







原因
Java中的Scanner效率低下,据说是因为其一个字节一个字节的读导致的。
解决
使用StringTokenizer来解决读取效率低下的问题。
代码(不是我自己写的代码)
/** Class for buffered reading int and double values */
class Reader {
static BufferedReader reader;
static StringTokenizer tokenizer;
/** call this method to initialize reader for InputStream */
static void init(InputStream input) {
reader = new BufferedReader(
new InputStreamReader(input) );
tokenizer = new StringTokenizer("");
}
/** get next word */
static String next() throws IOException {
while ( ! tokenizer.hasMoreTokens() ) {
//TODO add check for eof if necessary
tokenizer = new StringTokenizer(
reader.readLine() );
}
return tokenizer.nextToken();
}
static int nextInt() throws IOException {
return Integer.parseInt( next() );
}
static double nextDouble() throws IOException {
return Double.parseDouble( next() );
}
}对比

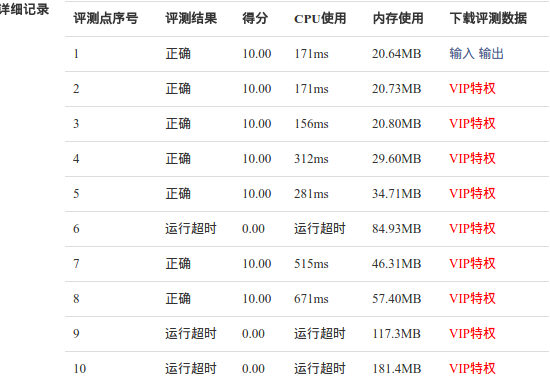
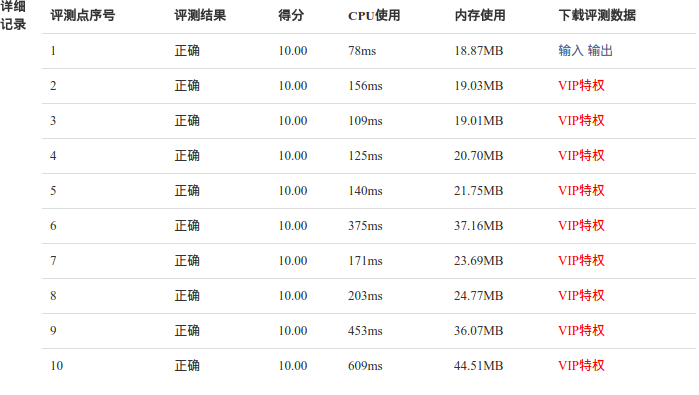
END
可以看到时间明显变少,效率得到提高!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









