







引言
SSD是目前商用服务器上非常流行的存储介质,因此,作为软件开发人员,需要了解的SSD基本原理,以便开发时能更好地发挥其优势,规避其劣势。本文总结了作为软件开发人员需要了解的SSD基本原理,全文组织结构如下:
- SSD的读写速度
- SSD内部芯片的简单存取原理
- SSD的读写特性
- SSD的over-provisioning和garbage-collection
- SSD的损耗均衡控制
- SSD的写放大问题
SSD的读写速度
首先,从软件开发人员作为SSD的用户角度来讲,首先需要了解的是SSD和普通HDD的性能对比,如下:
先来看顺序读和顺序写


其中,Seagate ST3000DM001是HDD,其他的都是SSD。从上述两图中可以看出,HDD的顺序读速度差不多为最慢的SSD的一半,顺序写稍微好点,但也比大部分慢一倍左右的速度。
再来看随机读和随机写

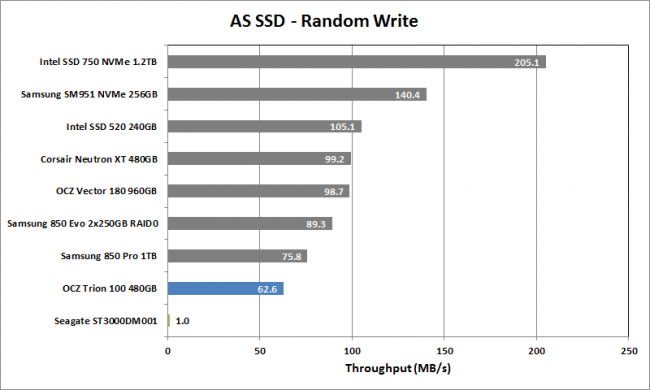
可以看出,HDD的随机读的性能是普通SSD的几十分之一,随机写性能更差。
因此,SSD的随机读和写性能要远远好于HDD,本文接下来的几个小节将会讨论为什么SSD的随机读写性能要远远高于HDD?
备注:本小节测试数据全部来自于HDD VS SSD。
SSD内部芯片的简单存储原理
SSD内部一般使用NAND Flash来作为存储介质,其逻辑结构如下:

SSD中一般有多个NAND Flash,每个NAND Flash包含多个Block,每个Block包含多个Page。由于NAND的特性,其存取都必须以page为单位,即每次读写至少是一个page,通常地,每个page的大小为4k或者8k。另外,NAND还有一个特性是,其只能是读或写单个page,但不能覆盖写如某个page,必须先要清空里面的内容,再写入。由于清空内容的电压较高,必须是以block为单位。因此,没有空闲的page时,必须要找到没有有效内容的block,先擦写,然后再选择空闲的page写入。
在SSD中,一般会维护一个mapping table,维护逻辑地址到物理地址的映射。每次读写时,可以通过逻辑地址直接查表计算出物理地址,与传统的机械磁盘相比,省去了寻道时间和旋转时间。
SSD读写特性
从NAND Flash的原理可以看出,其和HDD的主要区别为
- 定位数据快:HDD需要经过寻道和旋转,才能定位到要读写的数据块,而SSD通过mapping table直接计算即可
- 读取速度块:HDD的速度取决于旋转速度,而SSD只需要加电压读取数据,一般而言,要快于HDD
因此,在顺序读测试中,由于定位数据只需要一次,定位之后,则是大批量的读取数据的过程,此时,HDD和SSD的性能差距主要体现在读取速度上,HDD能到200M左右,而普通SSD是其两倍。
在随机读测试中,由于每次读都要先定位数据,然后再读取,HDD的定位数据的耗费时间很多,一般是几毫秒到十几毫秒,远远高于SSD的定位数据时间(一般0.1ms左右),因此,随机读写测试主要体现在两者定位数据的速度上,此时,SSD的性能是要远远好于HDD的。
对于SSD的写操作,针对不同的情况,有不同的处理流程,主要是受到NAND Flash的如下特性限制
- NAND Flash每次写必须以page为单位,且只能写入空闲的page,不能覆盖写原先有内容的page
- 擦除数据时,由于电压较高,只能以block为单位擦除
SSD的写分为新写入和更新两种,处理流程不同。
先看新写入的数据的流程,如下:

假设新写入了一个page,其流程如下:
- 找到一个空闲page
- 把数据写入到空闲page中
- 更新mapping table
而更新操作的流程如下:

