







一、概述
本研究提出了一个新的视角——通道维度傅里叶变换,用于图像增强,包括三个直接的步骤:(本文重点)
1、对通道维度应用傅里叶变换,获得通道级别的傅里叶域特征。
2、对幅度和相位分量执行通道级别的转换。
3、将结果转换回空间域。
论文还提供了三种不同的通道变换实施方案(以适应不同的图像增强任务),这些方案在不同的操作空间中执行:
1、在全局向量中执行高阶操作。
2、在全局向量中按通道组执行操作。
3、使用基于空间傅里叶变换得到的傅里叶特征。
二、背景介绍
基于深度学习的方法在图像增强方面取得了显着进步,并在建模亮度和对比度调整过程中显示出强大的能力。以往的一系列工作定制了退化先验感知范例,以明确地学习亮度分量,例如曲线调整(Guo等人,2020)和基于Retinex理论的方法(Wei等人,2018年)。这些研究通常将学习过程分为全局和局部组件,并且可能无法完全捕获特征空间内的依赖关系。此外,另一条研究线集中于粗略地设计复杂网络以隐式地学习亮度和对比度增强过程(Xu等人,2022年)。然而,这些方法没有深入探索图像增强的潜在机制或引入用于处理全局分量的专用操作,从而限制了它们有效学习亮度和对比度调整的能力。
1. 现有方法的不足:尽管当前的一些图像增强技术已经取得了一定的进展,但它们并没有深入探究图像增强的底层机制。
2. 底层机制:图像增强的底层机制涉及对图像的全局和局部特征的理解,包括但不限于图像的亮度、对比度、颜色分布、纹理等。
3. 全局组件的处理:有效的图像增强需要对图像的全局信息(如整体亮度和对比度)进行专门的操作和调整。然而,现有方法并没有引入专门针对这些全局组件的操作。
4. 学习亮度和对比度调整:由于缺乏对全局信息的深入处理,现有方法在学习如何有效调整图像的亮度和对比度方面受到了限制。
5. 效果限制:这种对全局信息处理的不足限制了模型的性能,可能无法达到最佳的图像增强效果。
三、相关知识
3.1 傅里叶变换
傅立叶变换广泛用于分析图像的频率表示。通常,这个操作是在每个单独通道的空间维度上独立进行的。给定一个图像![]() ,其中 H、W和 C分别代表图像的高度、宽度和通道数,傅立叶变换
,其中 H、W和 C分别代表图像的高度、宽度和通道数,傅立叶变换![]() 将其转换到傅立叶空间,获得复数成分F(x)。这个过程可以用以下公式表示:
将其转换到傅立叶空间,获得复数成分F(x)。这个过程可以用以下公式表示:
对于每个通道 C,其中 c ∈{1, 2, …, C},我们首先定义一个二维傅立叶变换![]() ,针对该通道的空间维度 (H, W),有
,针对该通道的空间维度 (H, W),有
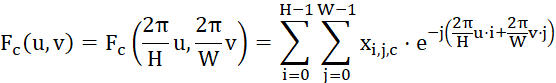
其中, (u, v)是傅立叶空间中的频率坐标,e是自然对数的底数,j是虚数单位。
上述公式中,![]() 表示通道C在频率域中的表示,它是通过对空间域中的每个像素点
表示通道C在频率域中的表示,它是通过对空间域中的每个像素点加权求和得到的,权重由e的指数函数决定,指数函数的参数由空间坐标(i, j)和频率坐标(u, v)确定。
得到每个通道的傅立叶变换后,我们可以将这些变换组合起来,形成完整的傅立叶空间表示 F(x)。这个表示包含了图像的所有通道信息,并且每个通道都转换到了频率域。在这个空间中,我们可以进行各种操作,例如滤波、特征提取、变换等,以便进行进一步的图像分析和处理。
在傅立叶空间中进行操作后,如果需要将图像转换回空间域,我们可以应用逆傅立叶变换![]() 。对于每个通道 c ,逆变换可以表示为:
。对于每个通道 c ,逆变换可以表示为:
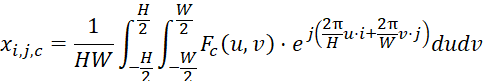
通过这种方式,傅立叶变换为我们提供了一种强大的工具,用于分析和处理图像的频率内容,这在许多图像处理和计算机视觉任务中都是非常有用的。
3.2 快速傅里叶变换及其逆变换(FFT/IFFT)
