






selenium概述
Selenium是一种用于自动化 Web 应用程序测试的开源框架。它支持跨多个浏览器和操作系统的测试,能够模拟用户与 Web 页面上的各种交互,如点击按钮、填写表单和导航链接。
Selenium提供了多个组件:
-
Selenium WebDriver:最常用的组件,通过调用浏览器的原生的支持,执行用户操作模拟,支持多种编程语言,如Java、Python、C#等
-
Selenium IDE:集成开发环境,它是一种记录和回放工具,可以在浏览器中录制用户操作,并生成相应的测试脚本。
-
Selenium Grid:用于并行测试,允许在分布式环境中同时运行多个测试。通常用于跨浏览器、跨平台测试,以提高测试效率。
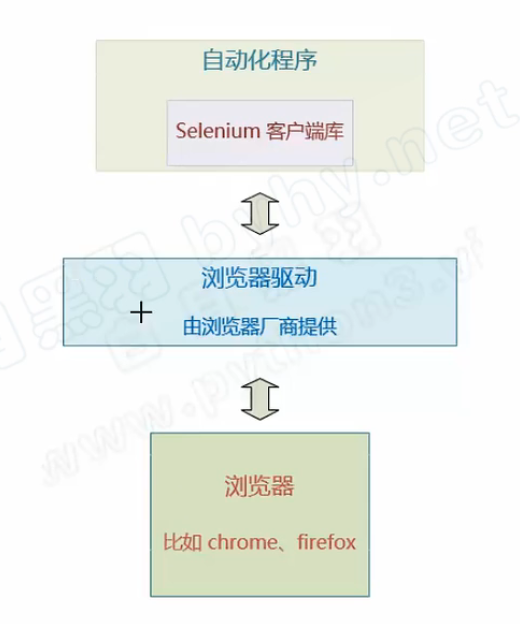
环境准备
Selenium提供了一系列客户端库,自动化程序通过调用Selenium库函数接口发送操作指令给浏览器驱动Driver,浏览器驱动再转发这个请求给浏览器去执行。
安装selenium框架
pip install selenium
安装浏览器驱动(切记版本需要与浏览器版本最好相同)
Chrome for Testing availability (googlechromelabs.github.io)
加载驱动对象WebDriver
打开谷歌浏览器,指定浏览器驱动,返回一个 WebDriver类型 的对象用于操作元素
wd = webdriver.Chrome(service=Service(r"C:\browersDriver\chromedriver.exe"))
我们也可以将浏览器所在文件夹路径放在环境变量PATH当中,就可以无需申明浏览器驱动路劲
wd = webdriver.Chrome()
浏览器运行Selenium
要求下载最新的Chrome和Edge浏览器的驱动,且将驱动的父文件路径添加到环境变量PATH当中
Chrome浏览器运行简单Selenium程序
from selenium import webdriver
# 打开谷歌浏览器,指定浏览器驱动,返回一个 WebDriver类型 的对象用于操作元素
# wd = webdriver.Chrome(service=Service(r"C:\browersDriver\chromedriver.exe"))
wd = webdriver.Chrome()
# 打开指定浏览器网址
wd.get("https://www.byhy.net/_files/stock1.html")
# 调用find_element方法返回ID="kw"元素的 WebElemen类型 的对象对象
element = wd.find_element(By.ID, "kw")
# 调用元素对象的send_keys方法,操作对象输入字符串“通信”进行查询
element.send_keys("通信\n")
# 查找id=“go”的元素并获取WebElement对象,查找“查询”按钮
element = wd.find_element(By.ID, "go")
# 对WebElement对象进行点击操作,点击查询按钮
element.click()
# 退出浏览器驱动
sleep(3)
wd.quit()
Edge浏览器运行Selenium程序
from selenium import webdriver
# 打开谷歌浏览器,指定浏览器驱动,返回一个 WebDriver类型 的对象用于操作元素
# wd = webdriver.Edge(service=Service(r"C:\browersDriver\chromedriver.exe"))
wd = webdriver.Edge()
# 打开指定浏览器网址
wd.get("https://www.byhy.net/_files/stock1.html")
# 调用find_element方法返回ID="kw"元素的 WebElemen类型 的对象对象
element = wd.find_element(By.ID, "kw")
# 调用元素对象的send_keys方法,操作对象输入字符串“通信”进行查询
element.send_keys("通信\n")
# 查找id=“go”的元素并获取WebElement对象,查找“查询”按钮
element = wd.find_element(By.ID, "go")
# 对WebElement对象进行点击操作,点击查询按钮
element.click()
# 退出浏览器驱动
sleep(3)
wd.quit()
元素选择
元素选择方式分为好几种
-
根据ID选择
-
根据Class选择
-
根据标签名tag选择
-
根据CSS选择
wd.find_element(By.ID, 'username').send_keys('byhy')
wd.find_element(By.CLASS_NAME, 'password').send_keys('sdfsdf')
wd.find_element(By.TAG_NAME, 'input').send_keys('sdfsdf')
wd.find_element(By.CSS_SELECTOR,'button[type=submit]').click()
之前的selenium3的方法已经过时,调用WebDriver对象的find_element方法传入By枚举类型,以及元素标识,从而取代过时的方法如下:
wd.find_element_by_id('username').send_keys('byhy')
wd.find_element_by_class_name('password').send_keys('sdfsdf')
wd.find_element_by_tag_name('input').send_keys('sdfsdf')
wd.find_element_by_css_selector('button[type=submit]').click()
调用元素选择方法find_element()的返回一个WebElement类型的对象,WebDriver对象还提供了一个方法find_elements(),该方法返回一个包含WebElement对象的List列表;
-
使用
find_elements选择的是符合条件的所有元素, 如果没有符合条件的元素,返回空列表 -
使用
find_element选择的是符合条件的第一个元素, 如果没有符合条件的元素,抛出 NoSuchElementException 异常
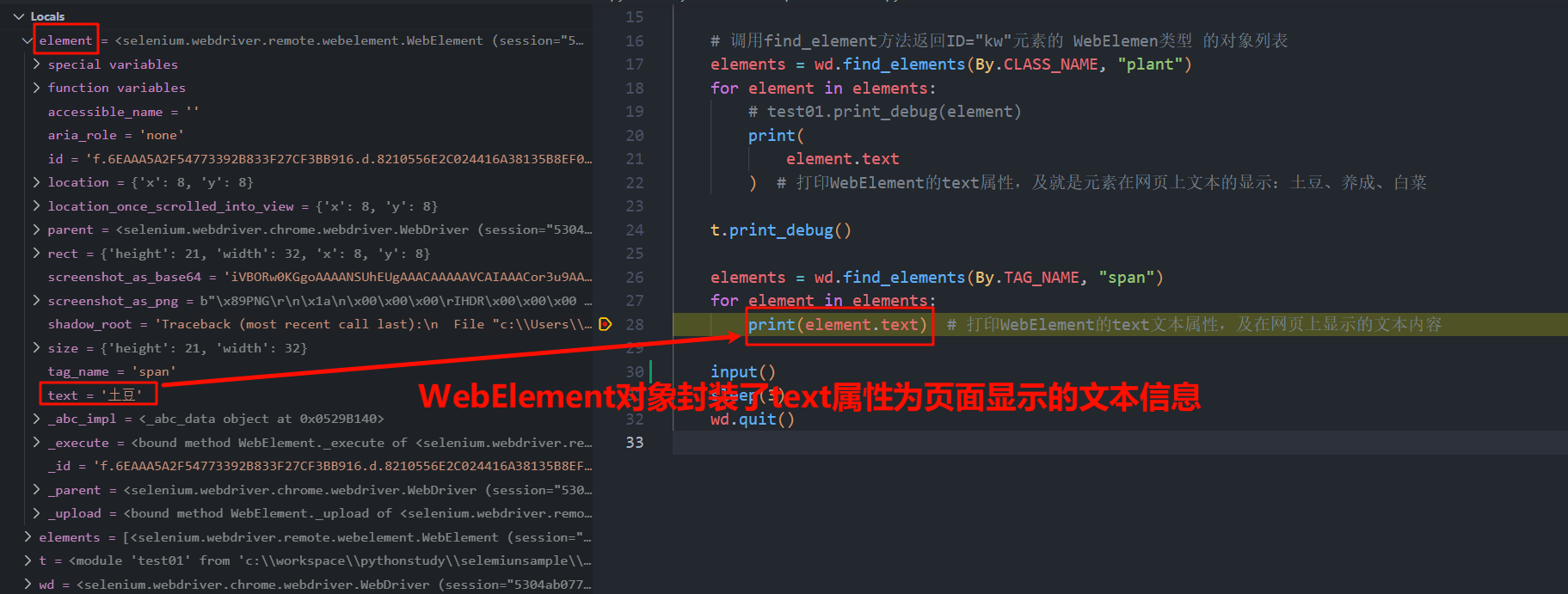
WebElementD对象的text方法,返回网页显示的文本信息
如以下web前端代码
# 打开谷歌浏览器,指定浏览器驱动,返回一个 WebDriver类型 的对象用于操作元素
wd = webdriver.Chrome()
# 打开指定浏览器网址
wd.get("https://cdn2.byhy.net/files/selenium/sample1.html")
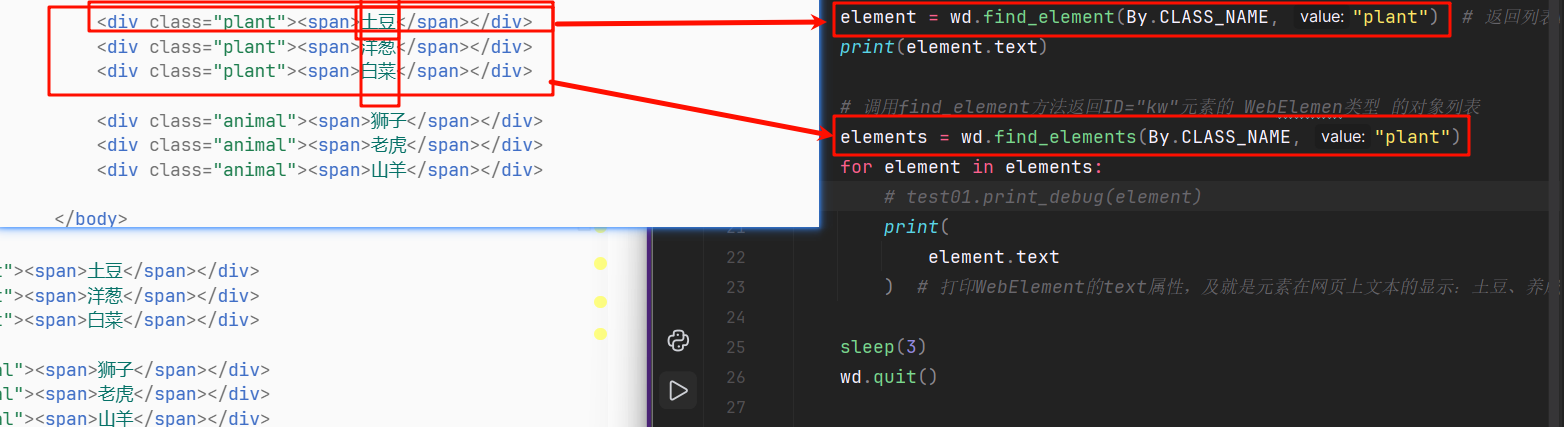
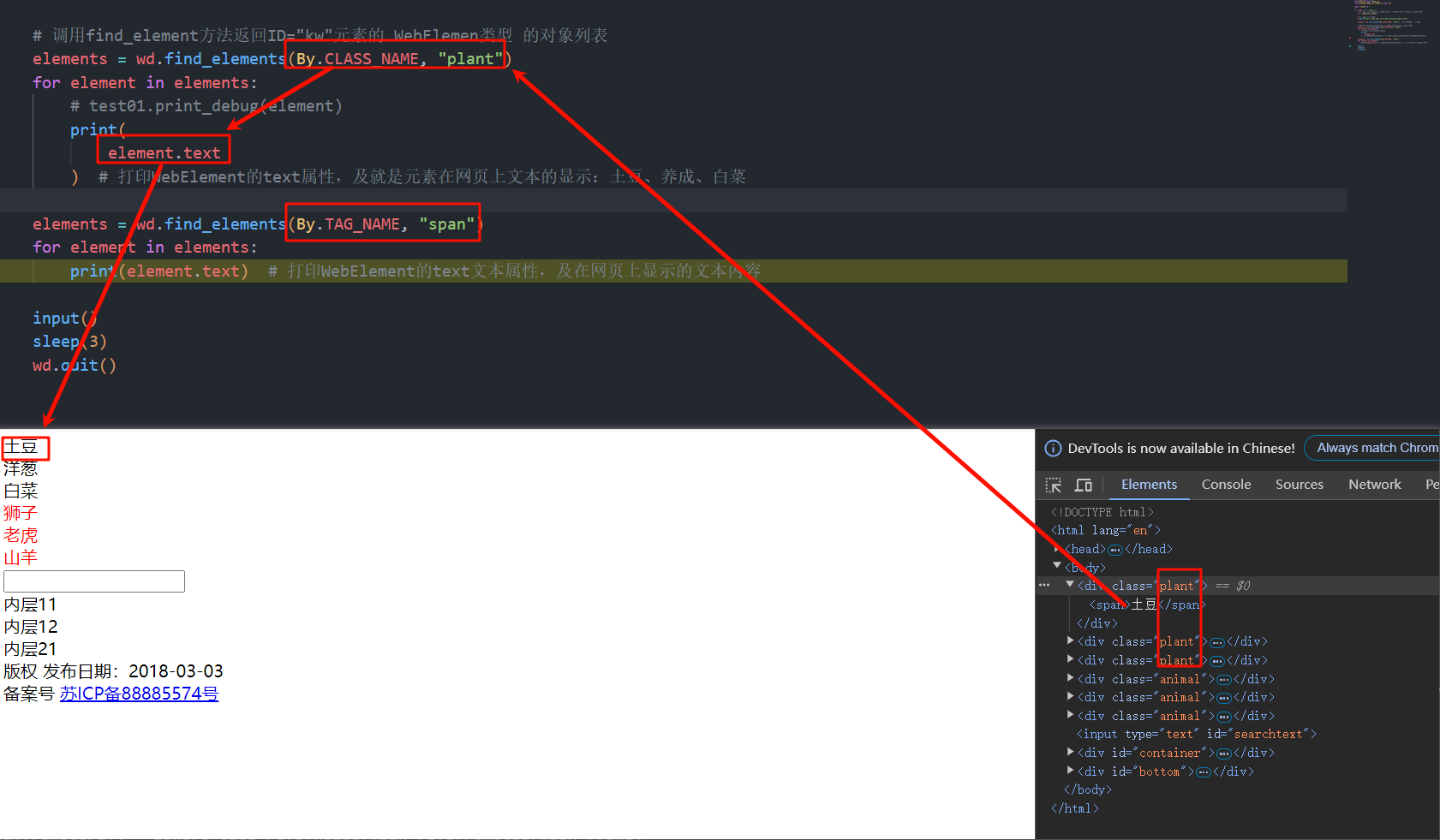
element = wd.find_element(By.CLASS_NAME, "plant") # 返回列表的第一个元素
print(element.text) # 输出WebElement对象的text属性,该属性为网页显示的文本信息
# 调用find_element方法返回ID="kw"元素的 WebElemen类型 的对象列表
elements = wd.find_elements(By.CLASS_NAME, "plant")
for element in elements:
# test01.print_debug(element)
print(
element.text
) # 打印WebElement的text属性,及就是元素在网页上文本的显示:土豆、养成、白菜
对于class类型元素,元素也可以有 多个class类型 ,多个class类型的值之间用 空格 隔开,就像一个 学生张三 可以定义有 多个 类型: 中国人 和 学生 , 中国人 和 学生 都是 张三 的 类型。
<span class="chinese student">张三</span>
我们要用代码选择这个元素,可以指定任意一个class 属性值,都可以选择到这个元素,如下
element = wd.find_elements(By.CLASS_NAME,'chinese') element = wd.find_elements(By.CLASS_NAME,'student')
不仅 WebDriver对象有 选择元素 的方法, WebElement对象 也有选择元素的方法。
WebDriver是整个网页的驱动对象,类似于网页的控制器,而 WebElement对象是其中的一部分元素对象,类似于元素控制器,可以控制该元素范围下的所有元素对象。
if __name__ == "__main__":
# 打开谷歌浏览器,指定浏览器驱动,返回一个 WebDriver类型 的对象用于操作元素
wd = webdriver.Chrome()
# 打开指定 浏览器网址
wd.get("https://cdn2.byhy.net/files/selenium/sample1.html")
# 调用wd对象方法返回整个web页面范围内的指定的element元素
web_elements = wd.find_elements(By.TAG_NAME, "span")
for element in web_elements:
print(element.text) # 打印整个web界面下的tag="span"标签的所有属性
web_element = wd.find_element(By.ID, "container")
# 调用单个element元素的方法返回该元素范围内的指定element元素
tag_elements = web_element.find_elements(By.TAG_NAME, "span")
for element in tag_elements:
print(
element.text
) # 打印id="container"范围内的所有tag="span"标签的所有元素的text文本属性
sleep(3)
wd.quit()
元素等待
在我们进行网页操作的时候, 有的元素内容不是可以立即出现的, 可能会等待一段时间。
当然在等待的时间过程中,由于程序的运行速度是非常快的,有可能会因为程序运行过快还未等界面更新过来而找不到我们想要的元素,从而抛出异常NoSuchElementException
最常见的方法有三个
-
采用sleep函数等待(硬编码不推荐)
-
循环等待元素出现(代码过于冗余)
-
显式等待 -
隐式等待
隐式等待
隐式等待implicitly_wait(secend) 设置全局隐式等待时间,所有的find_element 或者 find_elements 查找元素时都会应用以上策略,其内部就是封装了一个循环等待方法,每隔0.5s请求一次结果,如果超出最大设置时间则抛出异常NoSuchElementException 适用于find相关的函数
wd = webdriver.Chrome() wd.implicitly_wait(5) # 设置最大隐式等待时间为5s
显式等待
显示等待和隐式等待区别:Python-selenium显示等待 - Beyond8 - 博客园 (cnblogs.com)
显示等待需要引入工具包WebDriverWait和expected_conditions
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC
使用案例
# 等待按钮出现并点击
WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, "//*[@id='idSIButton9']"))
).click()
WebDriverWait(driver, 10):
-
driver: 传入的 WebDriver 实例,表示当前浏览器实例。 -
10: 表示最长等待时间为 10 秒。如果在 10 秒内条件没有满足,Selenium 会抛出TimeoutException。
until:
-
until方法会一直等待,直到所传递的条件返回True,或者超时时间到了为止,返回查找到的WebElement对象。
EC.element_to_be_clickable((By.XPATH, "//\*[@id='idSIButton9']")):
