







教您使用java爬虫gecco抓取JD全部商品信息
gecco爬虫
如果对gecco还没有了解可以参看一下gecco的github首页。gecco爬虫十分的简单易用,JD全部商品信息的抓取9个类就能搞定。
JD网站的分析
要抓取JD网站的全部商品信息,我们要先分析一下网站,京东网站可以大体分为三级,首页上通过分类跳转到商品列表页,商品列表页对每个商品有详情页。那么我们通过找到所有分类就能逐个分类抓取商品信息。
入口地址
http://www.jd.com/allSort.aspx,这个地址是JD全部商品的分类列表,我们以该页面作为开始页面,抓取JD的全部商品信息
新建开始页面的HtmlBean类AllSort
@Gecco(matchUrl="http://www.jd.com/allSort.aspx", pipelines={"consolePipeline", "allSortPipeline"})
public class AllSort implements HtmlBean {
private static final long serialVersionUID = 665662335318691818L;
@Request
private HttpRequest request;
//手机
@HtmlField(cssPath=".category-items > div:nth-child(1) > div:nth-child(2) > div.mc > div.items > dl")
private List<Category> mobile;
//家用电器
@HtmlField(cssPath=".category-items > div:nth-child(1) > div:nth-child(3) > div.mc > div.items > dl")
private List<Category> domestic;
public List<Category> getMobile() {
return mobile;
}
public void setMobile(List<Category> mobile) {
this.mobile = mobile;
}
public List<Category> getDomestic() {
return domestic;
}
public void setDomestic(List<Category> domestic) {
this.domestic = domestic;
}
public HttpRequest getRequest() {
return request;
}
public void setRequest(HttpRequest request) {
this.request = request;
}
}
可以看到,这里以抓取手机和家用电器两个大类的商品信息为例,可以看到每个大类都包含若干个子分类,用List\
获取页面元素cssPath的小技巧
上面两个类难点就在cssPath的获取上,这里介绍一些cssPath获取的小技巧。用Chrome浏览器打开需要抓取的网页,按F12进入发者模式。选择你要获取的元素,如图:
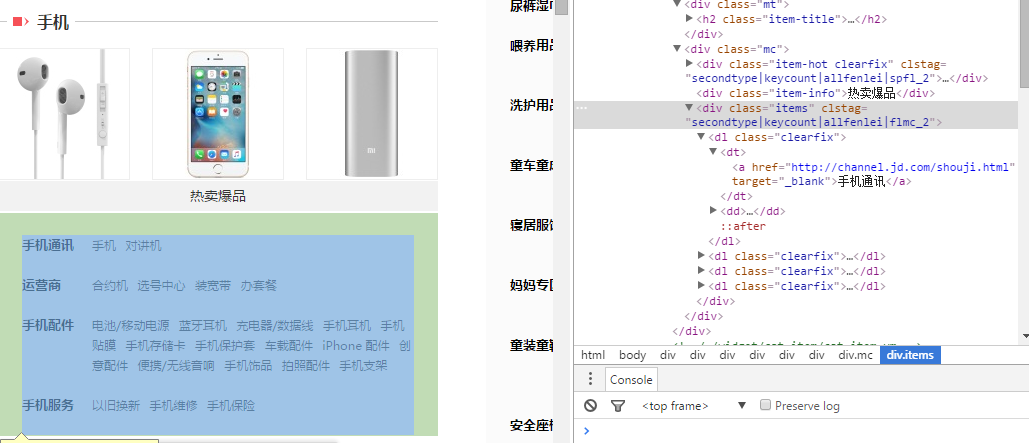
在浏览器右侧选中该元素,鼠标右键选择Copy–Copy selector,即可获得该元素的cssPath
body > div:nth-child(5) > div.main-classify > div.list > div.category-items.clearfix > div:nth-child(1) > div:nth-child(2) > div.mc > div.items
如果你对jquery的selector有了解,另外我们只希望获得dl元素,因此即可简化为:
.category-items > div:nth-child(1) > div:nth-child(2) > div.mc > div.items > dl
编写AllSort的业务处理类
完成对AllSort的注入后,我们需要对AllSort进行业务处理,这里我们不做分类信息持久化等处理,只对分类链接进行提取,进一步抓取商品列表信息。看代码:
@PipelineName("allSortPipeline")
public class AllSortPipeline implements Pipeline<AllSort> {
@Override
public void process(AllSort allSort) {
List<Category> categorys = allSort.getMobile();
for(Category category : categorys) {
List<HrefBean> hrefs = category.getCategorys();
for(HrefBean href : hrefs) {
String url = href.getUrl()+"&delivery=1&page=1&JL=4_10_0&go=0";
HttpRequest currRequest = allSort.getRequest();
SchedulerContext.into(currRequest.subRequest(url));
