







聚合(aggregate)主要用于计算数据,类似sql中的sum(),avg()。
db.集合名称.aggregate({管道:{表达式}})
管道
- 管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的输入
- 在mongodb中,管道具有同样的作用,文档处理完毕后,通过管道进行下一次处理
- 常用管道
- $group:将集合中的文档分组,可用于统计结果
- $match:过滤数据,只输出符合条件的文档
- $project:修改输入文档的结构,如重命名、增加、删除字段、创建计算结果
- $sort:将输入文档排序后输出
- $limit:限制聚合管道返回的文档数
- $skip:跳过指定数量的文档,并返回余下的文档
- $unwind:将数组类型的字段进行拆分
表达式
处理输入文档并输出
表达式:'$列名'常用的表达式
- $sum:计算总和
- $avg:计算平均值
- $min:获取最小值
- $max:获取最大值
- $push:在结果文档中插入值到一个数组中
- $first:根据资源文档的排序获取第一个文档数据
- $last:根据资源文档的排序获取最后一个文档数据
$group
将集合中的文档分组,可用于统计结果
_id表示分组的依据,使用某个字段的格式为’$字段’
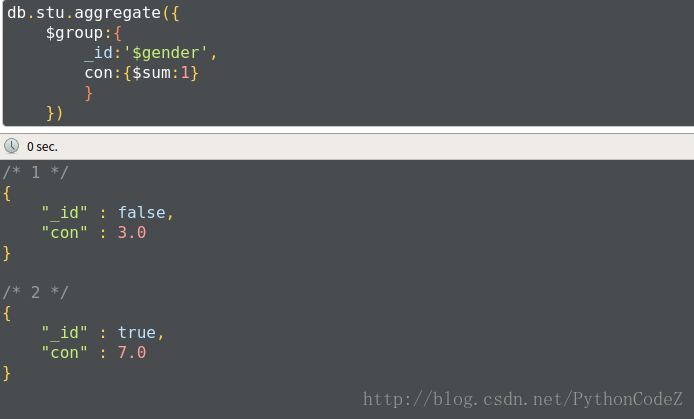
例1:统计男生、女生的总人数
db.stu.aggregate({ $group:{ _id:'$gender', con:{$sum:1} } })group by null:将集合中所有文档分为一组