-
element_to_be_clickable: 这是一个期望条件,用来判断元素是否可点击。该条件检查两个方面:-
元素是否在 DOM 中存在。
-
元素是否可见并且可点击。
-
通过显示等待可以预防sleep()硬编码等问题,且WebDriverWait提供了更多操作的api,如等待按钮,等待输入框等等
element_to_be_clickable 等待元素可点击(即元素可见且可点击) visibility_of_element_located 等待元素可见(即元素在页面中存在并可见) presence_of_element_located 等待元素存在于 DOM 中,但不一定可见 text_to_be_present_in_element 等待指定文本出现在元素中 text_to_be_present_in_element_value 等待指定文本出现在元素的 value 属性中(例如输入框) frame_to_be_available_and_switch_to_it 等待指定的 iframe 可用并切换到它 invisibility_of_element_located 等待元素在 DOM 中不可见 element_to_be_selected 等待元素被选中(适用于复选框和单选按钮) alert_is_present 等待 JavaScript 弹出警告框出现 number_of_windows_to_be 等待窗口数量达到指定的数量 new_window_is_opened 等待新窗口打开 title_contains 等待标题包含指定的文本 title_is 等待标题等于指定的文本 url_changes 等待 URL 发生变化 url_to_be 等待 URL 等于指定的文本
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
base_url = "http://www.baidu.com"
driver = webdriver.Firefox()
driver.implicitly_wait(5)
'''隐式等待和显示等待都存在时,超时时间取二者中较大的'''
locator = (By.ID,'kw')
driver.get(base_url)
WebDriverWait(driver,10).until(EC.title_is(u"百度一下,你就知道"))
'''判断title,返回布尔值'''
WebDriverWait(driver,10).until(EC.title_contains(u"百度一下"))
'''判断title,返回布尔值'''
WebDriverWait(driver,10).until(EC.presence_of_element_located((By.ID,'kw')))
'''判断某个元素是否被加到了dom树里,并不代表该元素一定可见,如果定位到就返回WebElement'''
WebDriverWait(driver,10).until(EC.visibility_of_element_located((By.ID,'su')))
'''判断某个元素是否被添加到了dom里并且可见,可见代表元素可显示且宽和高都大于0'''
WebDriverWait(driver,10).until(EC.visibility_of(driver.find_element(by=By.ID,value='kw')))
'''判断元素是否可见,如果可见就返回这个元素'''
WebDriverWait(driver,10).until(EC.presence_of_all_elements_located((By.CSS_SELECTOR,'.mnav')))
'''判断是否至少有1个元素存在于dom树中,如果定位到就返回列表'''
WebDriverWait(driver,10).until(EC.visibility_of_any_elements_located((By.CSS_SELECTOR,'.mnav')))
'''判断是否至少有一个元素在页面中可见,如果定位到就返回列表'''
WebDriverWait(driver,10).until(EC.text_to_be_present_in_element((By.XPATH,"//*[@id='u1']/a[8]"),u'设置'))
'''判断指定的元素中是否包含了预期的字符串,返回布尔值'''
WebDriverWait(driver,10).until(EC.text_to_be_present_in_element_value((By.CSS_SELECTOR,'#su'),u'百度一下'))
'''判断指定元素的属性值中是否包含了预期的字符串,返回布尔值'''
#WebDriverWait(driver,10).until(EC.frame_to_be_available_and_switch_to_it(locator))
'''判断该frame是否可以switch进去,如果可以的话,返回True并且switch进去,否则返回False'''
#注意这里并没有一个frame可以切换进去
WebDriverWait(driver,10).until(EC.invisibility_of_element_located((By.CSS_SELECTOR,'#swfEveryCookieWrap')))
'''判断某个元素在是否存在于dom或不可见,如果可见返回False,不可见返回这个元素'''
#注意#swfEveryCookieWrap在此页面中是一个隐藏的元素
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//*[@id='u1']/a[8]"))).click()
'''判断某个元素中是否可见并且是enable的,代表可点击'''
driver.find_element_by_xpath("//*[@id='wrapper']/div[6]/a[1]").click()
#WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//*[@id='wrapper']/div[6]/a[1]"))).click()
#WebDriverWait(driver,10).until(EC.staleness_of(driver.find_element(By.ID,'su')))
'''等待某个元素从dom树中移除'''
#这里没有找到合适的例子
WebDriverWait(driver,10).until(EC.element_to_be_selected(driver.find_element(By.XPATH,"//*[@id='nr']/option[1]")))
'''判断某个元素是否被选中了,一般用在下拉列表'''
WebDriverWait(driver,10).until(EC.element_selection_state_to_be(driver.find_element(By.XPATH,"//*[@id='nr']/option[1]"),True))
'''判断某个元素的选中状态是否符合预期'''
WebDriverWait(driver,10).until(EC.element_located_selection_state_to_be((By.XPATH,"//*[@id='nr']/option[1]"),True))
'''判断某个元素的选中状态是否符合预期'''
driver.find_element_by_xpath(".//*[@id='gxszButton']/a[1]").click()
instance = WebDriverWait(driver,10).until(EC.alert_is_present())
'''判断页面上是否存在alert,如果有就切换到alert并返回alert的内容'''
print instance.text
instance.accept()
driver.close()
selenium.webdriver.support.wait.WebDriverWait(类)
__init__
driver: 传入WebDriver实例,即我们上例中的driver
timeout: 超时时间,等待的最长时间(同时要考虑隐性等待时间)
poll_frequency: 调用until或until_not中的方法的间隔时间,默认是0.5秒
ignored_exceptions: 忽略的异常,如果在调用until或until_not的过程中抛出这个元组中的异常,
则不中断代码,继续等待,如果抛出的是这个元组外的异常,则中断代码,抛出异常。默认只有NoSuchElementException。
until
method: 在等待期间,每隔一段时间调用这个传入的方法,直到返回值不是False
message: 如果超时,抛出TimeoutException,将message传入异常
until_not 与until相反,until是当某元素出现或什么条件成立则继续执行,
until_not是当某元素消失或什么条件不成立则继续执行,参数也相同,不再赘述。
method
message
-
显示等待:主要正对某个元素,在规定时间内,可见、可点击、等等,超出时间则抛出异常 -
隐士等待:主要正对整个页面,在规定时间内,整个页面加载完成,才执行下一步,超出时间则抛出异常 -
显示等待和隐士等待同时存在时,看
谁的时间长,就取谁的等待时间
元素控制
选择到元素之后,我们的代码会返回元素对应的 WebElement对象,通过这个对象,我们就可以 操控 元素了。
操控元素通常包括
-
点击元素
-
在元素中输入字符串,通常是对输入框这样的元素
-
获取元素包含的信息,比如文本内容,元素的属性
按钮元素操作
点击元素 非常简单,就是调用元素WebElement对象的 click方法。前面我们已经学过。
这里我们要补充讲解一点。
当我们调用 WebElement 对象的 click 方法去点击 元素的时候, 浏览器接收到自动化命令,点击的是该元素的 中心点 位置 。
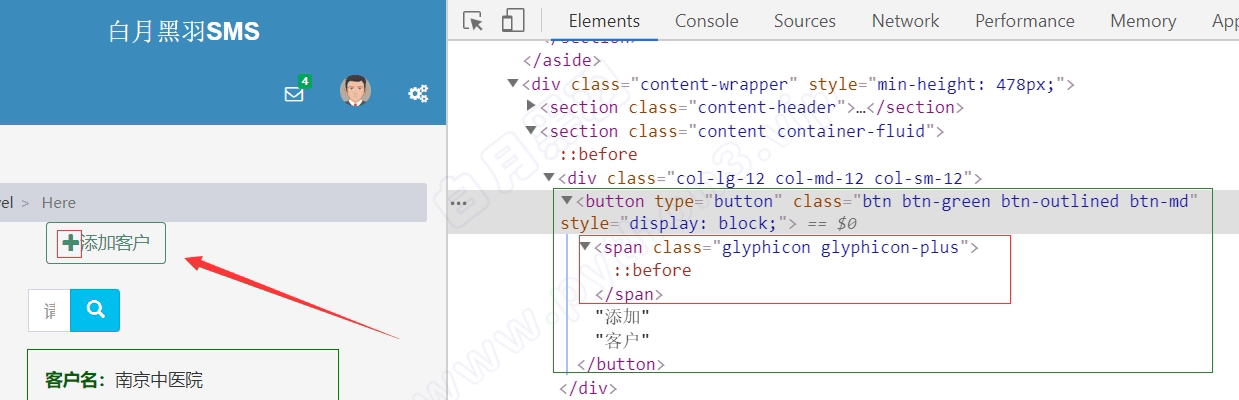
点击按钮
wd = webdriver.Chrome()
# 打开指定浏览器网址
wd.get("https://www.byhy.net/_files/stock1.html")
# 调用find_element方法返回ID="kw"元素的 WebElemen类型 的对象对象
element = wd.find_element(By.ID, "kw")
# 调用元素对象的send_keys方法,操作对象输入字符串“通信”进行查询
element.send_keys("通信")
# 查找id=“go”的元素并获取WebElement对象,查找“查询”按钮
element = wd.find_element(By.ID, "go")
# 对WebElement对象进行点击操作,点击查询按钮
element.click()
输入框元素操作
-
输入字符串
element.send_keys("通信") -
清空输入框
element.clear()
输入字符串 也非常简单,就是调用元素WebElement对象的send_keys方法。前面我们也已经学过。
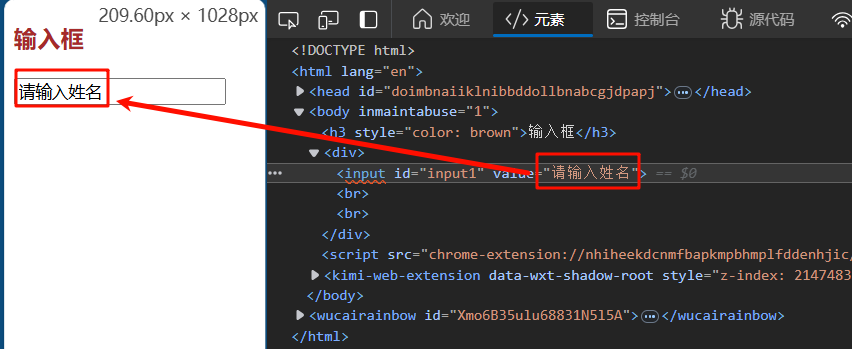
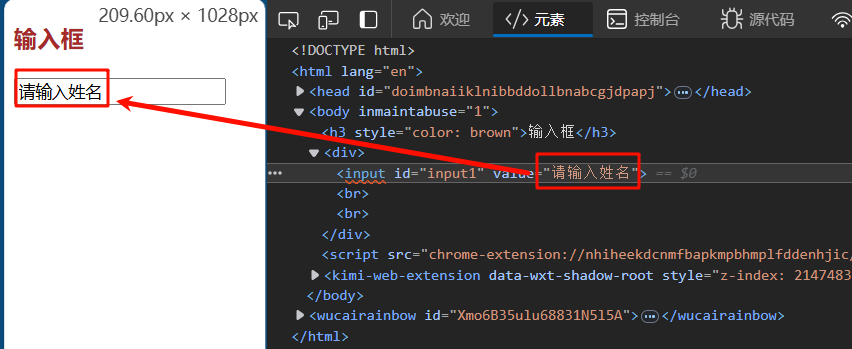
我们如何获取输入框内的文本信息呢,不是text属性,而是输入框元素的value属性,text和value区别如下:
-
text为WebElement对象的属性,为文本元素在界面上展示的内容,使用
webElement.text获取 -
-
-
value为前端输入框元素的属性,如前端代码
<input id="input1"value="请输入姓名">,因此我们可以用element.get_attribute("value")获取input输入款的value属性值 -
wd = webdriver.Chrome()
# 打开指定浏览器网址
wd.get("https://www.byhy.net/_files/stock1.html")
# 调用find_element方法返回ID="kw"元素的 WebElemen类型 的对象对象
element = wd.find_element(By.ID, "kw")
# 调用元素对象的send_keys方法,操作对象输入字符串“通信”进行查询
element.clear() # 清除输入框已有的字符串
