







| 序号 | 软件名称 | 版本号 | 如何搭建 |
| 1 | hadoop | hadoop-3.2.1 | 见下文 |
| 2 | hbase | base-2.2.5 | |
| 3 | hive | apache-hive-3.1.2-bin | 链接 |
| 4 | spark | spark-3.0.0-preview2-bin-hadoop3.2 | |
| 5 | kylin | apache-kylin-2.6.6-bin-hadoop3 |
上面的组合我部署成功了。
单机安装hadoop
- 假设安装目录为:/opt/hadoop-3.2.1
- 配置环境变量,注意hadoop里面的命令在bin目录和sbin目录
export HADOOP_HOME=/opt/hadoop-3.2.1 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH -
使环境变量生效source /etc/profile - 下面分别配置core-site.xml,hdfs-site.xml,hadoop-env.sh和yarn-env.sh.
-
- 修改core-site.xml,修改后内容如下:
-
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> </configuration> -
修改hdfs-site.xml修改后内容如下:
-
<configuration> <!-- 配置文件备份数量 --> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/hadoop_namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/hadoop_datanode</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration> -
修改hadoop-env.sh和yarn-env.sh。分别增加指向java_home的配置。如下:
-
export JAVA_HOME=/usr/java/jdk1.8.0_241-amd64 -
创建目录,/opt/hadoop_datanode和/opt/hadoop_namenode。
-
mkdir /opt/hadoop_datanode mkdir /opt/hadoop_namenode
-
下面开始启动服务,注意hadoop的命令分别在bin目录和sbin目录。
-
到bin目录执行下列命令。
-
hdfs namenode -format
-
-
到sbin目录执行启动命令:
-
start-all.sh
-
-
到sbin目录执行关闭命令,关闭时使用。命令如下
-
stop-all.sh
-
-
其他命令:
-
start-dfs.sh start-yarn.sh start-balancer.sh start-secure-dns.sh
