









python爬取分析超级大乐透历史开奖数据
博主作为爬虫初学者,本次使用了requests和beautifulsoup库进行数据的爬取
爬取网站:http://datachart.500.com/dlt/history/history.shtml —500彩票网
(分析后发现网站源代码并非是通过页面跳转来查找不同的数据,故可通过F12查找network栏找到真正储存所有历史开奖结果的网页)
如图: 爬虫部分:
爬虫部分:
from bs4 import BeautifulSoup #引用BeautifulSoup库
import requests #引用requests
import os #os
import pandas as pd
import csv
import codecs
lst=[]
url='http://datachart.500.com/dlt/history/newinc/history.php?start=07001&end=21018'
r = requests.get(url)
r.encoding='utf-8'
text=r.text
soup = BeautifulSoup(text, "html.parser")
tbody=soup.find('tbody',id="tdata")
tr=tbody.find_all('tr')
td=tr[0].find_all('td')
for page in range(0,14016):
td=tr[page].find_all('td')
lst.append([td[0].text,td[1].text,td[2].text,td[3].text,td[4].text,td[5].text,td[6].text,td[7].text])
with open("Lottery_data.csv",'w') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['期号','号码1', '号码2', '号码3', '号码4', '号码5', '号码6', '号码7'])
writer.writerows(lst)
csvfile.close()
数据分析:
首先展示所有的彩票期号以及相应的中奖数字
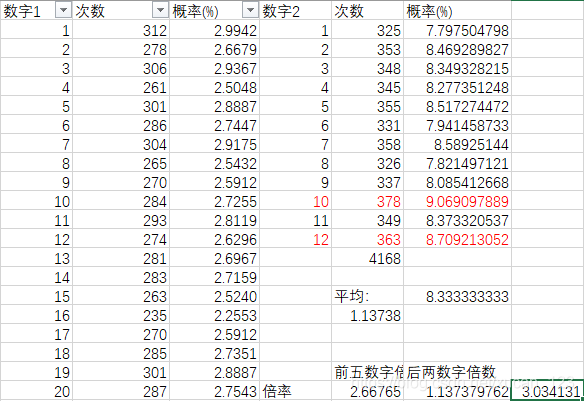
而后通过5+2的模式分别初步分析最高频次的两组数据组合,比较模糊的计算出了本组合中奖概率为平均中奖几率的3倍(最终结果不直接展示而是在csv文件中以红色标明)
源代码以及相应csv文件
链接:https://pan.baidu.com/s/16wEHnpvrzMsK1ijW0AkhiA
提取码:nmjx
tips:感谢大家的一键三连~另外,有不足之处大可向博主当面指出!!

















 1219
1219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