element.send_keys("通信")
print(element.get_attribute("value")) # 打印文本 输出“通信”
print(element.text) # 打印text属性 输出为None
获取元素信息
通过text和value的区别,涉及到我们如何获取元素的基本属性
首先通过WebElement对象的 text 属性,可以获取元素 展示在界面上的 文本内容。且text属性是selenium框架自动封装好WebElement对象的text属性
获取元素属性
我们通过WebElement对象的 get_attribute 方法来获取元素的属性值。比如说我们去获取输入框内的文本信息value
比如要获取元素属性class的值,就可以使用 element.get_attribute('class')
element = wd.find_element(By.ID, 'input_name')
print(element.get_attribute('class'))
获取元素HTML源码
要获取整个元素对应的HTML文本内容,可以使用 element.get_attribute('outerHTML')
如果,只是想获取某个元素 内部 的HTML文本内容,可以使用 element.get_attribute('innerHTML')
# 3. get_attribute("outerHTML") 用于获取符合条件的整个前端html源码
element = wd.find_element(By.ID, "1")
print(element.get_attribute("outerHTML"))
# <div class="result-item" id="1">
# <p class="name">包钢股份</p>
# <p>代码:<span>600010</span></p>
# </div>
# 4. get_attribute("innerHTML") 用于获取符合条件的内部的html源码
element = wd.find_element(By.ID, "1")
print(element.get_attribute("innerHTML"))
# <p class="name">包钢股份</p>
# <p>代码:<span>600010</span></p>
获取元素文本信息
通过WebElement对象的 text 属性,可以获取元素 展示在界面上的 文本内容。
有时候,元素的文本内容没有展示在界面上,或者没有完全完全展示在界面上。 这时,用WebElement对象的text属性,获取文本内容,就会有问题。出现这种情况,可以尝试使用 element.get_attribute('innerText') ,或者 element.get_attribute('textContent')
本质上一下三种方法打印的内容没有什么区别,只不过innerText,textContent可以打印一些隐藏在界面上的文本信息
text = element.text
innerText = element.get_attribute('innerText')
textContent = element.get_attribute('textContent')
text与innerText的区别:两者都输出前端页面可见的文本信息,text返回的是用户更友好的文本,而textContent会显示换行符空格等,以及一些受CSS样式影响的文本
使用 innerText 和 textContent 的区别是,前者只显示元素可见文本内容,后者显示所有内容(包括display属性为none的部分)
CSS表达式
父子元素和后代元素
若两个元素为相邻的上下层级的包含关系,那么外层元素为父元素,内层元素为(直接)子元素
如果其中一个元素被另一个元素包含在内但不一定是相邻包含,则被包含的元素为后代元素,且子元素为特殊的后代元素
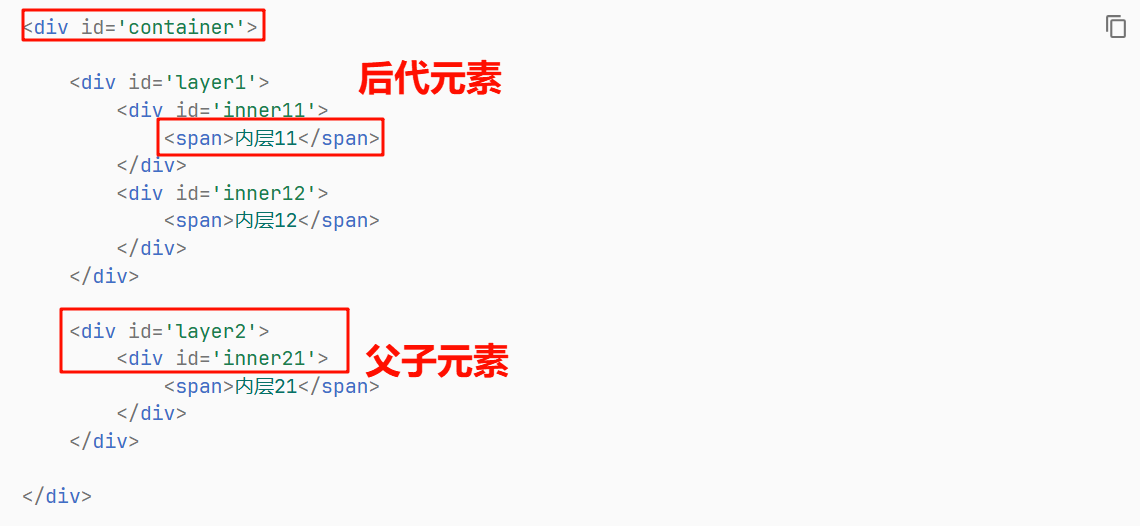
CSS选择器当中,父子元素采用 > 表示,父元素 > 子元素,同时也支持更多层级的嵌套选择,如:元素1 > 元素2 > 元素3 > 元素4,表示选择 元素1 里面的子元素 元素2 里面的子元素 元素3 里面的子元素 元素4 , 最终选择的元素是 元素4
后代元素采用空格表示,如 父元素 后代元素 ,中间是一个或者多个空格隔开,最终选择的元素是 元素2 , 并且要求这个 元素2 是 元素1 的后代元素。
CSS选择器选择元素
前面我们学到了可以根据id、class等属性选择元素。CSS Selector 同样可以根据tag名、id 属性和 class属性来选择元素,使用更加灵活,格式如下:
find_element(By.CSS_SELECTOR, CSS Selector参数)
通过id选择元素
element = wd.find_element(By.CSS_SELECTOR, '#searchtext') # 通过CSS选择器选择元素 element = wd.find_element(By.ID, 'searchtext') # 通过ID选择元素
通过class选择元素
elements = wd.find_elements(By.CSS_SELECTOR, '.animal') # 通过CSS选择器选择元素 elements = wd.find_elements(By.CLASS_NAME, 'animal') # 通过class_name选择元素
通过属性选择元素,如属性:<a href="http://www.miitbeian.gov.cn">苏ICP备88885574号</a>
element = wd.find_element(By.CSS_SELECTOR, '[href="http://www.miitbeian.gov.cn"]') element = wd.find_element(By.CSS_SELECTOR, '[href]') # 也可以不带属性值,带属性值定位更精确 # 带属性值的通配符 a[href*="miitbeian"] # href属性值包含miitbeian,且标签为a的元素 a[href^="http"] # href属性值以http开头,且标签为a的元素 a[href$="gov.cn"] # href属性值以gov.cn结尾,且标签为a的元素
如果一个元素具有多个属性,我们还可以指定选择的元素要同时具有多个属性的限制
如:<div class="misc" ctype="gun">沙漠之鹰</div> div[class=misc][ctype=gun] # 表示该元素需要满足class=misc,且ctype=gun
限定标签
css选择器直接书写表示标签名字,采用.class_name表示class属性,#id_name表示id属性。[]表示其他属性,
*div.footer1 > span.copyright* 表示div标签的class为footer1下的子元素为span标签的class为copyright的元素 *div#footer1* 表示div标签中id为#footer1的元素 *div[href]* 表示div标签中含有href属性的元素 *div #footer1* 表示div的后代元素中含有id为footer1的元素 *div > #footer1* 表示div元素下的直接子元素id为#footer1的元素
逻辑选择
css选择器当中的逻辑与选择,包括多重嵌套选择、与选择
div[class=misc][ctype=gun] # 表示该元素需要满足class=misc,且ctype=gun div.example # div标签下的class=example的元素 div > .example # div下的直接子元素class=example的元素
逻辑或,采用,隔开多种条件
.plant , .animal # 表示同时选择所有class为plant和class为animal的元素 div,#BYHY # 同时选择所有tag名为div的元素 和 id为BYHY的元素
这里要注意,,优先级较低,我们需要区分选择
如选择所有 id 为 t1 里面的 span 和 p 元素
#t1 > span,p
它表示查找id为t1下的span和所有的p标签,为了选择所有 id 为 t1 里面的 span 和 p 元素,应该使用如下语法
#t1 > span,#t1 > p
次序选择
:nth-child(num)表示同级第num个元素
父元素 :nth-child(num) 表示父元素下的第num个子元素
元素:nth-child(num) 表示第num个元素且满足元素条件的元素
:nth-last-child(num) 表示倒数多少位同级元素
<body>
<div id='t1'>
<h3> 唐诗 </h3>
<span>李白</span>
<p>静夜思</p>
<span>杜甫</span>
<p>春夜喜雨</p>
</div>
<div id='t2'>
<h3> 宋词 </h3>
<span>苏轼</span>
<p>赤壁怀古</p>
<p>明月几时有</p>
<p>江城子·乙卯正月二十日夜记梦</p>
<p>蝶恋花·春景</p>
<span>辛弃疾</span>
<p>京口北固亭怀古</p>
<p>青玉案·元夕</p>
<p>西江月·夜行黄沙道中</p>
</div>
</body>
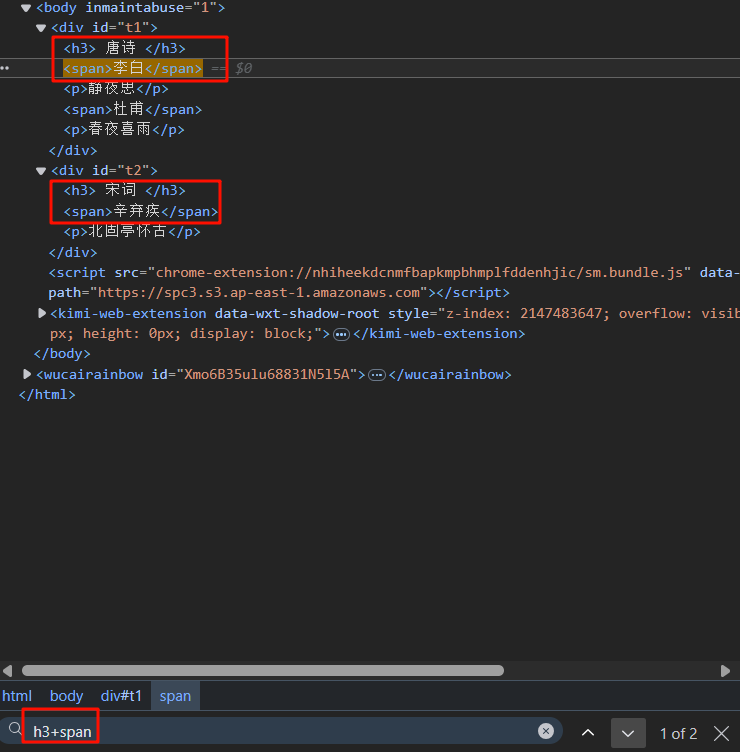
如选择以上div父节点的所有第4个子节点元素,div :nth-child(4) ,结果为<span>杜甫</span>,<p>明月几时有</p> ,如果需要限定第四个子元素的标签为span,可以用div span:nth-child(4) 表示父节点为div下的第四个子元素且标签为span的元素
元素:nth-of-type(num) 表示第num个某类型的元素
nth-last-of-type(num)为倒数num个元素
nth-of-type(even) 父元素的 所有偶数节点
nth-of-type(odd) 父元素的所有奇数节点
span:nth-child(2) # 表示同时满足既事第二个元素,且标签为span的元素,如果第二个元素不为span则不选择 span:nth-of-type(2) # 表示同级元素当中的第二个span元素

相邻兄弟节点
兄弟节点就是处在同级节点之间的元素,相邻兄弟节点表示是两个紧挨着的同级节点
h3 + span 表示h3节点相邻的span兄弟节点
h3 ~ span 表示h3节点后所有的span兄弟节点
窗口操作
窗口切换
frame内部窗口切换
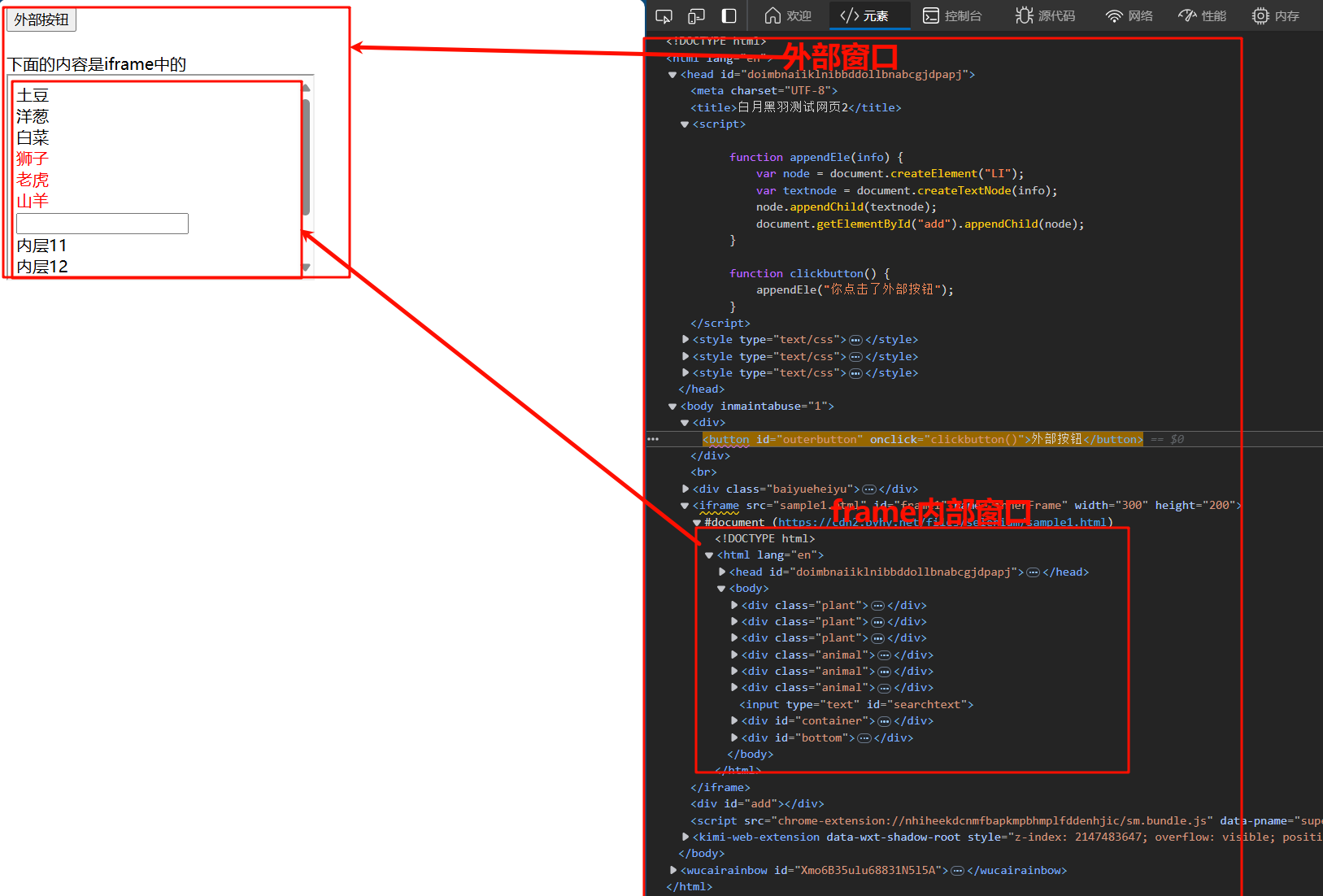
我们在打开以上页面发现一个很奇怪的方式,html里面内嵌了一个html的页面,这种实现是使用了一个frame内部窗口的标签,如果我们想操作frame内部的窗口元素,采用传统的css选择虽然可以选择到元素。但是实际采用代码不能查询到frame内部的元素。
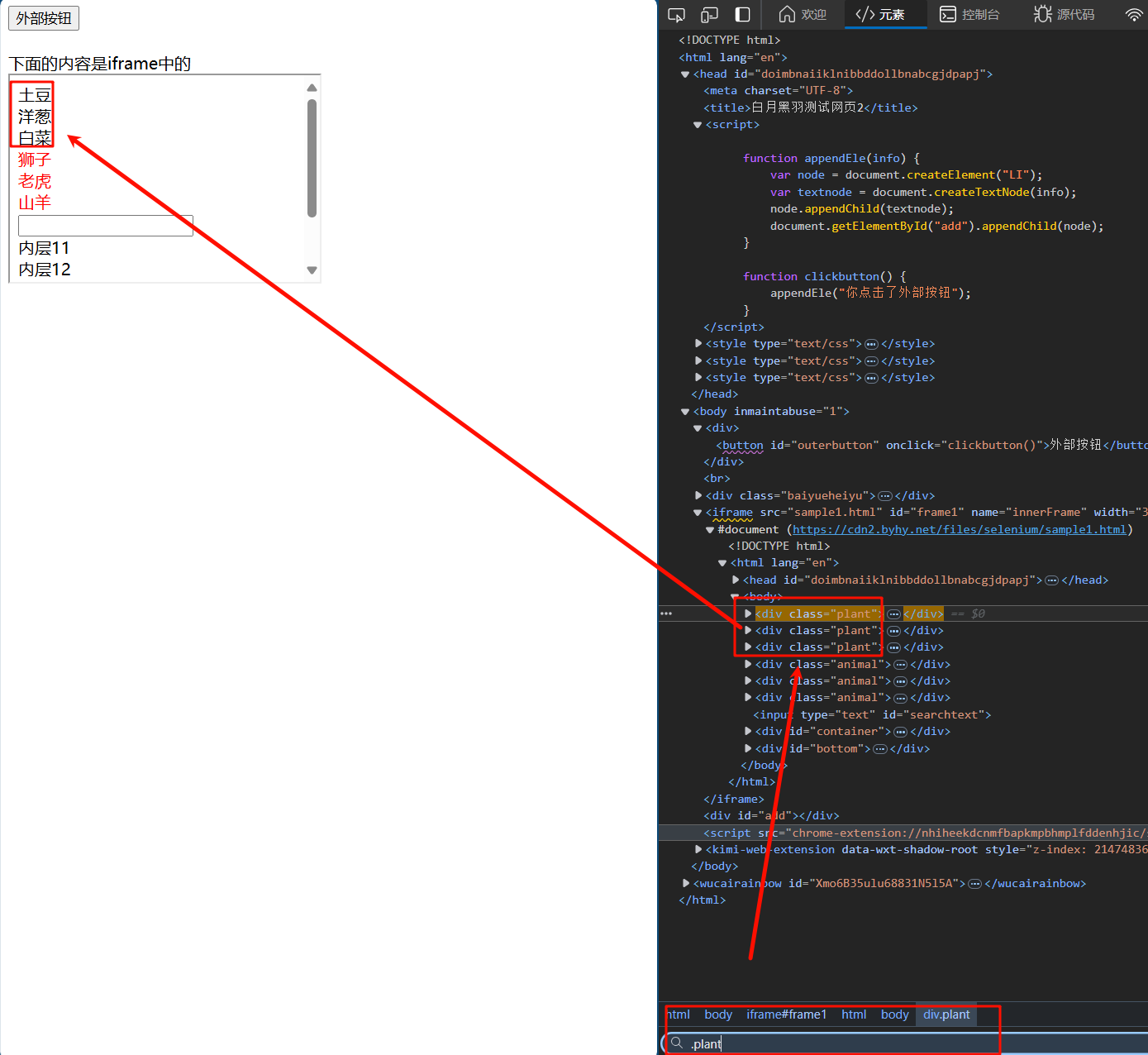
我们可以理解为wd对象只能操作默认的最外部的html元素,当需要操作frame内的元素时,可以使用switch_to.frame方法跳转工作区间为frame内部
wd.switch_to.frame(frame_reference) # frame_reference为frame标签的特征
frame_reference 可以是 frame 元素的属性 name 或者 ID ,也可以是CSS选择器,及我们只需要选择到frame标签即可,以下四种方法均可以选择到frame标签(iframe和frame相同)

wd.switch_to.frame('frame1') # 根据id
wd.switch_to.frame('innerFrame') # 根据name
wd.switch_to.frame(wd.find_element(By.TAG_NAME, "iframe")) # 根据tag_name
wd.switch_to.frame(wd.find_element(By.CSS_SELECTOR, '[src="sample1.html"]')) # 根据CSS选择器
从frame切换回原来的主html
wd.switch_to.default_content()
新老窗口切换
在网页上操作的时候,我们经常遇到,点击一个链接 或者 按钮,就会打开一个 新窗口 ,由于我们的程序只能控制老窗口,应该怎么把控制权转移到新窗口呢?