}
}
}
}
@PipelinName定义该pipeline的名称,在AllSort的@Gecco注解里进行关联,这样,gecco在抓取完并注入Bean后就会逐个调用@Gecco定义的pipeline了。为每个子链接增加”&delivery=1&page=1&JL=4_10_0&go=0”的目的是只抓取京东自营并且有货的商品。SchedulerContext.into()方法是将待抓取的链接放入队列中等待进一步抓取。
抓取商品列表信息
AllSortPipeline已经将需要进一步抓取的商品列表信息的链接提取出来了,可以看到链接的格式是:http://list.jd.com/list.html?cat=9987,653,659&delivery=1&JL=4_10_0&go=0。因此我们建立商品列表的Bean——ProductList,代码如下:
@Gecco(matchUrl="http://list.jd.com/list.html?cat={cat}&delivery={delivery}&page={page}&JL={JL}&go=0", pipelines={"consolePipeline", "productListPipeline"})
public class ProductList implements HtmlBean {
private static final long serialVersionUID = 4369792078959596706L;
@Request
private HttpRequest request;
/**
* 抓取列表项的详细内容,包括titile,价格,详情页地址等
*/
@HtmlField(cssPath="#plist .gl-item")
private List<ProductBrief> details;
/**
* 获得商品列表的当前页
*/
@Text
@HtmlField(cssPath="#J_topPage > span > b")
private int currPage;
/**
* 获得商品列表的总页数
*/
@Text
@HtmlField(cssPath="#J_topPage > span > i")
private int totalPage;
public List<ProductBrief> getDetails() {
return details;
}
public void setDetails(List<ProductBrief> details) {
this.details = details;
}
public int getCurrPage() {
return currPage;
}
public void setCurrPage(int currPage) {
this.currPage = currPage;
}
public int getTotalPage() {
return totalPage;
}
public void setTotalPage(int totalPage) {
this.totalPage = totalPage;
}
public HttpRequest getRequest() {
return request;
}
public void setRequest(HttpRequest request) {
this.request = request;
}
}
currPage和totalPage是页面上的分页信息,为之后的分页抓取提供支持。ProductBrief对象是商品的简介,主要包括标题、预览图、详情页地址等。
public class ProductBrief implements HtmlBean {
private static final long serialVersionUID = -377053120283382723L;
@Attr("data-sku")
@HtmlField(cssPath=".j-sku-item")
private String code;
@Text
@HtmlField(cssPath=".p-name> a > em")
private String title;
@Image({"data-lazy-img", "src"})
@HtmlField(cssPath=".p-img > a > img")
private String preview;
@Href(click=true)
@HtmlField(cssPath=".p-name > a")
private String detailUrl;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getPreview() {
return preview;
}
public void setPreview(String preview) {
this.preview = preview;
}
public String getDetailUrl() {
return detailUrl;
}
public void setDetailUrl(String detailUrl) {
this.detailUrl = detailUrl;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
