






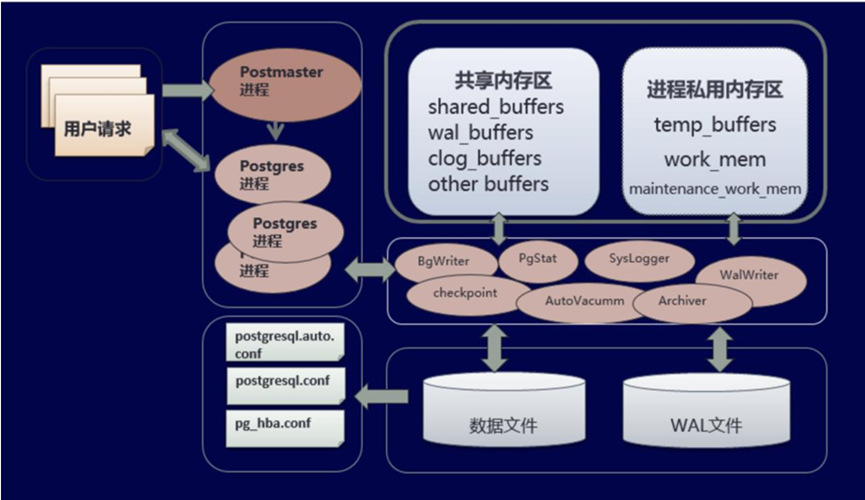
Postgresql体系架构-进程结构
PostgreSQL的进程结构是基于服务器进程和用户进程的。服务器进程负责管理数据库文件、接收用户进程的请求并执行SQL命令。用户进程则是客户端发起的与数据库交互的程序。
[postgres@pgserver01 ~]$ ps -ef | grep postgres