handle是每个网页窗口的唯一ID,用来确定窗口的标识符,我们可以使用Webdriver对象的switch_to属性的 window方法将控制权转移到对应的handle窗口
wd.switch_to.window(handle)
那么如何获取当前窗口handle呢,采用current_window_handle属性
wd.current_window_handle
WebDriver对象有window_handles 属性,这是一个列表对象, 里面包括了当前浏览器里面所有的窗口句柄,我们可以通过一个判断语法判断是否转移到我们指定的窗口(如下案例转换到bing窗口)
for handle in wd.window_handles:
# 先切换到该窗口
wd.switch_to.window(handle)
# 得到该窗口的标题栏字符串,判断是不是我们要操作的那个窗口
if 'Bing' in wd.title:
# 如果是,那么这时候WebDriver对象就是对应的该该窗口,正好,跳出循环,
break
同样的,如果我们在新窗口 操作结束后, 还要回到原来的窗口,该怎么办?我们可以在程序开始获取当前窗口的handle,然后当程序在新窗口执行完后,使用switch_to.window(handle)进行跳转。
# mainWindow变量保存当前窗口的句柄 mainWindow = wd.current_window_handle ... #通过前面保存的老窗口的句柄,自己切换到老窗口 wd.switch_to.window(mainWindow)
其他窗口操作
-
获取窗口大小
driver.get_window_size()
-
设置窗口大小
driver.set_window_size(x, y) # wd.set_window_size(2022, 1086) 正常应该页面的大小
-
获取当前窗口标题
driver.title
-
获取当前窗口URL地址
driver.current_url
-
对当前网页截图并保存
# 截屏保存为图片文件
wd.get_screenshot_as_file("1.png")
案例:获取并修改窗口的大小,并跳转到网易网站打印网站的标题和路径,将网易的截图保存在本地路径
wd.get("https://cdn2.byhy.net/files/selenium/test4.html")
# 获取windows窗口的大小,get_window_size()返回一个dict字典对象{'width': 1011, 'height': 1086}
windows_size = wd.get_window_size()
print(windows_size)
sleep(1)
# 修改windows窗口的大小
wd.set_window_size(2022, 1086) # 传入字典的宽x和高y
# 跳转到163网站,并打印网站标题和url
wd.get("https://www.163.com")
print("title:" + wd.title + ",url:" + wd.current_url) # 网易 https://www.163.com/
sleep(0.5)
# 截屏保存为图片文件
wd.get_screenshot_as_file("1.png")
选择框
选择框包含单选框radio、复选框checkbox、以及下拉列表框select(select也分为单选下拉框和复选下拉框)
radio单选框

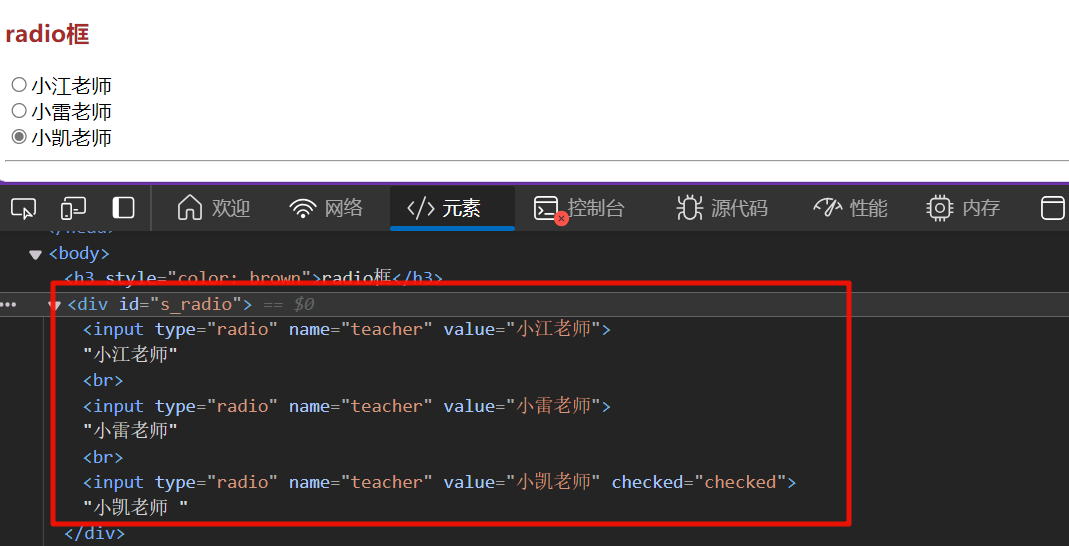
radio框称为单选radio框,一般为<input type="radio"> checked=”checked”表示默认选择
选择单选框:获取需要选择的单选框元素并点击
# 点击单选框“小江老师” wd.find_element(By.CSS_SELECTOR, '[type=radio][value="小江老师"]').click()
checkbox复选框
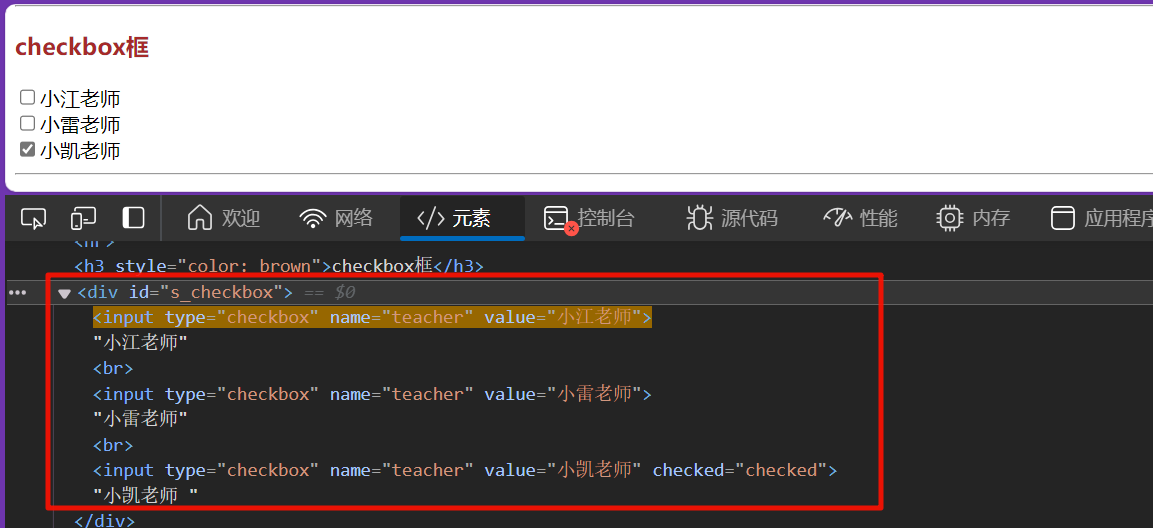
对checkbox进行选择,也是直接用 WebElement 的 click 方法,模拟用户点击选择。
但是复选框需要先将默认的选项点击一遍,取消选项后再选择自己需要选择的选项。
我们的思路可以是这样:
-
先把 已经选中的选项全部点击一下,确保都是未选状态
-
再点击 小江老师、小雷老师
# 获取复选框元素
checked_elements = wd.find_elements(By.CSS_SELECTOR, '#s_checkbox > [name=teacher][checked=checked]')
# 清除复选框已选择元素
for element in checked_elements:
element.click()
# 复选框选择元素
wd.find_element(By.CSS_SELECTOR, '#s_checkbox [value="小江老师"]').click()
wd.find_element(By.CSS_SELECTOR, '#s_checkbox [value="小凯老师"]').click()
Select框
select框一般为下拉列表框,包括select单选下拉框和select复选下拉框
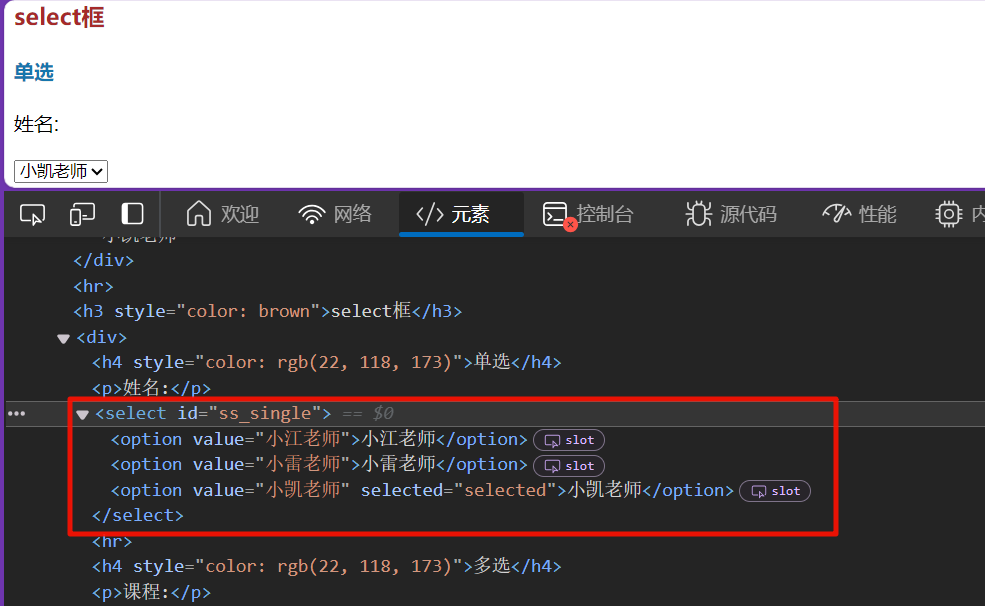