假设是更新了page G中的某些字节,流程如下:
- 由于SSD不能覆盖写,因此,先找到一个空闲页H
- 读取page G中的数据到SSD内部的buffer中,把更新的字节更新到buffer
- 把buffer中的数据写入到H
- 更新mapping table中G页,置为无效页
- 更新mapping table中H页,添加映射关系
可以看出,如果在更新操作比较多的情况下,会产生较多的无效页,类似于磁盘碎片,此时,需要SSD的over-provisioning和garbage-collection。
SSD的over-provisioning和garbage-collection
over-provisioning是指SSD实际的存储空间比可写入的空间要大,比如,一块可用容量为120G的SSD,实际空间可能有128G。为什么需要over-provisioning呢?请看如下例子:

如上图所示,假设系统中就两个block,最终还剩下两个无效的page,此时,要写入一个新page,根据NAND原理,必须要先对两个无效的page擦除才能用于写入。此时,就需要用到SSD提供的额外空间,才能用garbage-collection方法整理出可用空间。

garbage collection的整理流程如上图所示
- 首先,从over-provisoning的空间中,找到一个空闲的block
- 把Block0的ABCDEFH和Block1的A复制到空闲block
- 擦除Block 0
- 把Block1的BCDEFH复制到Block0,此时Block0就有两个空闲page了
- 擦除BLock1
有空闲page之后,就可以按照正常的流程来写入了。
SSD的garbage-collection会带来两个问题:
- SSD的寿命减少,NAND Flash中每个原件都有擦写次数限制,超过一定擦写次数后,就只能读取不能写入了
- 写放大问题,即内部真正写入的数据量大于用户请求写入的数据量
如果频繁的在某些block上做garbage-collection,会使得这些元件比其他部分更快到达擦写次数限制,因此,需要某个算法,能使得原件的擦写次数比较平均,这样才能延长SSD的寿命,这就需要下面要讨论的损耗均衡控制了。
SSD损耗均衡控制
为了避免某些block被频繁的更新,而另外一些block非常的空闲,SSD控制器一般会记录各个block的写入次数,并且通过一定的算法,来达到每个block的写入都比较均衡。
以一个例子,说明损耗均衡控制的重要性:
假如一个NAND Flash总共有4096个block,每个block的擦写次数最大为10000。其中有3个文件,每个文件占用50个block,平均10分钟更新1个文件,假设没有均衡控制,那么只会3 * 50 + 50共200个block,则这个SSD的寿命如下:

大约为278天。而如果是完美的损耗均衡控制,即4096个block都均衡地参与更新,则使用寿命如下:

大约5689天。因此,设计一个好的损耗均衡控制算法是非常有必要的,主流的方法主要有两种:
- dynamic wear leveling
- static wear leveling
这里的dynamic和static是指的是数据的特性,如果数据频繁的更新,那么数据是dynamic的,如果数据写入后,不更新,那么是static的。
dynamic wear leveling的原理是记录每个block的擦写次数,每次写入数据时,找到被擦除次数最小的空block。
static wear leveling的原理分为两块:
- 每次找到每擦除次数最小的可用block
- 当某个block的擦除次数小于阈值时,会将它与擦写次数较高的block的数据进行交换
以一个例子来说明,两种擦写算法的不同点:
假如SSD中有25%的数据是dynamic的,另外75%的数据是static的。对于dynamic wear leveling方法,每次要找的是擦除了数据的block,而static的block里面是有数据的,因此,每次都只会在dynamic的block中,即最多会在25%的block中做均衡;对于static算法,每次找的block既可能是dynamic的,也可能是static的,因此,最多有可能在全部的block中做均衡。
相对而言,static算法能使得SSD的寿命更长,但也有其缺点:
- 算法逻辑更复杂
- 在写入时,可能会移动数据,导致写放大,降低写入性能
- 更高的能耗
SSD写放大
最后,我们分析一下SSD的写放大问题,一般由如下三个方面引起:
- SSD读写是以page为单位的,如果更新page中的部分数据,也需要写整个page
- SSD的garbage collection中,会在block间移动数据
- SSD的wear leveing中,可能也会在block间交换数据,导致写放大
通常的,需要在其他方面和SSD的写放大之间做权衡,例如,可以减少garbage collection的频率来减少写放大问题;可以把SSD分成多个zone,每个zone使用不同的wear leveling方法等等。
总结
个人理解,使用SSD时,我们需要考虑如下情况:
- 需要充分利用其随机读写快的特性
- 尽可能在软件层面更新小块数据,减轻SSD写放大问题
- 避免频繁的更新数据,减轻SSD写放大及寿命减少的问题,尽可能使用追加的方式写数据
PS:
本博客更新会在第一时间推送到微信公众号,欢迎大家关注。
















 395
395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