}
这里需要说明一下@Href(click=true)的click属性,click属性形象的说明了,这个链接我们希望gecco继续点击抓取。对于增加了click=true的链接,gecco会自动加入下载队列中,不需要在手动调用SchedulerContext.into()增加。
编写ProductList的业务逻辑
ProductList抓取完成后一般需要进行持久化,也就是将商品的基本信息入库,入库的方式有很多种,这个例子并没有介绍,gecco支持整合spring,可以利用spring进行pipeline的开发,大家可以参考gecco-spring这个项目。本例子是进行了控制台输出。ProductList的业务处理还有一个很重要的任务,就是对分页的处理,列表页通常都有很多页,如果需要全部抓取,我们需要将下一页的链接入抓取队列。
@PipelineName("productListPipeline")
public class ProductListPipeline implements Pipeline<ProductList> {
@Override
public void process(ProductList productList) {
HttpRequest currRequest = productList.getRequest();
//下一页继续抓取
int currPage = productList.getCurrPage();
int nextPage = currPage + 1;
int totalPage = productList.getTotalPage();
if(nextPage <= totalPage) {
String nextUrl = "";
String currUrl = currRequest.getUrl();
if(currUrl.indexOf("page=") != -1) {
nextUrl = StringUtils.replaceOnce(currUrl, "page=" + currPage, "page=" + nextPage);
} else {
nextUrl = currUrl + "&" + "page=" + nextPage;
}
SchedulerContext.into(currRequest.subRequest(nextUrl));
}
}
}
JD的列表页通过page参数来指定页码,我们通过替换page参数达到分页抓取的目的。至此,所有的商品的列表信息都已经可以正常抓取了。
详情页抓取
商品的基本信息抓取完成后,就要针对每个商品的详情页进行抓取,可以看到详情页的地址格式一般如下:http://item.jd.com/1861098.html。我们建立商品详情页的Bean:
@Gecco(matchUrl="http://item.jd.com/{code}.html", pipelines="consolePipeline")
public class ProductDetail implements HtmlBean {
private static final long serialVersionUID = -377053120283382723L;
/**
* 商品代码
*/
@RequestParameter
private String code;
/**
* 标题
*/
@Text
@HtmlField(cssPath="#name > h1")
private String title;
/**
* ajax获取商品价格
*/
@Ajax(url="http://p.3.cn/prices/get?skuIds=J_[code]")
private JDPrice price;
/**
* 商品的推广语
*/
@Ajax(url="http://cd.jd.com/promotion/v2?skuId={code}&area=1_2805_2855_0&cat=737%2C794%2C798")
private JDad jdAd;
/*
* 商品规格参数
*/
@HtmlField(cssPath="#product-detail-2")
private String detail;
public JDPrice getPrice() {
return price;
}
public void setPrice(JDPrice price) {
this.price = price;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public JDad getJdAd() {
return jdAd;
}
public void setJdAd(JDad jdAd) {
this.jdAd = jdAd;
}
public String getDetail() {
return detail;
}
public void setDetail(String detail) {
this.detail = detail;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
}
@RequestParameter可以获取@Gecco里定义的url变量{code}。