对于Select 选择框, Selenium 专门提供了一个 Select类 进行操作。
通过CSS选择器创建Select对象。
select = Select(wd.find_element(By.CSS_SELECTOR, '#ss_single'))
Select提供了一系列函数用于操作select选项框
-
select_by_index() 通过index索引选择
-
select_by_value() 通过value属性值选择
-
select_by_visible_text() 通过界面显示文字选择
-
deselect_by_value() 根据value属性取消选择元素
-
deselect_by_index() 根据index索引取消选择元素
-
deselect_by_visible_text() 根据前端字面属性取消选择元素
-
deselect_all() 取消所有已选择的元素
对select单选下拉框进行操作
# 单选框
select = Select(wd.find_element(By.CSS_SELECTOR, '#ss_single'))
# 通过单选选项索引选择
select.select_by_index(0)
sleep(1)
# 通过单选项value属性选择
select.select_by_value('小雷老师')
sleep(1)
# 通过前端可视化文本选择
select.select_by_visible_text('小凯老师')
对select复选下拉框进行操作,由于复选框提供了一系列取消选择的操作,我们可以在选择前调用deselect_all()方法取消所有的默认元素,进而再选择元素
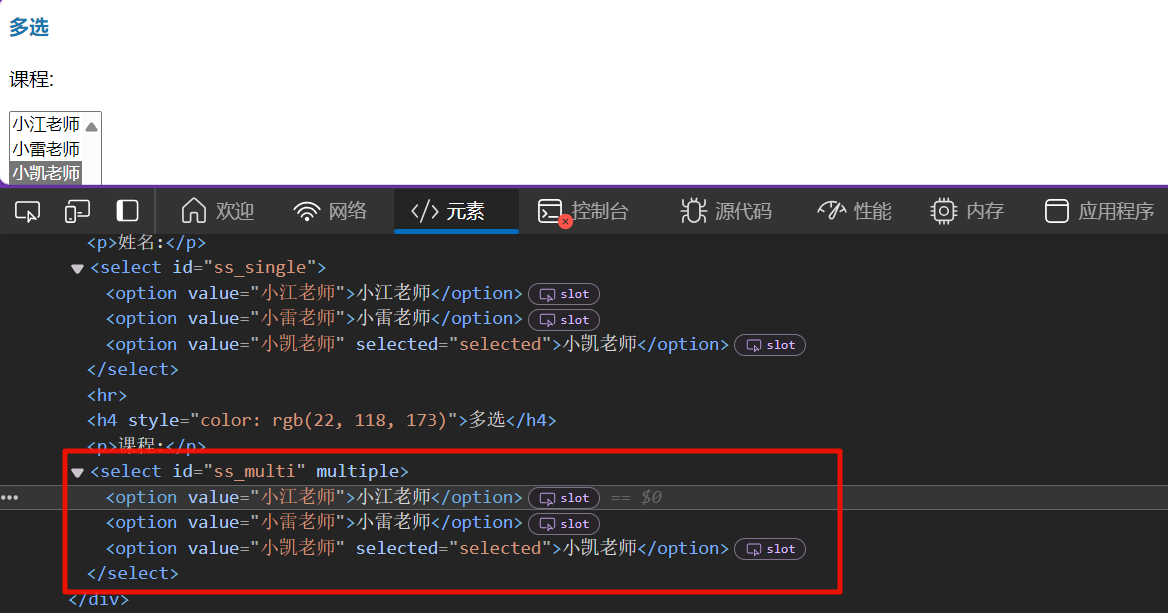
# 复选框
# 根据CSS选择器创建Select复选框操作对象
multi_select = Select(wd.find_element(By.CSS_SELECTOR, '#ss_multi'))
# 清除所有已选元素
multi_select.deselect_all()
# 复选框多选元素
multi_select.select_by_visible_text("小雷老师")
multi_select.select_by_visible_text("小凯老师")
元素复杂操作
在界面元素中,除了一些常规的点击,输入操作,还有一些更高级的操作,如鼠标悬停、右键、双击等…
如百度页面,鼠标悬停在更多才会显示一些隐藏元素,那么这样的鼠标悬停操作怎么实现?可以通过创建ActionChains对象的方法实现一些高级操作。

实现如上操作的代码
from selenium.webdriver.common.action_chains import ActionChains # 导入ActionChains类包
wd = webdriver.Chrome()
wd.implicitly_wait(5)
wd.get("https://www.baidu.com/")
# 传入WebDriver对象用于创建ActionChains对象,调用对象方法用于实现一些高级操作
ac = ActionChains(wd)
# 调用move_to_element方法实现光标移动悬停到指定元素上,调用perform()执行操作。
ac.move_to_element(wd.find_element(By.CSS_SELECTOR, "[name=tj_briicon]")).perform()
冻结界面
如何查看隐藏元素对应的html代码,在F12控制台执行javascrpt脚本,setTimeout(function(){debugger},5000) 如下所示,执行脚本5s之后自动进入debugger模式
弹窗操作
在操作界面的时候会出现一些弹窗,这些弹窗不是内嵌在html元素内的,不可以被F12检索,我们需要调用alert方法去操作
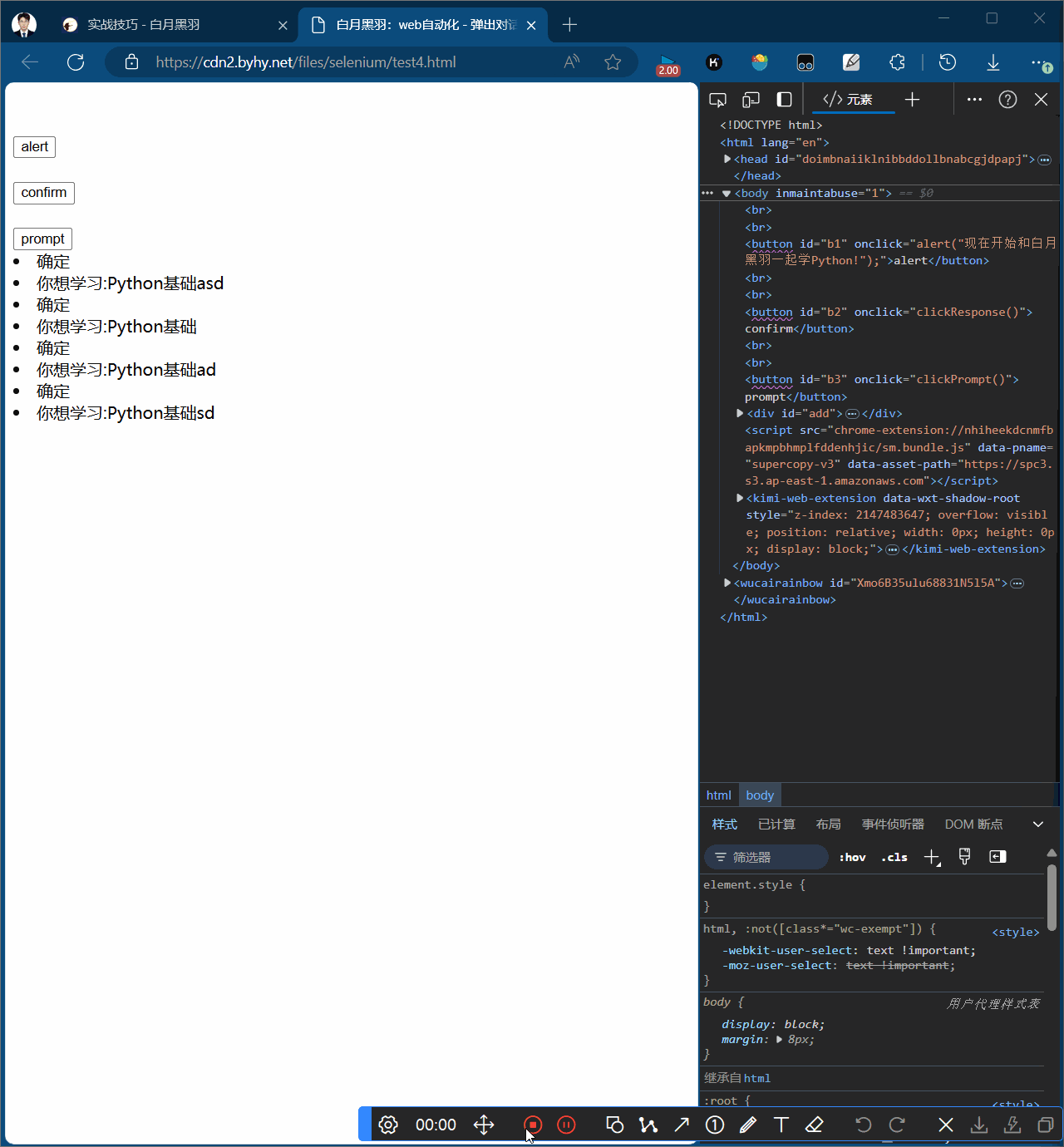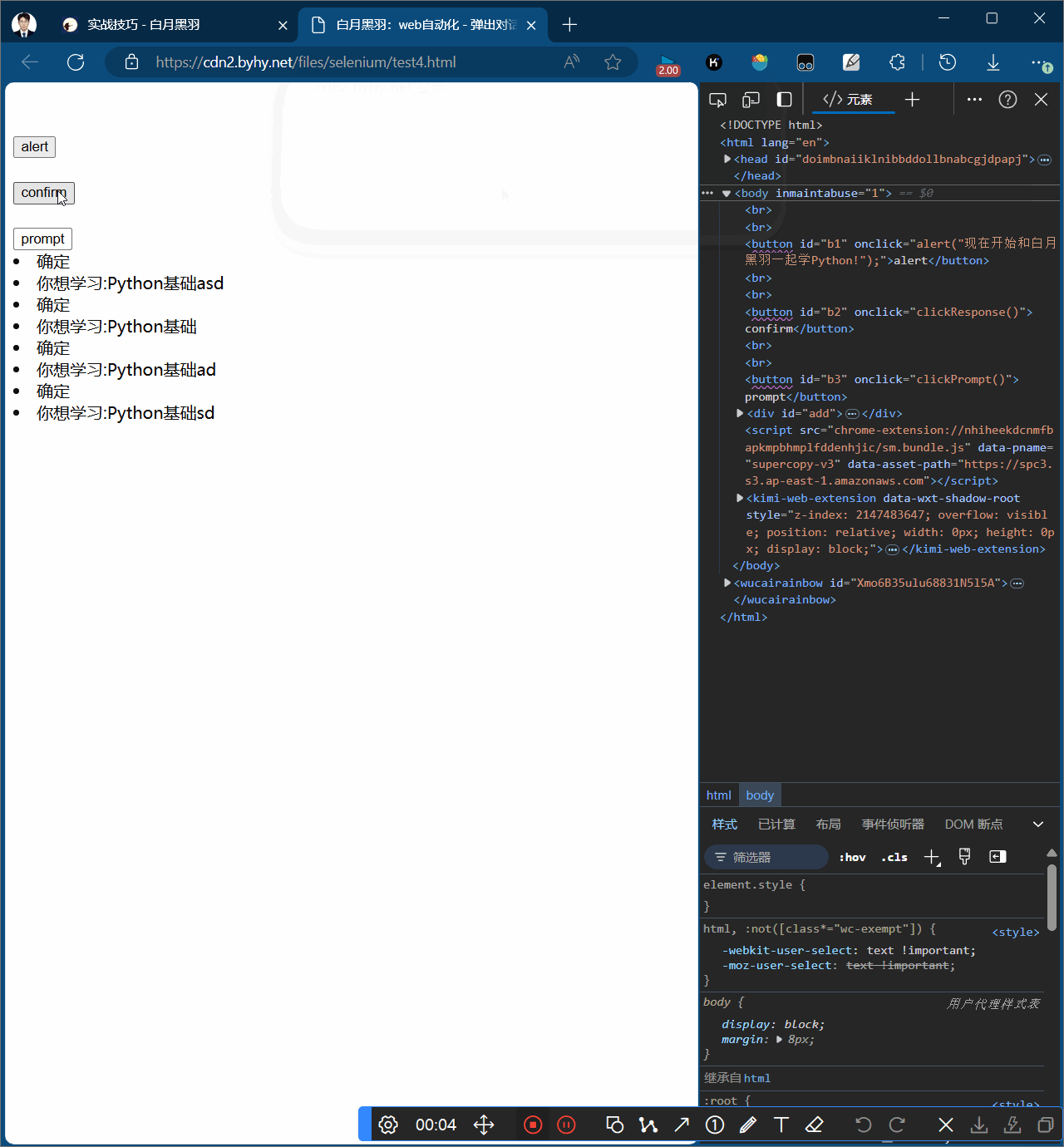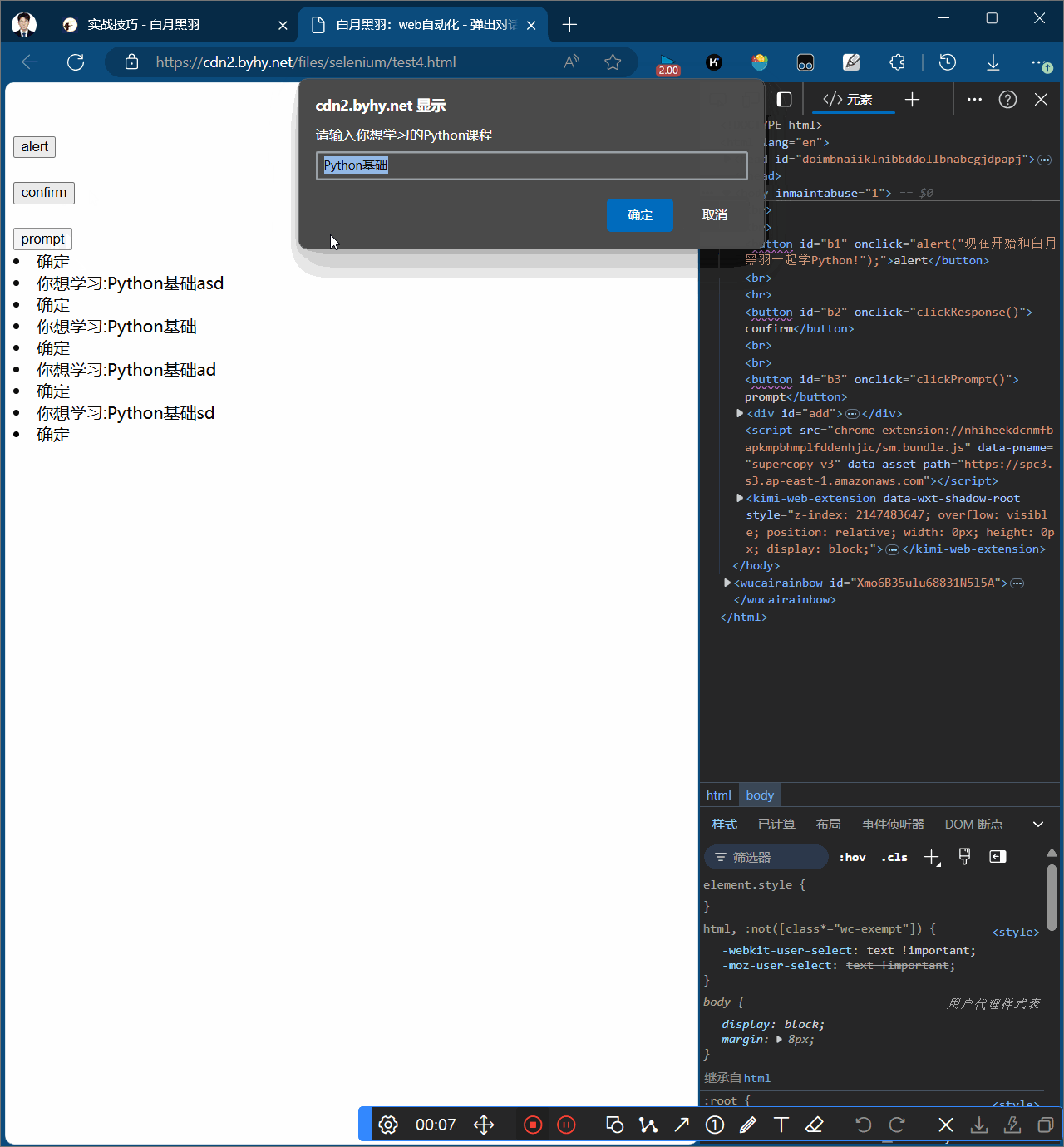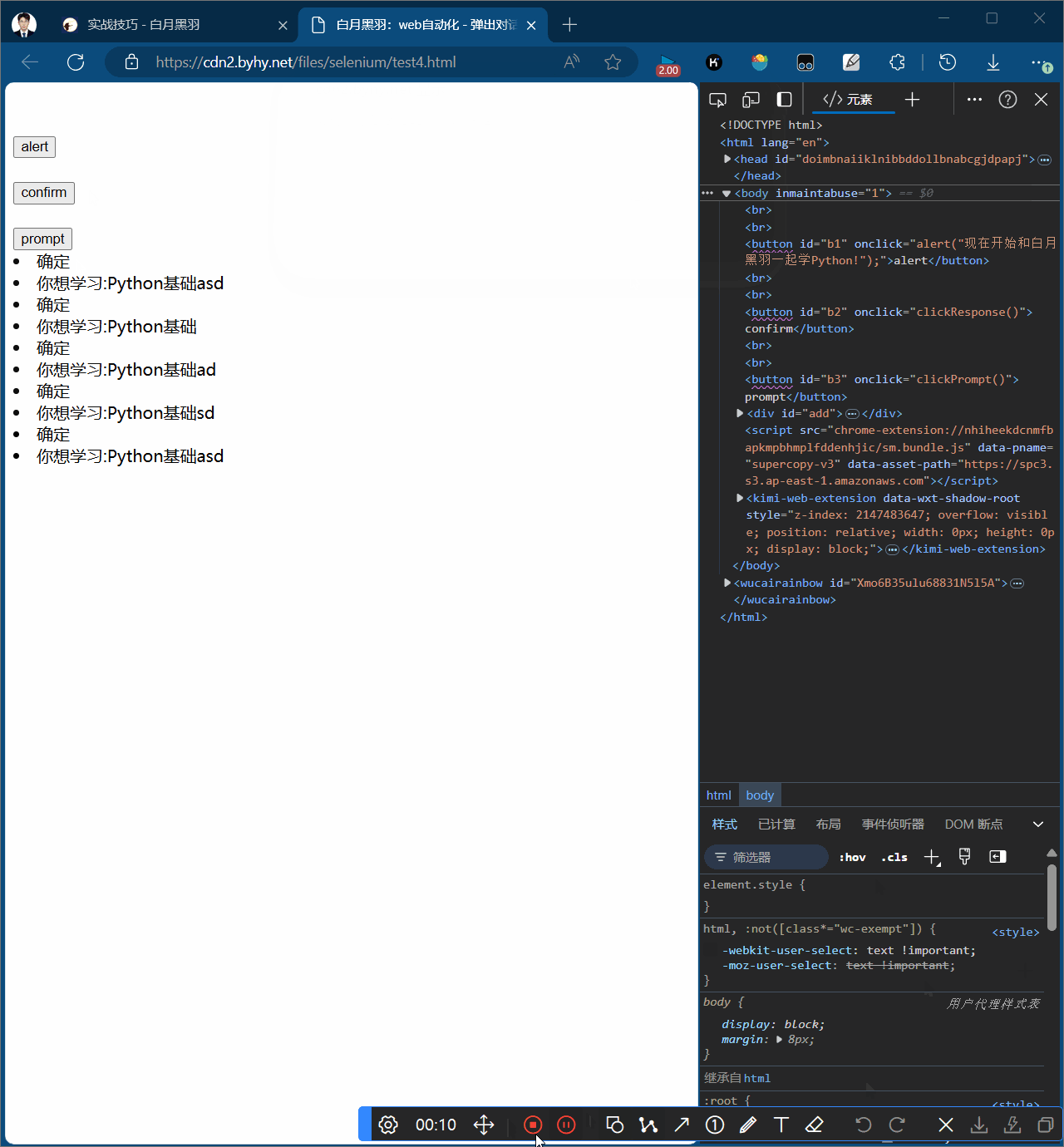
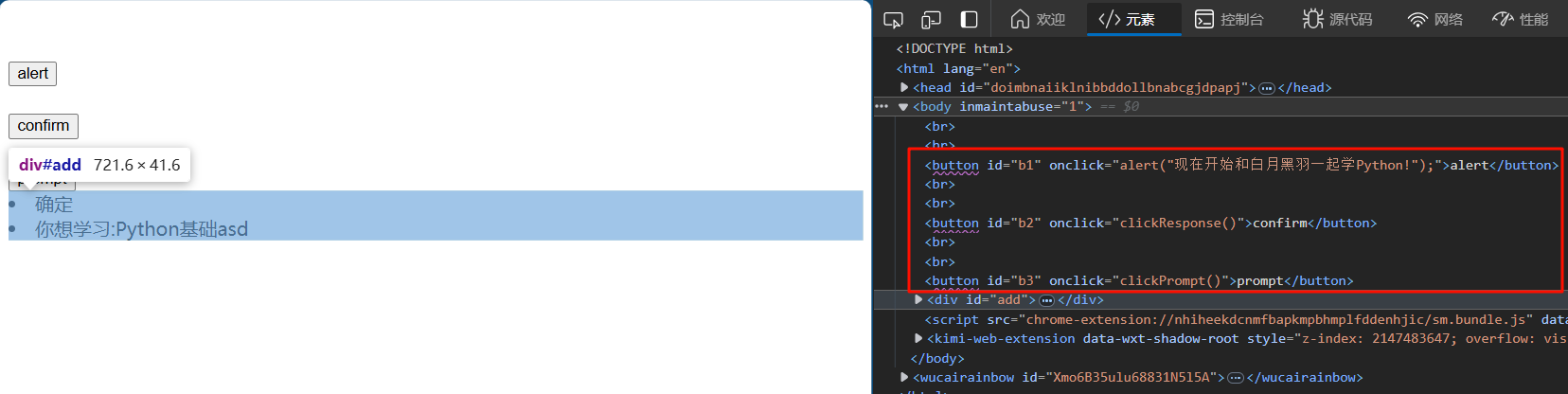
alert弹窗分为三种,
-
第一种是最原始的alert弹窗,只能点击确认按钮
-
第二种confirm弹窗,可以有确认和取消两个按钮
-
第三中是prompt弹窗,可以输入文本上传
alert弹窗
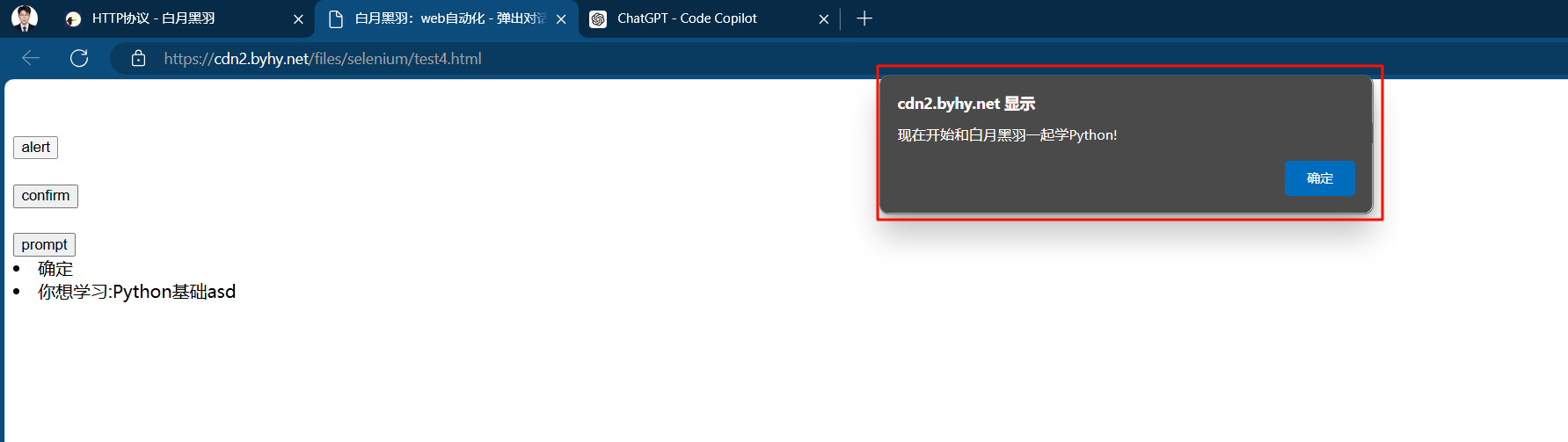
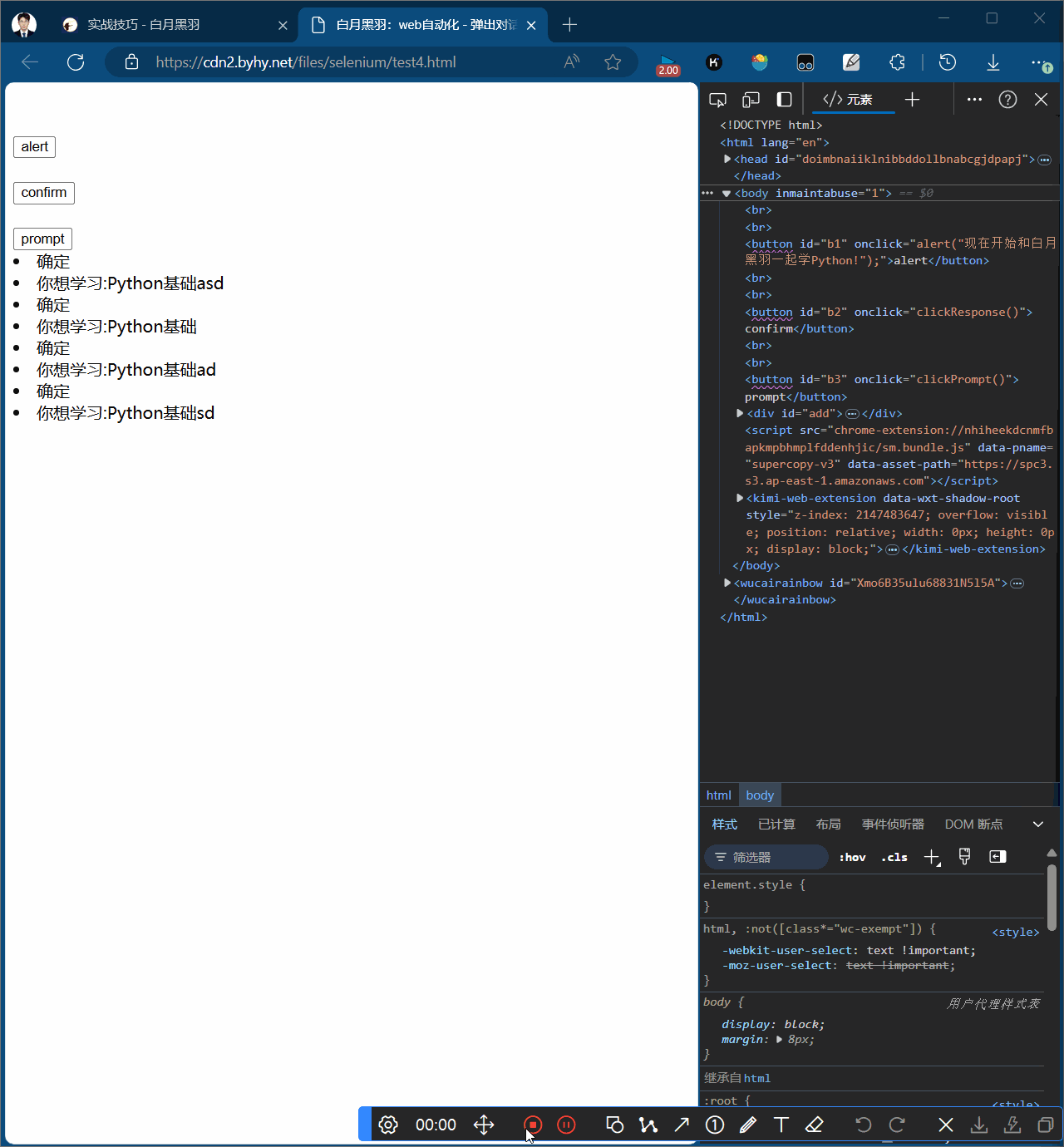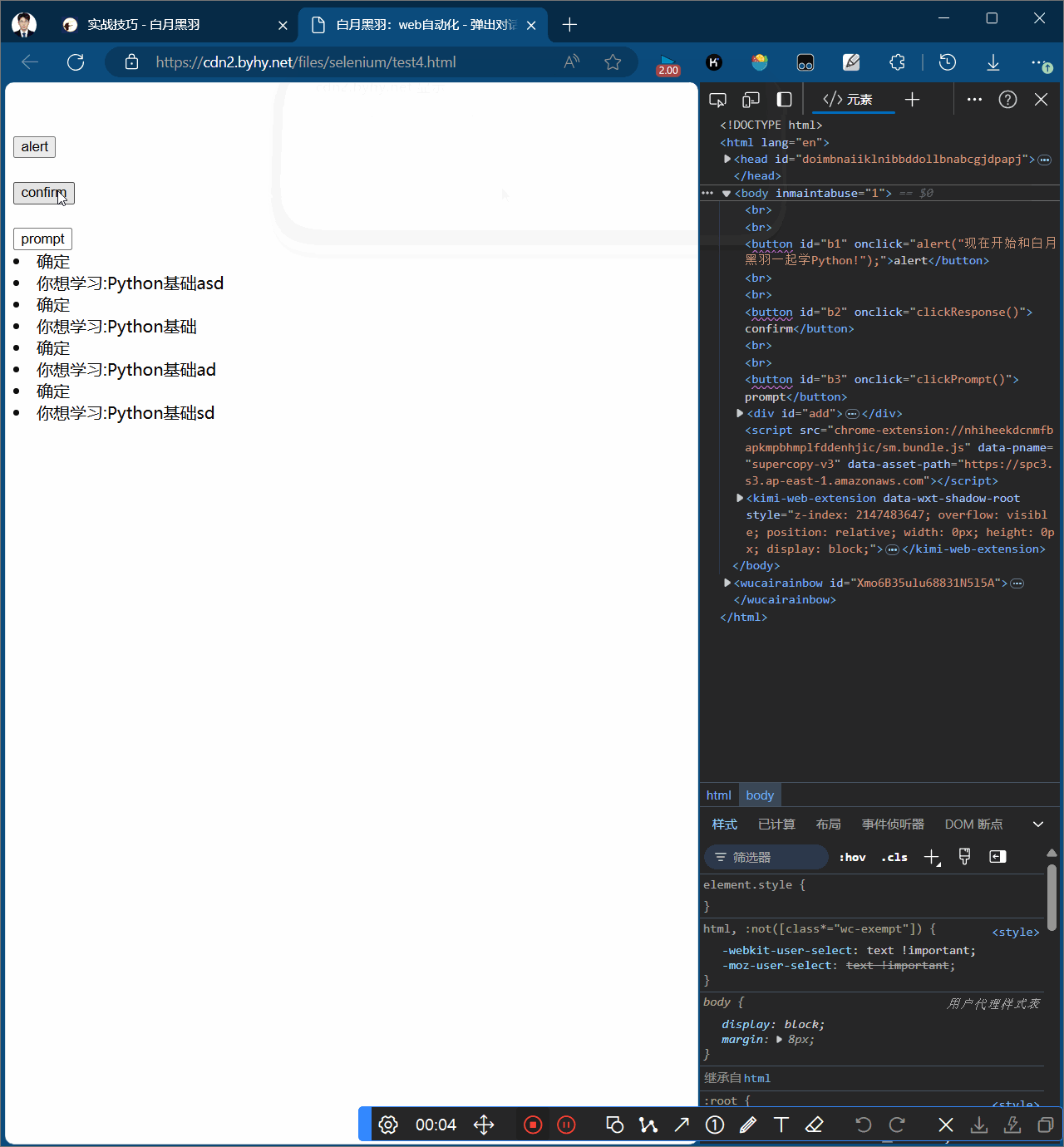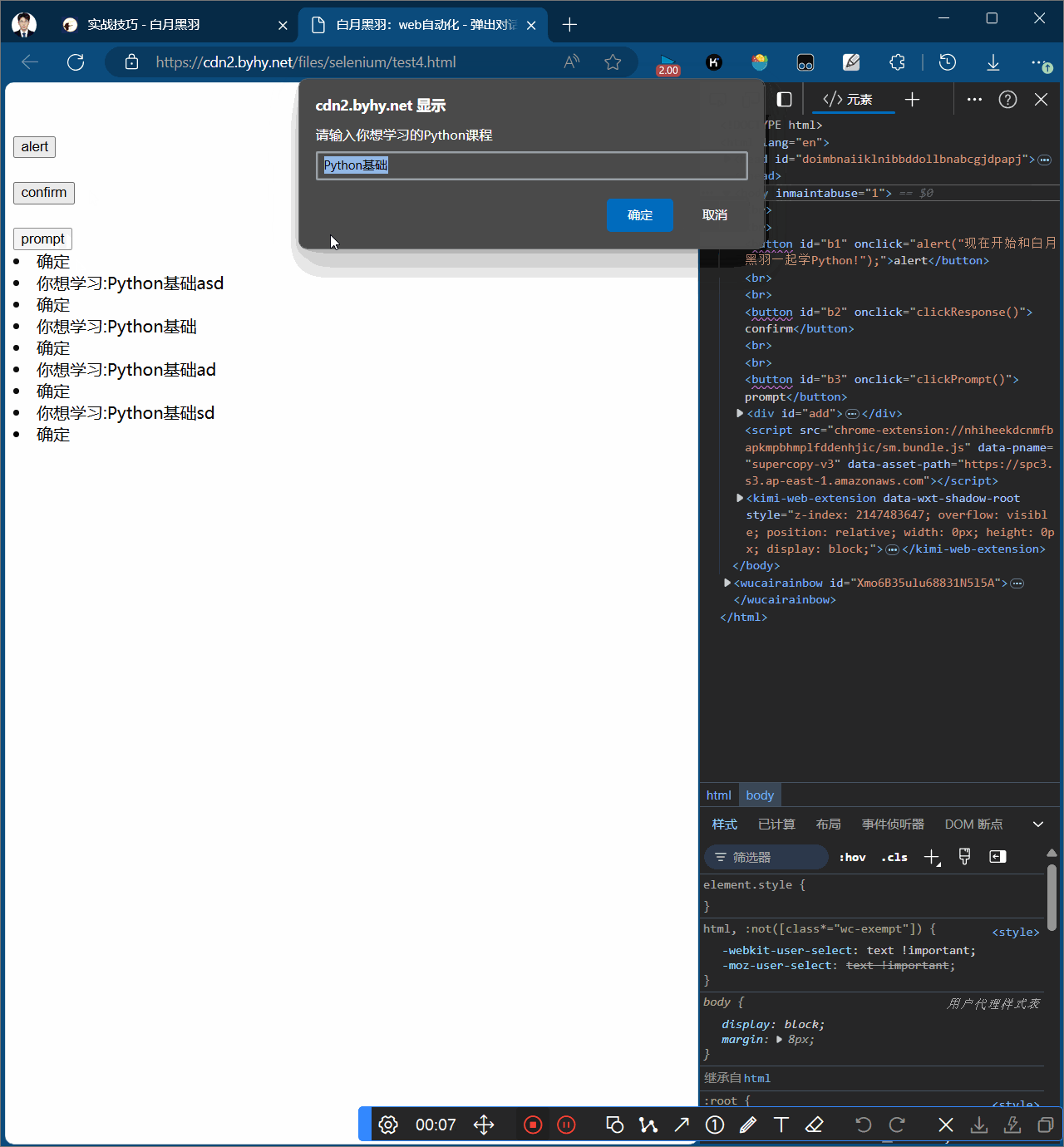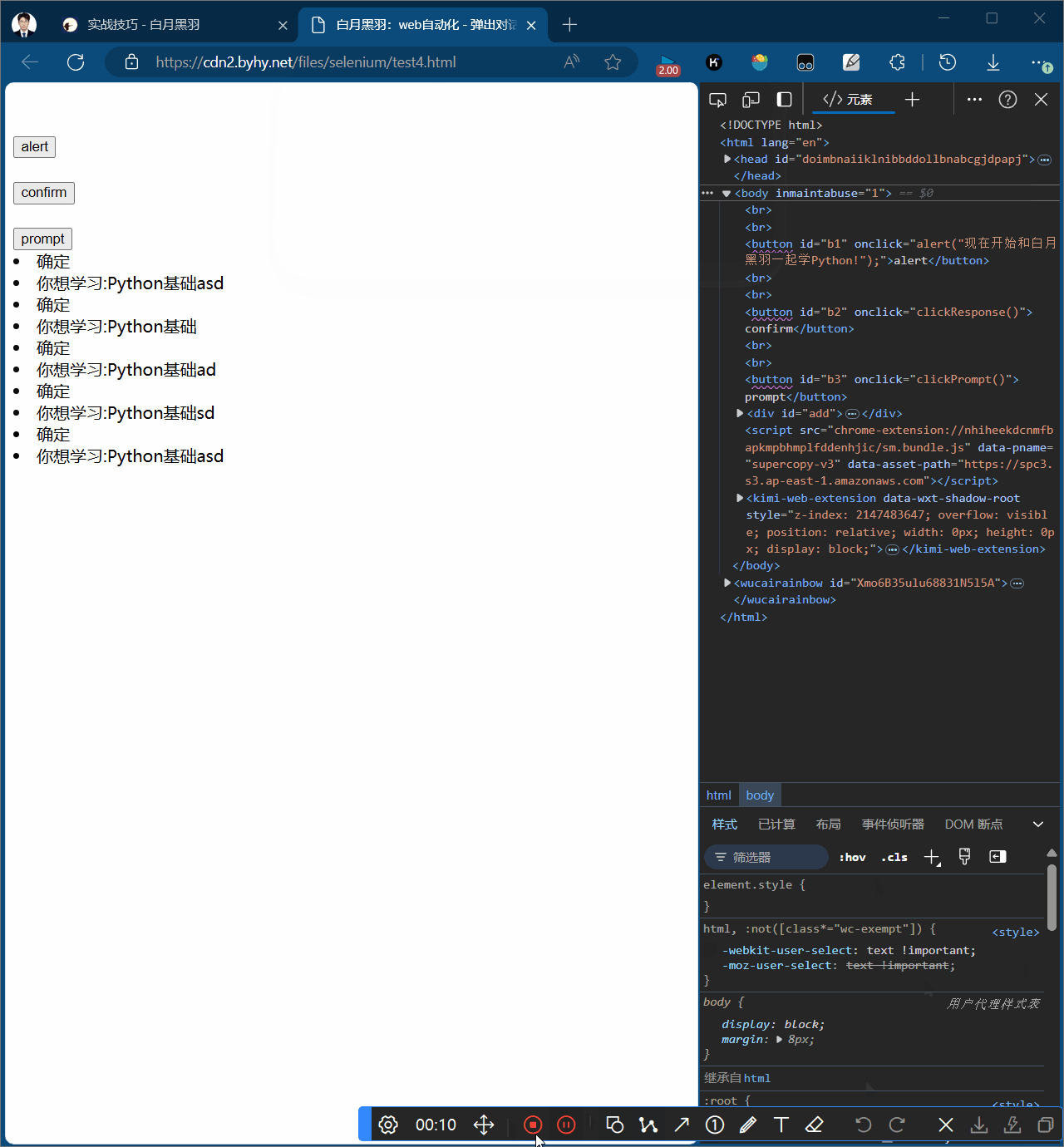
alert弹窗只能点击确认按钮,wd.switch_to.alert返回一个alert对象