-
-
- 验证
- 方法1:输入下列命令,并出现后面的结果则证明启动正常
-
jps
-
- 方法1:输入下列命令,并出现后面的结果则证明启动正常
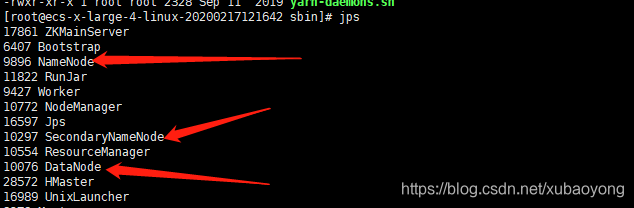
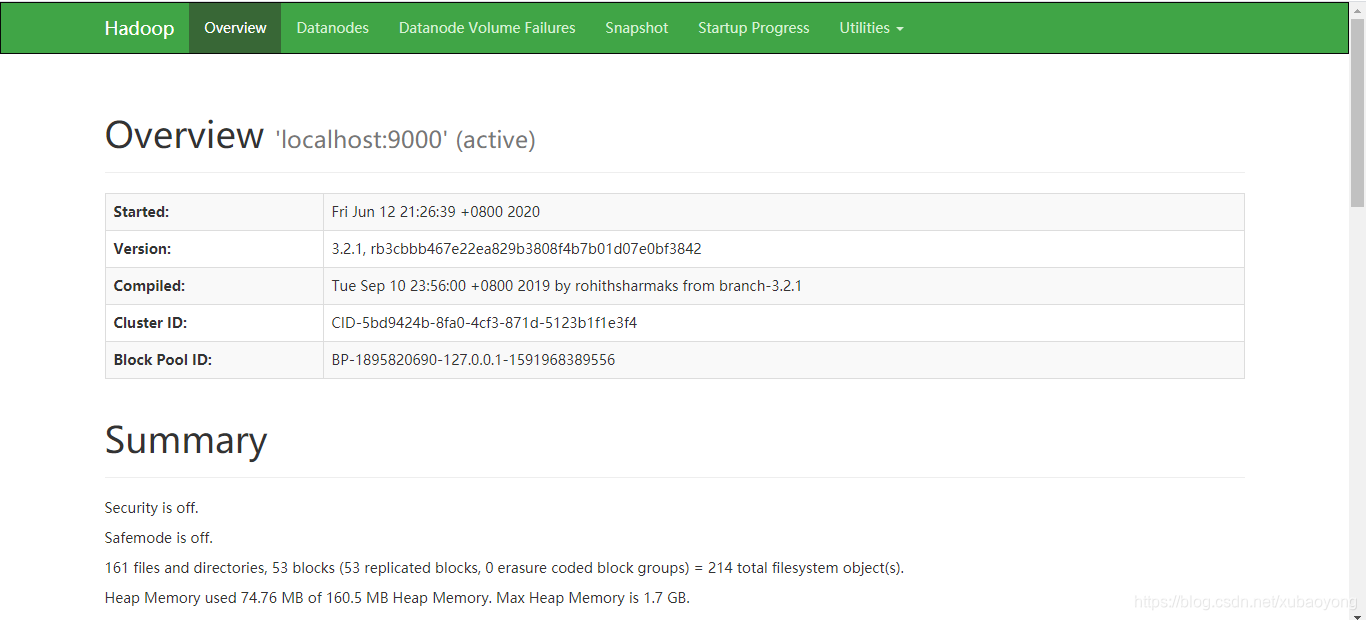
- 方法2:在浏览器中输入http://localhost:50070/。出现如下界面,证明成功。
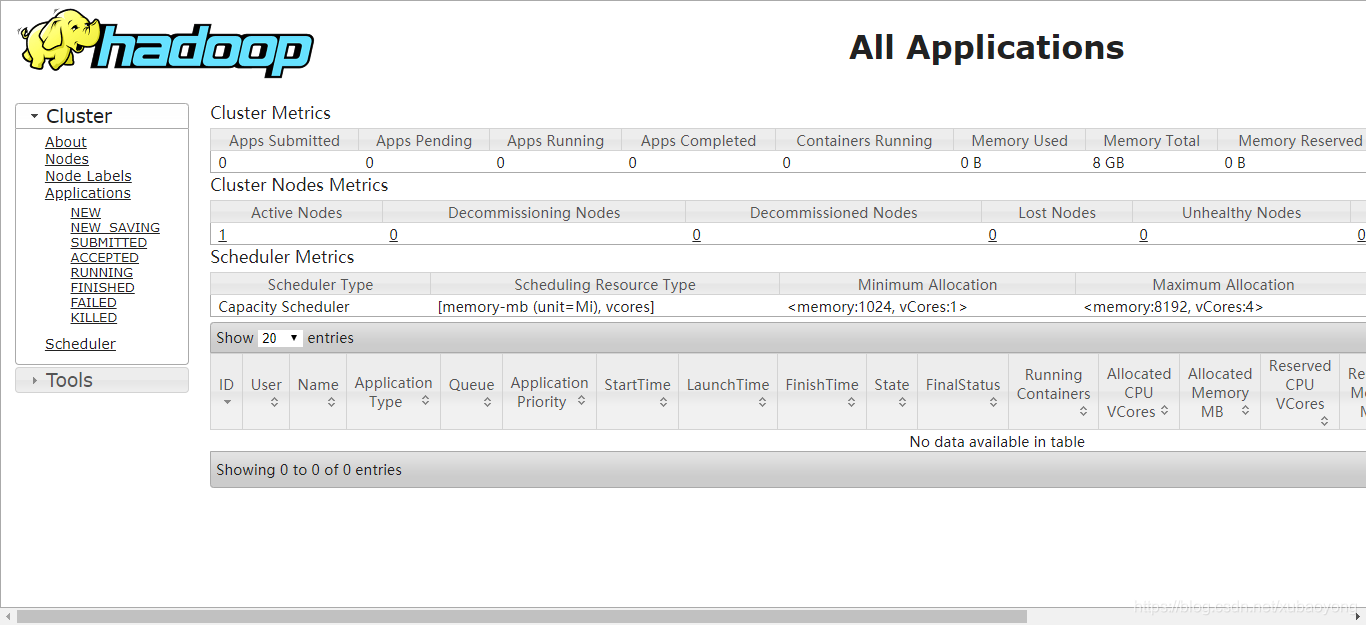
http://localhost:8088/出现如下界面
8 使用
8.1 创建HDFS
# hdfs dfs -mkdir /user
# hdfs dfs -mkdir /user/test
8.2 拷贝input文件到HDFS目录下
# hdfs dfs -put etc/hadoop /user/test/input
8.3 确认,查看
# hadoop fs -ls /user/test/input
8.4 执行Hadoop job
# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep /user/test/input output 'dfs[a-z.]+'
8.5 确认执行结果
# hdfs dfs -cat output/*
或者从HDFS拷贝到本地查看
# bin/hdfs dfs -get output output
# cat output/*
8.6 停止daemon
# sbin/stop-dfs.sh
8.7 执行YARN job
MapReduce V2框架叫YARN
8.7.1 修改设定文件
# cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
# vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
# vi etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
8.7.2 启动ResourceManger和NodeManager后台进程
# sbin/start-yarn.sh
8.8
8.8.1 执行hadoop job
# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep /user/test/input output 'dfs[a-z.]+'
8.8.2确认执行结果
# hdfs dfs -cat output/*
执行结果和MapReduce job相同
8.9 停止daemon
# sbin/stop-yarn.sh
9 单机部署主要是为了调试用,生产环境上一般是集群部署,接下来会进行介绍。















 597
597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