@Ajax是页面中的ajax请求,JD的商品价格和推广语都是通过ajax请求异步获取的,gecco支持异步ajax请求,指定ajax请求的url地址,url中的变量可以通过两种方式指定。
一种是花括号{},可以获取request的参数类似@RequestParameter,例子中获取推广语的{code}是matchUrl=”http://item.jd.com/{code}.html”中的code;
一种是中括号[],可以获取bean中的任意属性。例子中获取价格的[code]是变量private String code;。
json数据的元素抽取
商品的价格是通过ajax获取的,ajax一般返回的都是json格式的数据,这里需要将json格式的数据抽取出来。我们先定义价格的Bean:
public class JDPrice implements JsonBean {
private static final long serialVersionUID = -5696033709028657709L;
@JSONPath("$.id[0]")
private String code;
@JSONPath("$.p[0]")
private float price;
@JSONPath("$.m[0]")
private float srcPrice;
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
public float getSrcPrice() {
return srcPrice;
}
public void setSrcPrice(float srcPrice) {
this.srcPrice = srcPrice;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
}
我们获取的商品价格信息的json数据格式为:[{“id”:”J_1861098”,”p”:”6488.00”,”m”:”7488.00”}]。可以看到是一个数组,因为这个接口其实可以批量获取商品的价格。json数据的数据抽取使用@JSONPath注解,语法是使用的fastjson的JSONPath语法。
JDad的抓取类似,下面是Bean的代码:
public class JDad implements JsonBean {
private static final long serialVersionUID = 2250225801616402995L;
@JSONPath("$.ads[0].ad")
private String ad;
@JSONPath("$.ads")
private List<JSONObject> ads;
public String getAd() {
return ad;
}
public void setAd(String ad) {
this.ad = ad;
}
public List<JSONObject> getAds() {
return ads;
}
public void setAds(List<JSONObject> ads) {
this.ads = ads;
}
}
学会分析ajax请求
目前爬虫抓取页面内容针对ajax请求有两种主流方式:
- 一种是模拟浏览器将页面完全绘制出来,比如可以利用htmlunit。这种方式存在一个问题就是效率低,因为页面中的所有ajax都会被请求,而且需要解析所有的js代码。gecco可以通过自定义downloader来实现这种方式
- 还一种就是需要哪些ajax就执行哪些,这就要开发人员分析网页中的ajax请求,获得请求的地址,比如抓取JD的商品价格的地址@Ajax(url=”http://p.3.cn/prices/mgets?skuIds=J_[code]”)。而且这个地址之后可能会变。
这两种方式都有各自的优缺点,gecco通过扩展都支持,本人还是更倾向于使用第二种方式。
下面说说怎么分析页面中的ajax请求,还是要利用chrome的开发者模式,network选项可以看到页面中的所有请求:
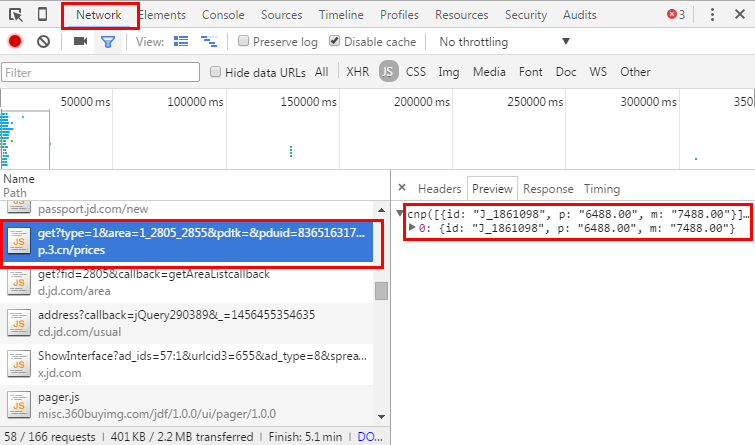
可以看到请求的地址是:http://p.3.cn/prices/get?type=1&area=1_2805_2855&pdtk=&pduid=836516317&pdpin=&pdbp=0&skuid=J_1861098&callback=cnp。我们去掉其他参数只留下商品的代码,发现一样可以访问,http://p.3.cn/prices/get?
skuid=J_1861098就是我们要请求的地址。
gecco的其他一些有用的特性
- gecco支持页面中的定义的全局javascript变量的提取,如页面中定义的var变量。
- gecco支持分布式抓取,通过redis管理startRequest实现分布式抓取。
源码
全部源代码可以在gecco的github上下载,代码位于src/test/java/com/geccocrawler/gecco/demo/jd包下。如果使用过程中发现任何bug欢迎Pull request,或者通过Issue提问,当然也可以在博客中留言。















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