# alert弹窗 # 1.点击b1按钮 wd.find_element(By.CSS_SELECTOR, "#b1").click() # 2.打印弹窗输出 print(wd.switch_to.alert.text) sleep(2) # 3.点击alert弹窗的ok按钮,关闭弹窗 wd.switch_to.alert.accept() sleep(2)
confirm弹窗
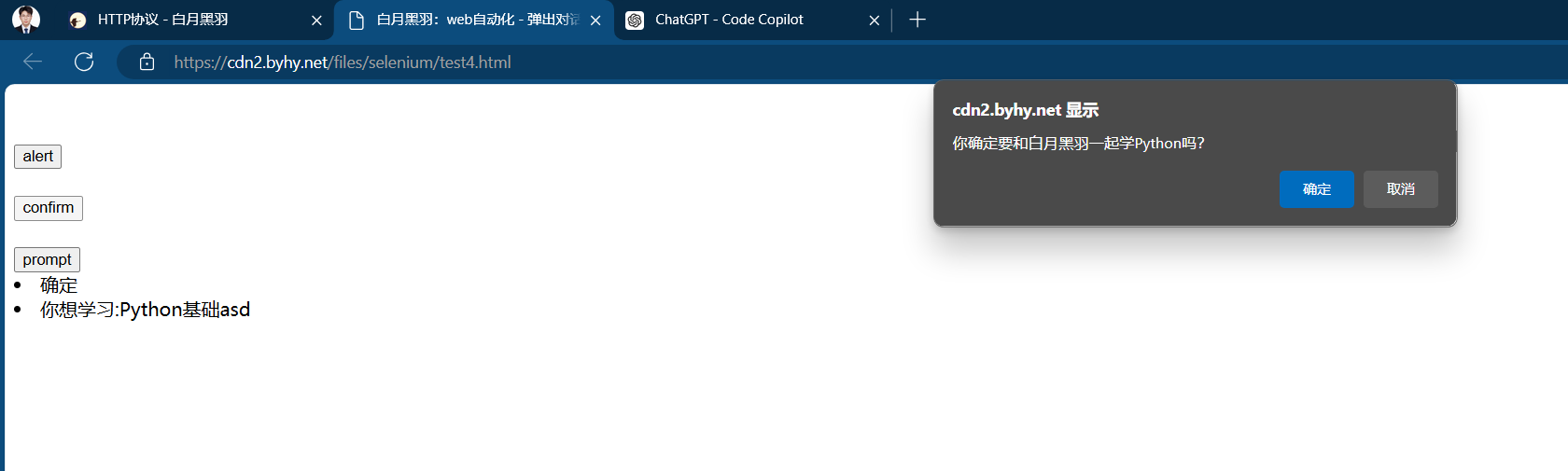
confirm弹窗,可以有确认和取消两个按钮,确认方法alert.accept()、取消方法alert.dismiss()
# confirm弹窗 # 1.点击b2 wd.find_element(By.CSS_SELECTOR, "#b2").click() # 2.打印弹窗输出 print(wd.switch_to.alert.text) sleep(2) # 3.可以对弹窗操作accept和dismiss # wd.switch_to.alert.dismiss() 取消 wd.switch_to.alert.accept() # 接受 sleep(2)
Prompt弹窗
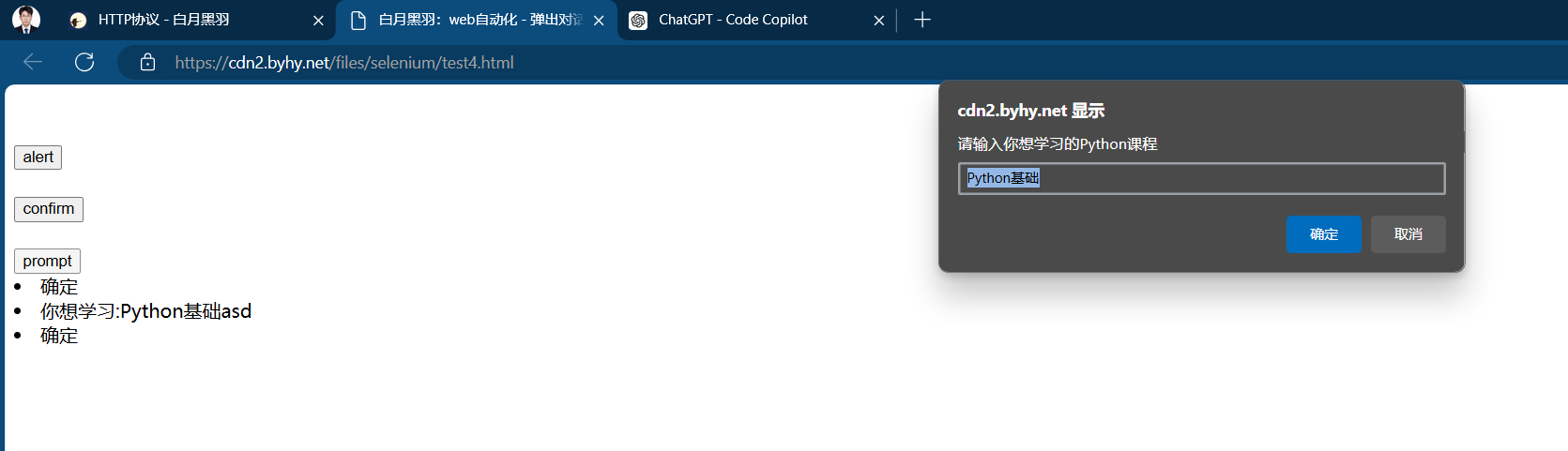
含有确认和取消方法,且可以输入文字alert.send_keys("hello world!")
# Prompt弹窗
# 1.点击b3
wd.find_element(By.CSS_SELECTOR, "#b3").click()
# 2.给弹窗输入框输入文字
wd.switch_to.alert.send_keys("hello world!")
# 3.打印弹窗输出
print(wd.switch_to.alert.text)
sleep(2)
# 4.可以对弹窗操作accept和dismiss
# wd.switch_to.alert.dismiss() 取消
wd.switch_to.alert.accept() # 接受
sleep(2)
有些弹窗并非浏览器的alert 窗口,而是html元素,这种对话框,只需要通过之前介绍的选择器选中并进行相应的操作就可以了。
上传文件
网站页面上传文件的功能,是通过 type 属性 为 file 的 HTML input 元素实现的。
如下所示:
<input type="file" multiple="multiple">
针对网站的input元素的上传文件操作,我们可以调用send_keys()方法自动化实现文件上传功能
# 先定位到上传文件的 input 元素 ele = wd.find_element(By.CSS_SELECTOR, 'input[type=file]') # 再调用 WebElement 对象的 send_keys 方法 ele.send_keys(r'h:\g02.png')
如果需要上传多个文件,可以多次调用send_keys,如下
ele = wd.find_element(By.CSS_SELECTOR, 'input[type=file]') ele.send_keys(r'h:\g01.png') ele.send_keys(r'h:\g02.png')
案例,针对TinyPNG – Compress WebP, PNG and JPEG images intelligently图片压缩网站实现上传图片功能
wd.get("https://tinypng.com/")
# 查找input上传输入框
upload_input = wd.find_element(
By.CSS_SELECTOR, ".bg-gradient #upload-dropbox-zone input"
)
# send_keys上传图片
upload_input.send_keys(r"C:\workspace\1.png")
# 压缩结束,点击下载按钮
wd.find_element(By.CSS_SELECTOR, ".button-wrapper span").click()
但是,有的网页上传,是没有 file 类型 的 input 元素的。
如果是Windows上的自动化,可以采用 Windows 平台专用的方法:及点击上传按钮,模拟键盘交互输入文件路径进行手动上传
# 找到点击上传的元素,点击
driver.find_element(By.CSS_SELECTOR, '.dropzone').click()
sleep(2) # 等待上传选择文件对话框打开
# 发送键盘交互给当前页面,键盘传入图片路径并回车
import win32com.client
shell = win32com.client.Dispatch("WScript.Shell")
# 输入文件路径,最后的'\n',表示回车确定,也可能时 '\r' 或者 '\r\n'
shell.Sendkeys(r"h:\a2.png" + '\n')
sleep(1)
XPath表达式
XPath表达式与CSS表达式对比
-
CSS选择器比XPath更快,因为浏览器在渲染页面时已经解析了CSS
-
CSS选择器的功能相对有限,不能直接选择基于文本内容的元素,也不能反向选择父级元素
-
CSS选择器在浏览器中有良好的支持,所有主流的浏览器都支持CSS选择器,但XPath表达式看你需要借助一些API
而Xpath表达式
-
XPath能够
实现非常复杂的选择逻辑,比如基于元素文本内容的选择、反向选择(选择父元素)、计算索引、以及条件判断 -
