







参考:
向 Linux kernel 社区提交patch补丁步骤总结(已验证成功)_发patch包-CSDN博客
向 Linux 内核社区提交补丁的流程 - 我的笔记集 | RaverStern
作为一个Linux开发人员,但是又不是kernel开发。能够向内核提交代码,一直觉得是一件很cool的事情。最近在开发AMD V3K SOC相关的代码的时候,终于发现了kernel的一些bug,并成功的向内核提交了batch。也算是完成了一个个人的里程碑吧。所以记录一下。
大概流程2周,还提交了两个patch,有点超出预料。
发现第一个bug,主要是因为需要用AMD的SPI controller去接一颗SPI NOR。
AMD SPI driver这里的bug很多,其实挖一下可以修很多bug...但是看代码的过程中,还是发现了spi子系统middle layer的spi-mem有一些缺陷,然后修起来又比较简单,所以就作为试水发了一个patch。
8月5号,发出的patch

8月5号就收到原作者review确认。
8月6号maintainer就确认可以合入。
内核开发的效率还是非常高的。
第二个patch是关于intel igb driver的,net下面的问题,review似乎更加严格。
虽然只是修改一行代码,但是有3个人review了。
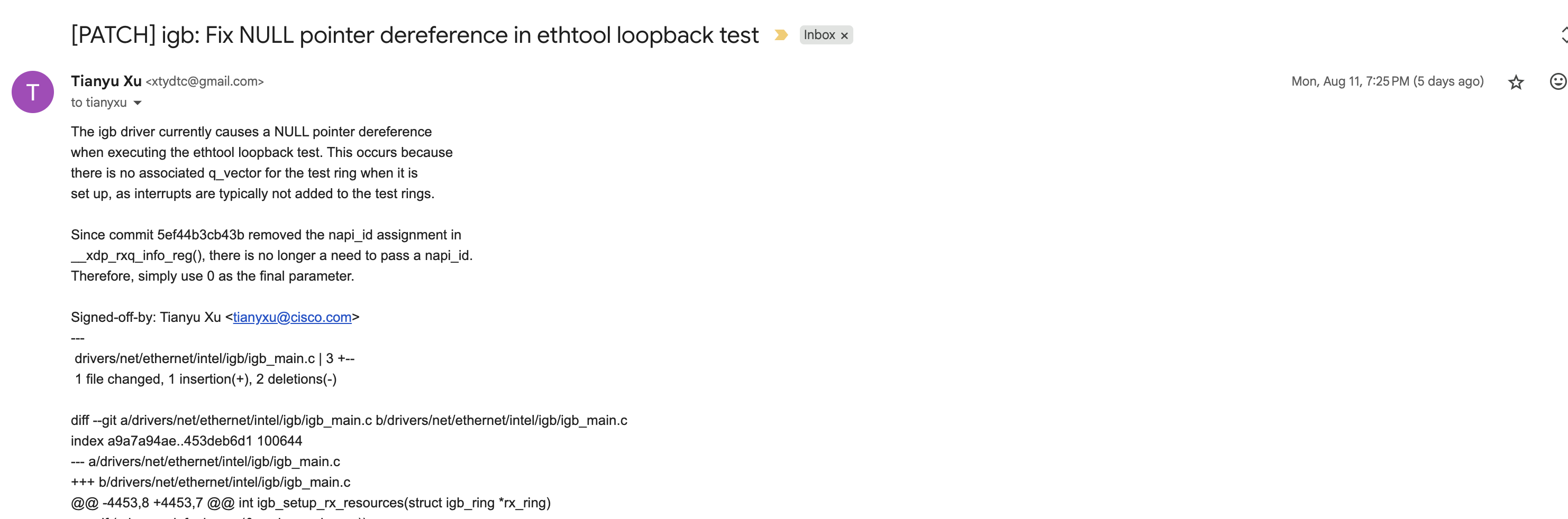
8月11号发出patch,8月11号和12号收到2位reviewers的关于git message规范的comments。
于是8月12号又发出了修改之后的patch。
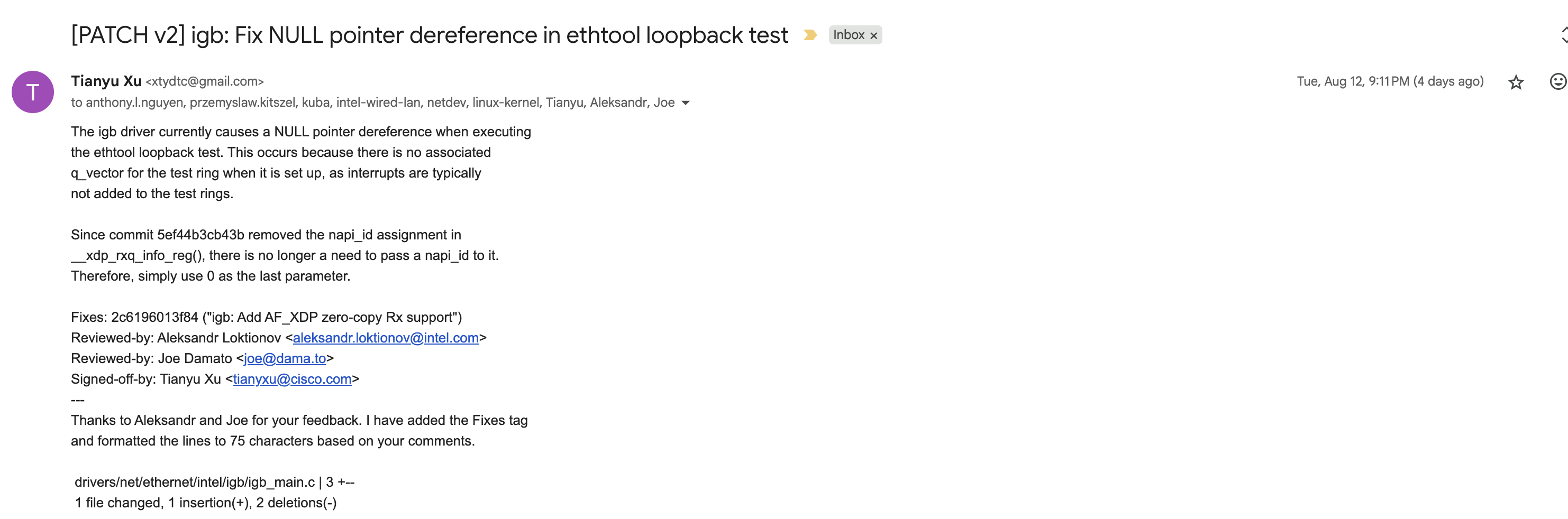
8月12号有reviewer询问如何测试修改。
8月13号回复如何测试。
8月15号maintainer私信说合入他的某个branch。

整个PR流程给我的感觉是内核开发非常活跃,然后开发流程也非常科学。通过git send-email,./scripts/get_maintainer.pl,git format-patch/patchwork等工具非常流畅的发布patch。
对于git message的规范也非常有利于代码review理解和记录。
在commit message中记录why(root cause)和how,以及fix的问题是哪个commit引入的。确实非常好。

















 1462
1462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









