 某奖券号码是5位数,要求其中不要出现带4的号码,如果发行号码n到m 之间的奖券,可以发售多少张
#include<iostream>
#include<string.h>
#include<algorithm>
#include<cmath>
using namespace std;
bool judge(int x){
while (x){
if(x%10==4){
return 1;
}
x/=10;
}
return 0;
}
int cnt;
int main()
{
int cnt;
int n,m;
cin>>n>>m;
for(int i=n;i<=m;i++)
{
if(!judge(i))
{
cnt++;
}
}
cout<<cnt<<endl;
return 0;
}
p5:回溯算法(dfs)
距离上次更新博客已经过去了很长时间,主要是被dfs算法搞得欲仙欲死,接下的更新过程将以基本dfs模板->计蒜客的几个抽象dfs问题->'一只会code的小金鱼'的十个dfs算法为更新过程,其中将会穿插以'代码随想录中'算法思想画出树状图以辅助理解
接下来开始
在开始之前有必要对题型做一下归纳,大致可以分为以下几种
- 组合问题:N个数里面按一定规则找出k个数的集合
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 棋盘问题:N皇后,解数独等等
基本的dfs模板
int a[510]; //存储每次选出来的数据
int book[510]; //标记是否被访问
int ans = 0; //记录符合条件的次数
void DFS(int cur){
if(cur == k){ //k个数已经选完,可以进行输出等相关操作
for(int i = 0; i < cur; i++){
printf("%d ", a[i]);
}
ans++;
return ;
}
for(int i = 0; i < n; i++){ //遍历 n个数,并从中选择k个数
if(!book[i]){ //若没有被访问
book[i] = 1; //标记已被访问
a[cur] = i; //选定本数,并加入数组
DFS(cur + 1); //递归,cur+1
book[i] = 0; //释放,标记为没被访问,方便下次引用
}
}
}
基本上的结构就是这样,需要有一个bool vis[]数组来记录是否被选过,arr[]数组来记录结果,在dfs函数里涉及两部分。1,函数的递归出口,2.下一步应该干什么
接下来开始计蒜客抽象dfs的第一题 给定n个整数,选出k 个数,使得选出来的k 个数的和为sum
思考过程:这是几大题型里的组合问题,选出1,2和选出2,1显然并无区别,树的宽度取决于给了几个数,树的深度取决于要选几个数
代码如下
/给n个数选出k个使得和为sum
#include<iostream>
using namespace std;
int n,k,sum;
int ans;
bool vis[1000];
int a[1000];
void dfs(int s,int cnt)
{
if(s==sum&&cnt==k)
{
ans++;
}
for(int i=1;i<=n;i++)
{
if(!vis[i])
{
vis[i]=1;
dfs(s+a[i],cnt+1);
vis[i]=0
}
}
}
int main()
{
cin>>n>>k>>sum;
for(int i=0;i<n;i++)
{
cin>>arr[i];
}
ans=0;
dfs(0,0);
cout<<ans<<endl;
}基本符合上述给的模板
接下来是三角形问题



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