XPath可以灵活地处理文档结构的变化,提供了丰富的轴(axes),如祖先轴、兄弟轴等,便于定位复杂的节点关系。
xpath 语法中,整个HTML文档根节点用'/'表示
/html /html/body/div # 表示选择html下面的body下面的div元素,等价于CSS表达式 html>body>div
自动化程序采用如下方式实现XPath语法定位
element是= driver.find_elements(By.XPATH, "/html/body/div")
查找任意位置的元素,采用//, 表示从当前节点往下寻找所有的后代元素,不管它在什么位置。
//div # 表示页面内任意位置所有的div 类似于css下的 div //div//p # 表示所有div元素下的所有的p元素 css下的 div p /div//p # 表示直接位于根节点下的div元素下的所有p元素 //div/p # 表示div元素下的直接子节点为p的元素 类似于div>p
通配符*,表示匹配所有元素
//div/* # 任意div下的所有直接子元素 等价于div>*
属性选择,格式[@属性名='属性值']
XPath所有的属性前都需要用@符号标识,而CSS表达式针对于class和id属性有特殊表示;且XPath属性值一定要用引号,而CSS表达式只要属性不包含空格和特殊字符,可以不使用引号,这是两者之间不同的地方。
//*[@id='west'] # 选择所有id为west的元素 //p[@class="capital"] # 选择所有class属性为capital的元素 //*[@multiple] # 选择含有multiple属性的元素
针对于class属性有个注意点,如果一个元素有多个class如下:
<p id="beijing" class='capital huge-city'>
北京
</p>
那我们根据class选择该属性时,必须使用全部的class查找://p[@class="capital huge-city"],而使用单个class查找不到元素//p[@class="capital"]
属性值包含字符串操作
//*[contains(@style,'color')] # style属性包含color值 //*[starts-with(@style,'color')] # style属性值以color开头 //*[ends-with(@style,'color')] # style属性值以color结尾的元素(仅支持xPath2.0语法)
文本选择
如果一个元素的文本显示固定,那我们可以直接通过文本去选择该元素
如元素:
<div class="fxc-menu-listView-item" data-telemetryname="Menu-windows10Update">Windows updates</div>
我们需要找页面文本显示为Windows updates的元素并点击,选择的xpath语句为:
//div[text()='Windows updates']
详细点也可以写为
//div[@class='fxc-menu-listView-item' and text()='Windows updates']
按正序选择元素
//p[2] # 选择层级下第二个标签为p的元素 类似于p:nth-of-type(2),与p:nth-child(2)不同,表示第二个元素且标签需要满足为p //div/*[2] # 选择任意div元素下的任意类型的第二个元素 (//*[@id="root"]//div[@class="root-298"])[1] # 满足()内条件的多个元素取第一个
按倒序选择元素
我们可以理解last()本身表示倒数第一个元素,last()-1表示倒数第二个元素
//p[last()] # 选取p类型下的倒数第一个子元素 //p[last()-1] # 选取p类型下的倒数第二个子元素
按范围选择
position() 表示允许选择的位置,从1开始计数
//option[position()<=2] # 表示选取任意option元素的前两个元素,也可以写成//option[position()<3] //*[@class='multi_choice']/*[position()<=3] # 选择class属性为multi_choice的前3个子元素 //*[@class='multi_choice']/*[position()>=last()-2] # 选择class属性为multi_choice的后3个子元素
组选择
XPath选择多组条件的表达式,不同表达式采用|隔开
//option | //h4 # option标签的元素和h4标签的元素 等同于 option,h4 //*[@class='single_choice'] | //*[@class='multi_choice'] # 要选所有的 class 为 single_choice 和 class 为 multi_choice 的元素 等同于CSS选择器 .single_choice , .multi_choice
选择父节点
某个元素的父节点用 /.. 表示,要选择 id 为 china 的节点的父节点,可以这样写 //*[@id='china']/..
当某个元素没有特征可以直接选择,但是它有子节点有特征, 就可以采用这种方法,先选择子节点,再指定父节点。还可以继续找上层父节点,比如 //*[@id='china']/../../..