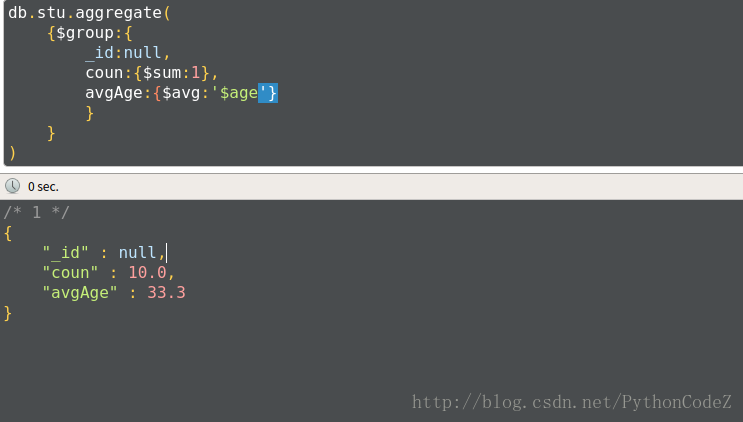
例2:求学生总数和平均年龄
db.stu.aggregate( {$group:{ _id:null, coun:{$sum:1}, avgAge:{$avg:'$age'} } } )透视数据
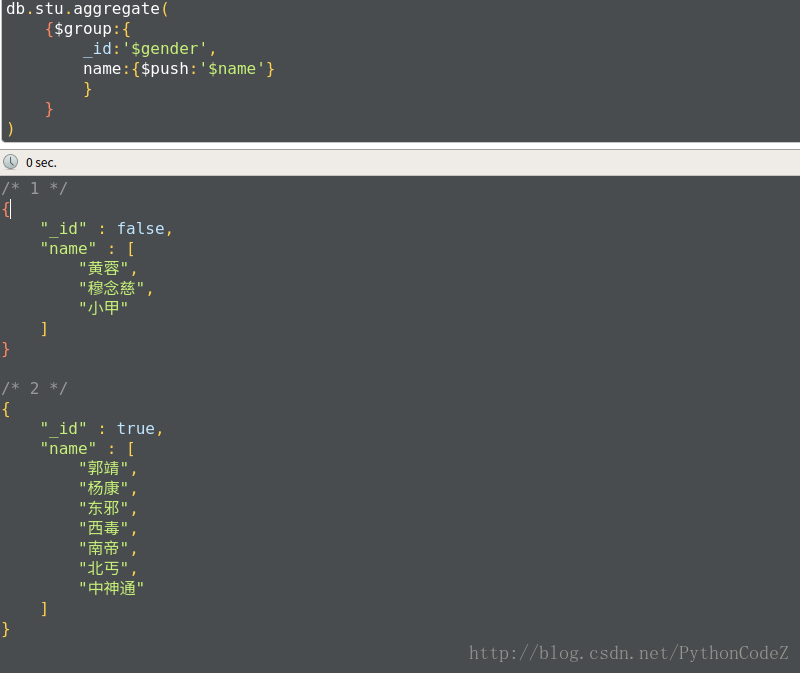
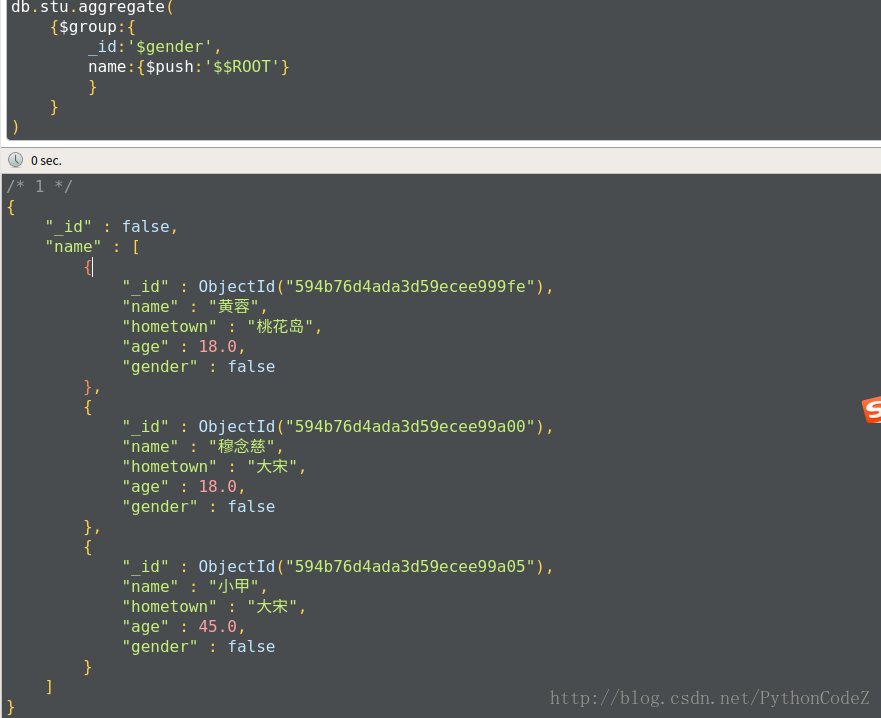
// 统计学生性别以及学生的姓名 db.stu.aggregate( {$group:{ _id:'$gender', name:{$push:'$name'} } } )使用$$ROOT可以将文档内容加入到结果集的数组中
db.stu.aggregate( {$group:{ _id:'$gender', name:{$push:'$$ROOT'} } } )$match
用于过滤数据,只输出符合条件的文档
例子
// 查询年龄大于20的男生、女生人数 db.stu.aggregate( {$match:{age:{$gt:20}}}, {$group:{_id:'$gender',con:{$sum:1}}} )

$project
修改输入文档的结构,如重命名、增加、删除字段、创建计算结果
例子
// 查询男生、女生人数,输出人数 db.stu.aggregate( {$group:{_id:'$gender',counter:{$sum:1}}}, {$project:{_id:0,counter:1}} )

$sort