在论文中提到的傅里叶变换及其逆过程可以通过快速傅里叶变换(Fast Fourier Transform, FFT)和快速逆傅里叶变换(Inverse Fast Fourier Transform, IFFT)算法高效实现。这些算法是由Frigo和Johnson在1998年提出的,它们能够快速计算离散傅里叶变换及其逆过程,广泛应用于信号处理和图像处理等领域。
傅里叶变换将信号从时域(或空间域)转换到频域,而逆傅里叶变换则将信号从频域转换回时域(或空间域)。在图像处理中,傅里叶变换可以用来分析图像的频率成分,这对于图像增强、滤波、压缩等任务非常重要。
傅里叶变换的结果包含幅度成分(Amplitude Component)和相位成分(Phase Component),它们分别表示为:
- 幅度成分 A(x)(u, v):这是复数频率分量的模(magnitude),表示为图像在频率 (u, v) 处的强度。幅度成分是频率域中每个频率点的重要性指标,可以用来分析图像中的频率分布。
- 相位成分 P(x)(u, v):这是复数频率分量的相位角(phase angle),表示为图像在频率 (u, v) 处的波形相对于参考波形的偏移。相位成分包含了图像中的结构信息,对于图像的空间布局和特征形状非常重要。
具体的数学表达式为:
![]()
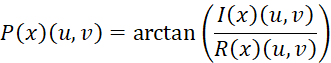
其中,R(x)(u, v)和I(x)(u, v)分别代表复数频率分量的实部(Real Part)和虚部(Imaginary Part)。
通过对图像进行傅里叶变换并操作其幅度和相位成分,可以对图像进行各种滤波和增强操作。例如,通过调整幅度成分可以实现图像的对比度增强,而保持相位成分不变可以确保图像的结构信息不被破坏。这种操作在图像处理中非常有用,尤其是在需要保留图像细节的同时进行全局调整时。
3.3 全局信息的主要特征
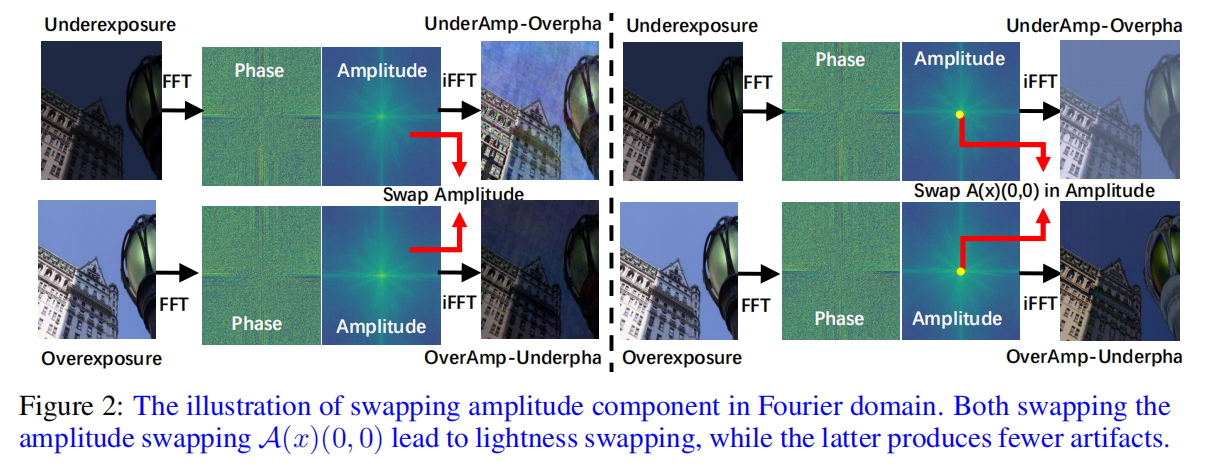
先前的工作已经证明,诸如亮度的全局信息主要保留在幅度分量中(Li等人,2023年)。然而,作者认为全局信息的主要特征在A(x)(0,0)中保持保守。图2 在论文中展示了在傅里叶域中交换幅度分量对于图像全局亮度调整的影响。
这个实验通过以下步骤来揭示傅里叶域中不同操作对图像亮度调整的影响:
(a) 交换幅度导致全局亮度的交换,但交换结果包含许多伪影(artifacts)。
(b) 交换 A(x)(0,0) 在幅度中也导致全局亮度的交换,但交换结果包含较少的伪影。
1.傅里叶变换:图像首先通过傅里叶变换被转换到频率域。在这个域中,图像的每个频率成分都被表示为一个复数,包含幅度(Amplitude)和相位(Phase)信息。
2.幅度分量:幅度分量是频率域中每个频率点的强度指标,它反映了图像中该频率成分的重要性。在图像增强任务中,全局亮度通常与低频分量有关,而低频分量的幅度分量尤其重要。
3.交换操作:在实验中,研究者通过交换幅度分量来模拟亮度调整。具体来说,就是将一幅图像的幅度分量与另一幅图像的幅度分量进行交换。这种操作可以改变图像的全局亮度,但可能会导致伪影的产生。
4.伪影(Artifacts):当直接在幅度分量上进行操作时,可能会引入不自然的亮度变化或噪声,这些不期望的变化被称为伪影。在图像增强中,我们希望避免这些伪影,以保持图像的自然性和真实感。
5.特定点的操作:在 (b) 中,通过仅交换全局平均幅度 A(x)(0,0),可以更精确地控制全局亮度的调整,同时减少伪影的产生。这是因为 A(x)(0,0) 包含了图像的全局信息,而不影响局部细节。
总结来说,Figure 2 展示了在傅里叶域中对幅度分量进行操作时,如何影响图像的全局亮度以及操作可能导致的伪影问题。通过精细地控制这些操作,可以更有效地进行图像增强,尤其是在调整图像亮度时。论文中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