比如说我想找在1标签div下的所有文本信息,首先我得找到div标签,但是我们发现div标签没有任何特性,因此我们可以找到标签2具有class特性的子节点div,通过子节点找到对应的父节点,再获取父节点下所有的具有id的p标签的元素获取内容
//p[@style]/..//p[@id] # 获取div下所有的p标签元素
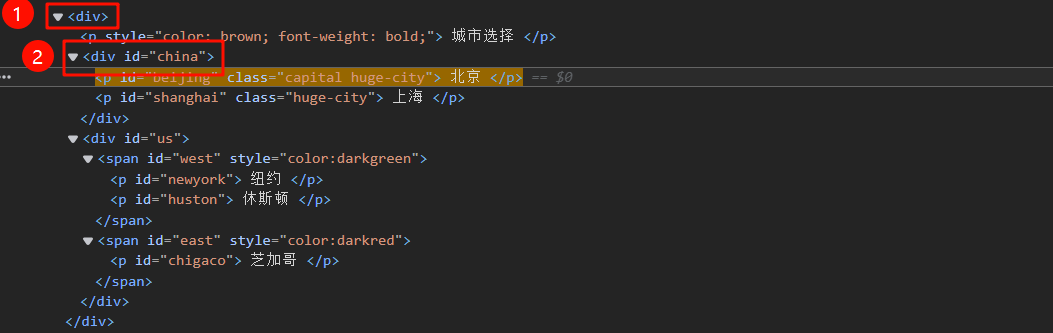
兄弟节点选择
xpath也可以选择后续兄弟节点,用这样的语法 following-sibling:: ,等同于 ~
//*[@class='single_choice']/following-sibling::* # 选择class='single_choice'的任意标签的元素的所有后面的兄弟节点元素 等同于.single_choice ~ * //*[@class='single_choice']/following-sibling::div # 选择class='single_choice'的任意标签的元素的所有后面的兄弟节点为div的元素 //*[@class='single_choice']/preceding-sibling::*[1] #选择class='single_choice'的任意标签的元素的后面的第一个兄弟节点元素 等同于.single_choice ~ nth-child(1)
path还可以选择 前面的 兄弟节点,用这样的语法 preceding-sibling:: css不能选择前面兄弟节点元素
//*[@class='single_choice']/preceding-sibling::*[1] # 选择class为single_choice元素前面的第一个靠近的任意类型的兄弟节点的元素 //*[@class='single_choice']/preceding-sibling::*[2] # 前面class为single_choice的第2靠近的兄弟节点元素
selenium框架采用Xpath语法选择元素的易错点
-
先选择示例网页中,id是china的元素
-
然后通过这个元素的WebElement对象,使用find_elements_by_xpath,选择china元素内部的p元素,
# 先寻找id是china的元素
china = wd.find_element(By.ID, 'china')
# 再选择该元素内部的p元素
elements = china.find_elements(By.XPATH, '//p')
# 打印结果
for element in elements:
print('----------------')
print(element.get_attribute('outerHTML'))
运行发现,打印的不仅仅是 china内部的p元素, 而是所有的p元素。elements = china.find_elements(By.XPATH, '//p')这一步还是以整个页面WebDriver去查找元素,为了查找china元素下满足//p的元素,应该在表达式前加.,正确语法如下:
elements = china.find_elements(By.XPATH, './/p')
但是采用CSS选择器却可以直接多元素element操作查找里面的元素,不需要额外加.
Selenium项目实战
分层设计总结
-
测试用例层(testcase):编写测试用例、组织业务流程和断言。
-
业务逻辑层(service):封装高层业务功能,复用多个页面的操作。
-
页面对象层(page):通过页面对象模型封装页面操作和元素定位。
-
基础功能层(base):为页面对象提供基础支持和 Selenium 操作封装。
-
配置和数据层(data):存储项目的配置信息和测试数据。
-
日志和报告层(logging):记录日志并生成测试报告。
-
工具层(utils):提供工具方法供项目使用。
测试用例层(Testcase)
-
职责:这一层主要负责编写测试用例,是实际调用测试步骤的地方。该层不涉及具体的操作细节,只是根据业务逻辑来定义测试步骤和断言。
-
主要内容
-
测试用例(Test Cases)
-
参数化(Parameterization)
-
断言(Assertions)
-
示例:
import pytest
from pages.login_page import LoginPage
from pages.dashboard_page import DashboardPage
@pytest.mark.parametrize('username, password', [('user1', 'pass1'), ('user2', 'pass2')])
def test_login(username, password):
login_page = LoginPage(driver)
dashboard_page = login_page.login(username, passwo
业务逻辑层(Business Logic)
职责:负责封装业务流程,如“用户登录”、“用户注册”等。将一系列页面操作组合起来,形成业务功能。测试用例调用这些业务功能,而不需要关心具体的页面细节。
主要内容:
-
业务功能方法
-
多个页面操作的组合
from pages.login_page import LoginPage
from pages.dashboard_page import DashboardPage
def login_to_dashboard(driver, username, password):
login_page = LoginPage(driver)
return login_page.login(username, password)
页面对象层(Page Object)
-
职责:这一层使用页面对象模型(Page Object Model,POM),每个页面或组件都有相应的类,封装页面操作和元素定位。将页面操作方法与测试分离,保持测试代码简洁。
-
主要内容
-
每个页面类代表一个页面或页面组件
-
页面方法封装了页面的操作,如“输入用户名”、“点击登录”等
-
示例:
from selenium.webdriver.common.by import By
from base.base_page import BasePage
class LoginPage(BasePage):
def __init__(self, driver):
self.driver = driver
self.username_input = (By.ID, 'username')
self.password_input = (By.ID, 'password')
self.login_button = (By.ID, 'loginBtn')
def login(self, username, password):
self.send_keys(self.username_input, username)
self.send_keys(self.password_input, password)
self.click(self.login_button)
return DashboardPage(self.driver)
基础功能层(Base)
-
职责:这一层提供一些基础功能,比如封装 Selenium 的常用操作(点击、输入、等待等),并为页面对象提供继承支持。可以定义
BasePage类,供其他页面继承。 -
主要内容
-
基础页面类(Base Page Class)
-
通用操作方法(如
click(),send_keys()等)
-
示例:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class BasePage:
def __init__(self, driver):
self.driver = driver
def send_keys(self, locator, value):
element = self.find_element(locator)
element.clear()
element.send_keys(value)
def click(self, locator):
element = self.find_element(locator)
element.click()
def find_element(self, locator, timeout=10):
return WebDriverWait(self.driver, timeout).until(EC.presence_of_element_located(locator)
配置和数据层( Configuration and Data)
-
职责:这一层主要负责存储项目的配置信息和测试数据。通过将配置和数据与代码分离,可以在不同环境下轻松切换配置。
-
主要内容
-
配置文件(如
config.json,.ini,yaml) -
测试数据文件(如 Excel, CSV, JSON)
-
示例:
{
"base_url": "http://example.com",
"browser": "chrome"
}
日志和报告层(Logging and Reporting)
-
职责:这一层负责记录测试运行过程中的日志信息,并生成测试报告。日志可以帮助调试和跟踪问题,测试报告提供测试结果的总结。
-
主要内容
-
日志记录(Loggers)
-
测试报告生成(Allure, HTML Test Report 等)
-
示例:
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def log_message(message):
logger.info(message)
工具层(Utility Layer)
-
职责:提供项目中一些常用的工具方法,例如处理文件、读取配置、生成随机数据等。这个层级的工具方法可以被项目中的其他层复用。
-
主要内容
-
文件处理
-
数据生成
-
时间操作等工具方法
-
示例:
import random
import string
def random_string(length=8):
return ''.join(random.choices(string.ascii_letters + string.digits, k=length))
编写登录测试用例,在执行该类前实现执行setup_class函数初始化浏览器驱动,执行测试用例结束后执行teardown_class函数关闭浏览器驱动
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestLogin:
def setup_class(self):
"""初始化Chrome浏览器驱动"""
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--incognito") # 启用隐私模式
self.driver = webdriver.Chrome(options=chrome_options)
self.driver.maximize_window()
self.driver.implicitly_wait(20)
def teardown_class(self):
"""关闭浏览器驱动"""
self.driver.quit()
def test_shopping_mail_001(self):
# 登录网易163浏览器
self.driver.get('https://mail.163.com/')
# 转换到登录的iframe内
self.driver.switch_to.frame(
self.driver.find_element(By.XPATH, '//*[@id="loginDiv"]/iframe')) # frame_reference为frame标签的特征
# 输入账户
self.driver.find_element(By.XPATH, '//*[@placeholder="邮箱账号或手机号码"]').send_keys("qwx13057573527")
# 输入密码
self.driver.find_element(By.XPATH, '//*[@placeholder="输入密码"]').send_keys("qwx#125617")
# 点击登录确定
self.driver.find_element(By.XPATH, '//*[@id="dologin"]').click()
# 切换到主body
self.driver.switch_to.default_content()
text = self.driver.find_element(By.XPATH, '//*[@id="spnUid"]').text
assert text == "qwx13057573527@163.com"
现在我想再额外验证用户名错误和密码错误两种情况,需要额外写两个case
def test_shopping_mail_001(self):
# 登录网易163浏览器
self.driver.get('https://mail.163.com/')
# 转换到登录的iframe内
self.driver.switch_to.frame(
self.driver.find_element(By.XPATH, '//*[@id="loginDiv"]/iframe')) # frame_reference为frame标签的特征
# 输入账户
self.driver.find_element(By.XPATH, '//*[@placeholder="邮箱账号或手机号码"]').send_keys("qwx13057573527")
# 输入密码
self.driver.find_element(By.XPATH, '//*[@placeholder="输入密码"]').send_keys("qwx#125617")
# 点击登录确定
self.driver.find_element(By.XPATH, '//*[@id="dologin"]').click()
# 切换到主body
self.driver.switch_to.default_content()
text = self.driver.find_element(By.XPATH, '//*[@id="spnUid"]').text
assert text == "qwx13057573527@163.com"
def test_shopping_mail_002(self):
# 登录网易163浏览器
self.driver.get('https://mail.163.com/')
# 转换到登录的iframe内
self.driver.switch_to.frame(
self.driver.find_element(By.XPATH, '//*[@id="loginDiv"]/iframe')) # frame_reference为frame标签的特征
# 输入账户
self.driver.find_element(By.XPATH, '//*[@placeholder="邮箱账号或手机号码"]').send_keys("qwx")
# 输入密码
self.driver.find_element(By.XPATH, '//*[@placeholder="输入密码"]').send_keys("qwx#125617")
# 点击登录确定
self.driver.find_element(By.XPATH, '//*[@id="dologin"]').click()
# 切换到主body
self.driver.switch_to.default_content()
text = self.driver.find_element(By.XPATH, '//*[@id="spnUid"]').text
assert text == "qwx13057573527@163.com"
def test_shopping_mail_003(self):
# 登录网易163浏览器
self.driver.get('https://mail.163.com/')
# 转换到登录的iframe内
self.driver.switch_to.frame(
self.driver.find_element(By.XPATH, '//*[@id="loginDiv"]/iframe')) # frame_reference为frame标签的特征
# 输入账户
self.driver.find_element(By.XPATH, '//*[@placeholder="邮箱账号或手机号码"]').send_keys("qwx13057573527")
# 输入密码
self.driver.find_element(By.XPATH, '//*[@placeholder="输入密码"]').send_keys("qwx")
# 点击登录确定
self.driver.find_element(By.XPATH, '//*[@id="dologin"]').click()
# 切换到主body
self.driver.switch_to.default_content()
text = self.driver.find_element(By.XPATH, '//*[@id="spnUid"]').text
assert text == "qwx13057573527@163.com"
我们发现以上三个case只有用户名和密码输入的数据不一样,逻辑都是一样的,我们可以将三组测试数据参数化传给一个测试代码即可,并根据不同的测试结果执行对应的逻辑
import pytest
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestLogin:
def setup_class(self):
"""初始化Chrome浏览器驱动"""
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--incognito") # 启用隐私模式
self.driver = webdriver.Chrome(options=chrome_options)
self.driver.maximize_window()
self.driver.implicitly_wait(20)
def teardown_class(self):
"""关闭浏览器驱动"""
self.driver.quit()
@pytest.mark.parametrize('username,password,result', [('qwx13057573527', 'qwx#125617', 'qwx13057573527@163.com'),
('qwx', 'qwx#125617', '账号或密码错误'),
('qwx13057573527', 'qwx', '账号或密码错误')],
ids=('test_shopping_mail_001', 'test_shopping_mail_002', 'test_shopping_mail_003'))
def test_shopping_mail_001(self, username, password, result):
# 登录网易163浏览器
self.driver.get('https://mail.163.com/')
# 转换到登录的iframe内
self.driver.switch_to.frame(
self.driver.find_element(By.XPATH, '//*[@id="loginDiv"]/iframe')) # frame_reference为frame标签的特征
# 输入账户
self.driver.find_element(By.XPATH, '//*[@placeholder="邮箱账号或手机号码"]').clear()
self.driver.find_element(By.XPATH, '//*[@placeholder="邮箱账号或手机号码"]').send_keys(username)
# 输入密码
self.driver.find_element(By.XPATH, '//*[@placeholder="输入密码"]').clear()
self.driver.find_element(By.XPATH, '//*[@placeholder="输入密码"]').send_keys(password)
# 点击登录确定
self.driver.find_element(By.XPATH, '//*[@id="dologin"]').click()
if result in 'qwx13057573527@163.com':
# 切换到主body
self.driver.switch_to.default_content()
# 断言测试结果
text = self.driver.find_element(By.XPATH, '//*[@id="spnUid"]').text
assert text == result
# 退出当前账号
self.driver.find_element(By.XPATH, '//*[@id="spnUid"]').click()
self.driver.find_element(By.XPATH, '//*[text()="退出登录"]').click()
else:
# 获取"账号或密码错误"的字眼
text = self.driver.find_element(By.XPATH, '//*[@class="ferrorhead"]').text
assert text == result
@pytest.mark.parametrize 传入的测试数据是元组或者元组列表,将测试数据通过username, password, result参数的形式传递到测试用例方法内
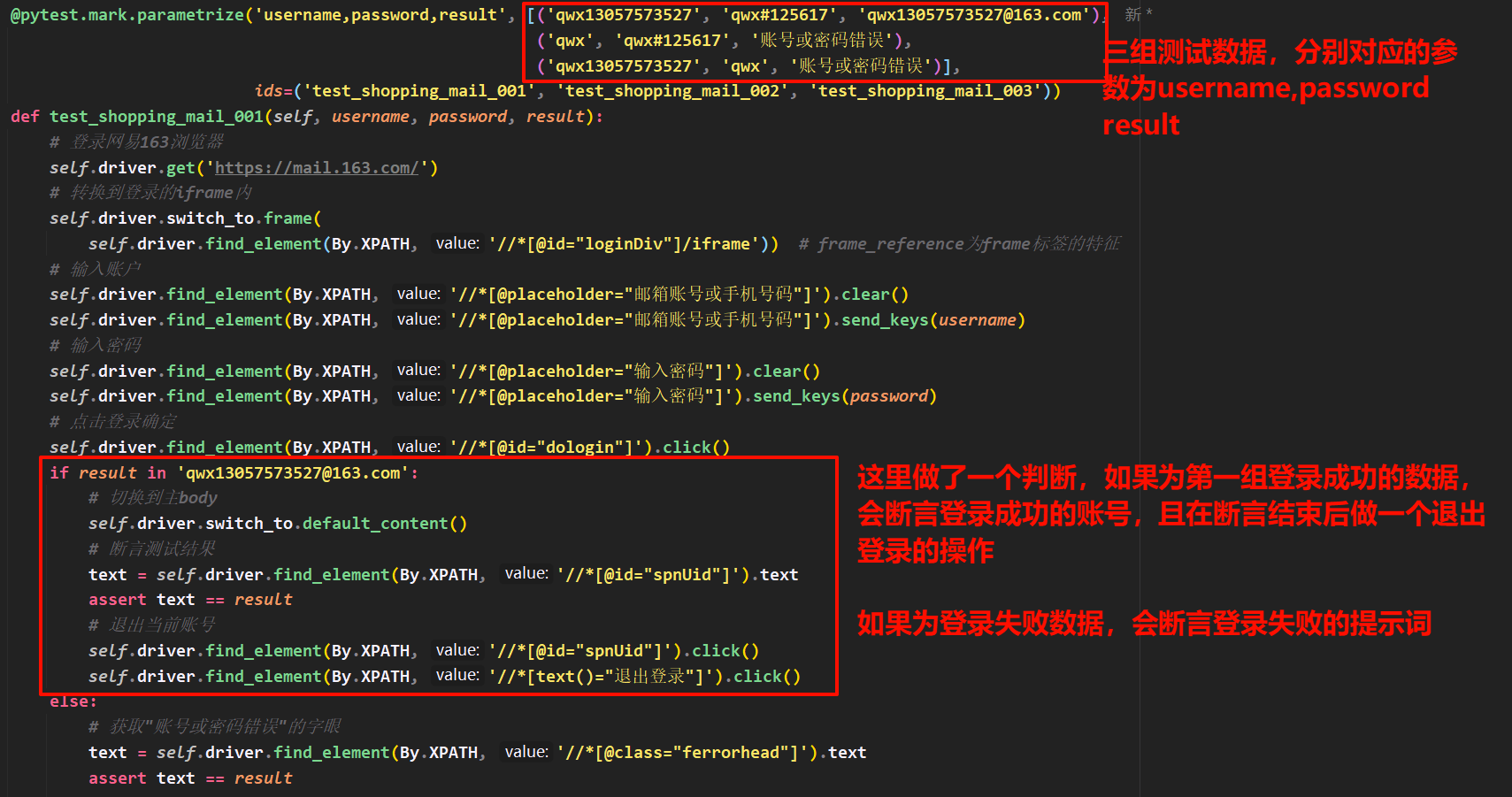
这里@pytest.mark.parametrize 传入的ids参数表示2测试数据对应的名称















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