将输入的文档排序之后输出
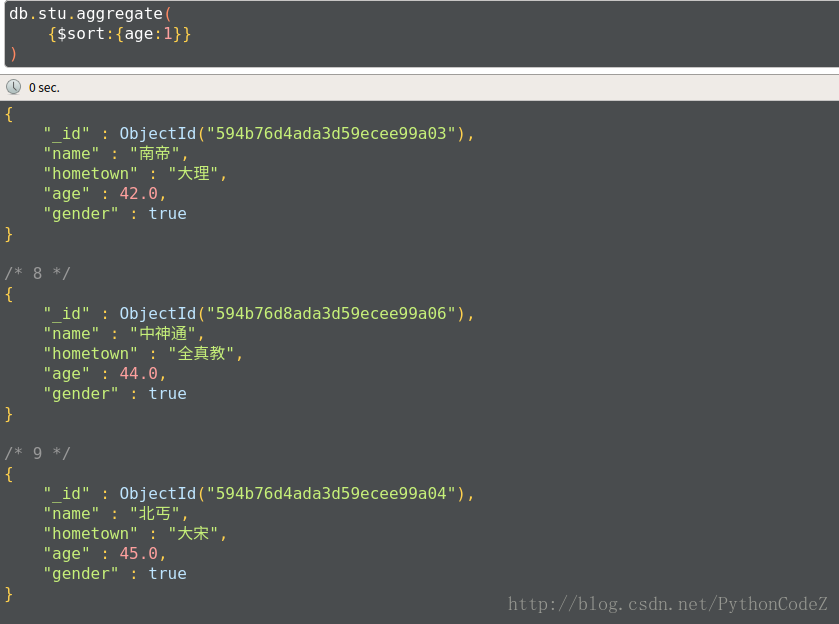
例1:查询学生信息,按年龄升序
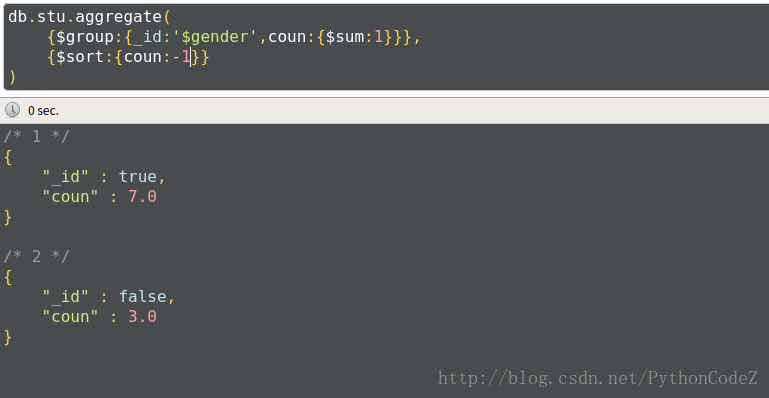
db.stu.aggregate( {$sort:{age:1}} )例2:查询男生、女生人数,按人数降序
db.stu.aggregate( {$group:{_id:'$gender',coun:{$sum:1}}}, {$sort:{coun:-1}} )
$limit
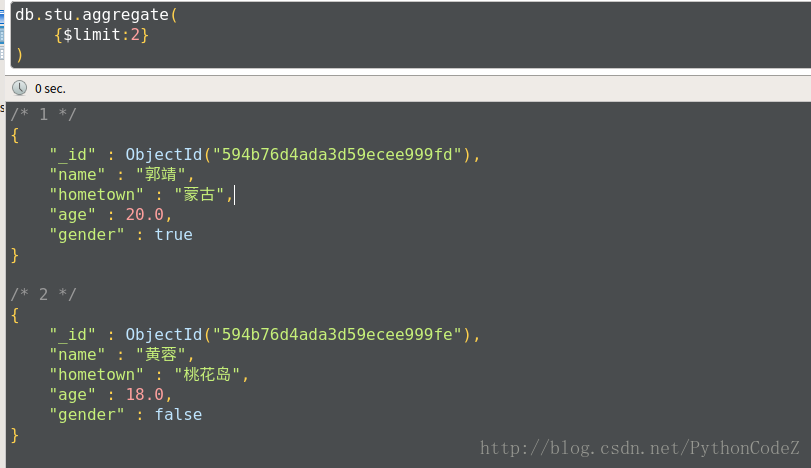
限制聚合管道返回的文档数
// 查询两个学生的信息 db.stu.aggregate( {$limit:2} )
$skip
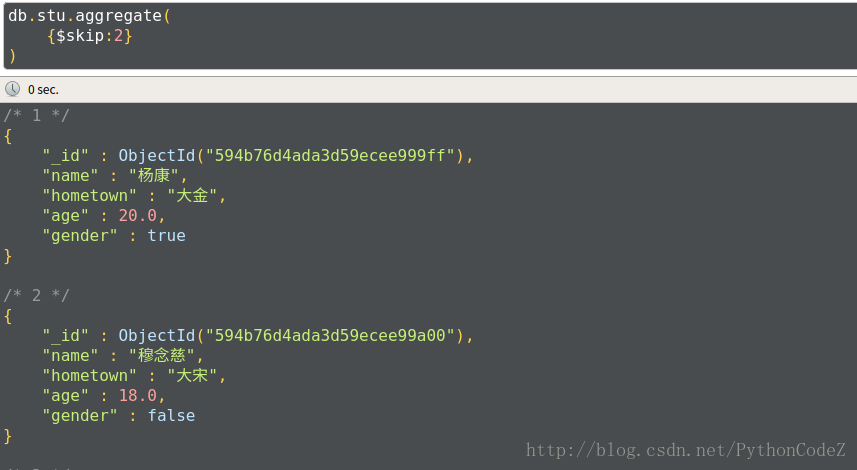
跳过指定的数量的文档,并返回余下的文档
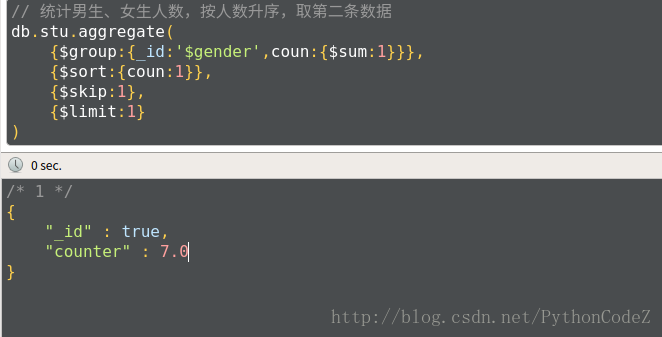
// 查询第三条开始的学生的信息 db.stu.aggregate( {$skip:2} )$limit和$skip一起使用// 统计男生、女生人数,按人数升序,取第二条数据 db.stu.aggregate( {$group:{_id:'$gender',coun:{$sum:1}}}, {$sort:{coun:1}}, {$skip:1}, {$limit:1} )
$unwind
将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值
语法1:
对某字段值进行拆分
db.集合名称.aggregate({$unwind:'$字段名称'})准备数据:
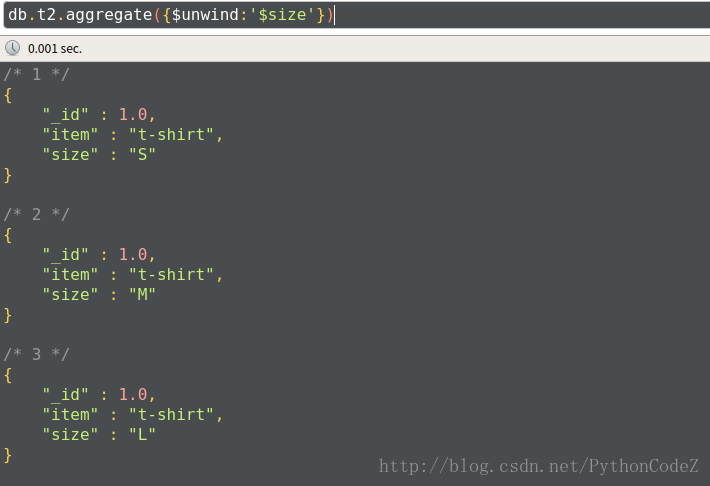
db.t2.insert({_id:1,item:'t-shirt',size:['S','M','L']})查询
db.t2.aggregate({$unwind:'$size'})
语法2:
- 对某字段值进行拆分
- 处理空数组、非数组、无字段、null情况
- 属性preserveNullAndEmptyArrays值为false表示丢弃属性值为空的文档
- 属性preserveNullAndEmptyArrays值为true表示保留属性值为空的文档
db.inventory.aggregate({ $unwind:{ path:'$字段名称', preserveNullAndEmptyArrays:<boolean> #防止数据丢失 } })构造数据
db.t3.insert([ { "_id" : 1, "item" : "a", "size": [ "S", "M", "L"] }, { "_id" : 2, "item" : "b", "size" : [ ] }, { "_id" : 3, "item" : "c", "size": "M" }, { "_id" : 4, "item" : "d" }, { "_id" : 5, "item" : "e", "size" : null } ])
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