- 进程分类
PostgreSQL 数据库的进程可以分为三类: 后台进程、后端进程或叫服务器进程、客户端进程或用户进程。
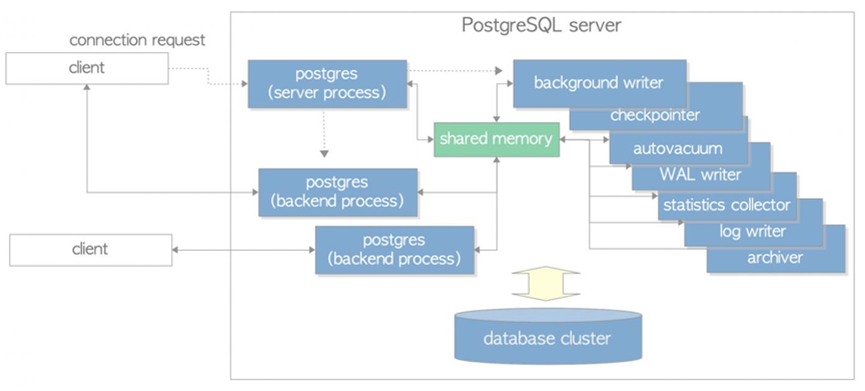
PG是关系型的数据库,是多进程架构,这张图显示了一个PostgreSQL服务器的进程:一个postgres服务 器进程,两个backend进程,七个background进程和两个客户端进程。还演示了数据库集群、共享内存 和两个客户机进程。
其中,$PGHOME/bin/postgres 是数据库服务器的master 进程,其它诸如checkpoint, background writer,walwrite,autovacuum launcher,stats collector,logical replication launcher 都是由它fork的子进程。
数据库运行模式不同,配置不同,也可能有其它后台进程,如归档进程等。
2. Postmaster进程
主进程Postmaster是整个数据库实例的总控制进程,负责启动和关闭数据库实例。postgres服务器进程是PostgreSQL 服务器中所有进程的父进程,该进程出现问题,整个cluster就over 了。用户可以运行postmaster,postgres命令加上合适的参数启动数据库。实际上,postmaster命令是一个指向postgres的链接。
pg_ctl也是通过运行postgres来启动数据库,它只是做了一些包装,让我们更容易启动数据库,所以,主进程Postmaster实际是第一个postgres进程,此进程会fork一些与数据库实例相关的辅助子进程,并管理他们。
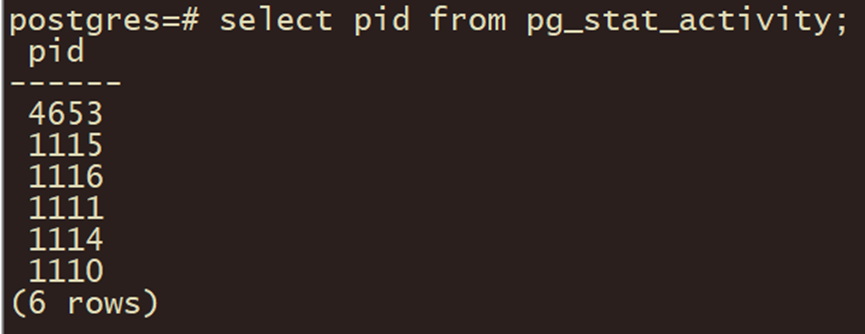
当用户与PostgreSQL数据库建立连接时,实际上是先与Postmaster进程建立连接。此时,客户端程序会发出身份证验证的消息给Postmaster进程,Postmaster主进程根据消息中的信息进行客户端身份验证。如果验证通过,它会fork一个子进程postgres为这个连接服务,fork出来的进程被称为服务进程,查询pg_stat_activity表可以看到的pid,就是这些服务进程的pid。
postgres=# select pid from pg_stat_activity;
3. backend 进程
backend 进程也称为postgres,由 postgres 服务器进程启动,并处理由一个连接的客户机发出的所有查询。它通过一个TCP连接与客户机通信,并在客户机断开连接时终止。因为它只允许 操作一个数据库,所以在连接到PostgreSQL服务器时,必须明确指定想要使用的数据库。允许多个客户端同时连接;配置参数max_connections控制客户机的最大数量(默认为100)。
如果许多客户端(如WEB应用程序)频繁地重复连接和断开与PostgreSQL服务器的连接,这会 增加建立连接和创建后端进程的成本,因为PostgreSQL没有实现本机连接池特性。这种情况 会对数据库服务器的性能产生负面影响。为了处理这种情况,通常使用池中间件(pgbouncer或 pgpool-II)。
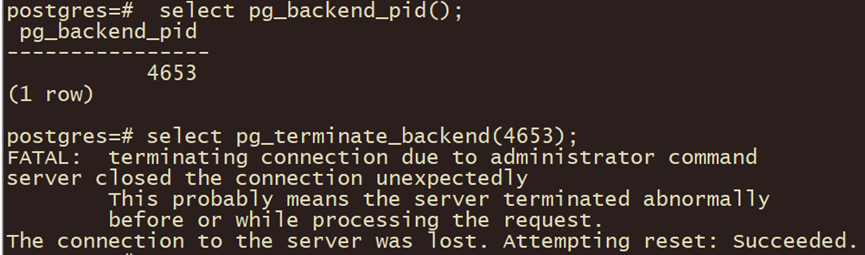
postgres=# select pg_backend_pid();
postgres=# select pg_terminate_backend(4653);
4. Background 进程
4.1 BgWriter后台写进程
BgWriter是进程是把共享内存中的脏页写到磁盘上的进程。它的作用有两个::
首先,数据库在进行查询处理时若发现要读取的数据不在缓冲区中时要先从磁盘中读入要读取的数据所在的页面,此时如果缓冲区已满,则需要先选择部分缓冲区中的页面替换出去。如果被替换的页面没有被修改过,那么可以直接丢弃;但如果要被替换的页已被修改,则必需先将这页写出到磁盘中后才能替换,这样数据库的查询处理就会被阻塞。通过使用BgWriter定期写出缓冲区中的部分脏页到磁盘中,为缓冲区腾出空间,就可以降低查询处理被阻塞的可能性。
其次,PostgreSQL在定期作检查点时需要把所有脏页写出到磁盘,通过BgWriter预先写出一些脏页,可以减少设置检查点时要进行的IO操作,使系统的IO负载趋向平稳。通过BgWriter对共享缓冲区写操作的统一管理,避免了其他服务进程在需要读入新的页面到共享缓冲区时,不得不将之前修改过的页面写出到磁盘的操作。
psql -c 'show all;' | grep bgwriter_
或者:
postgres=# select name,setting, reset_val from pg_settings where name like 'bgwriter%';

bgwriter_delay 连续两次写数据之间的时间间隔也就是每隔200毫秒,数据库会产生一个checkpoint触发后台写进程
bgwriter_flush_after 当检查点队列(内存中)的脏页/块达到了512kB时,触发后台写进程
bgwriter_lru_maxpages 每次写的最大数据量是多少
bgwriter_lru_multiplier 一个估算最近几次刷脏数据时的平均值因子
每次写入磁盘的数据块个数
4.2 WalWriter预写日志写进程
预写式日志 Write Ahead Log ,也称为Xlog,在修改数据之前把修改操作记录到磁盘中,以便后面更新实时数据时就不需要数据持久化到文件中。该进程定期将WAL缓冲区中的WAL数据写入并刷新到持久存储中。使用这种机制可以避免数据频繁的写入磁盘,可以减少磁盘I/O。数据库在宕机重启后可以运用这些 WAL 日志来恢复数据库。
4.3. Checkpointer
检查点进程,负责完成数据库的检查点,通知数据库的写进程 DBWR将内存中的脏数据写出到磁盘。

4.4 PgArch归档进程
WAL日志会被循环使用,archiver在归档前会把WAL日志备份出来。通过PITY ( Pointin Time Recovery )技术,可以对数据库进行一次全量备份后,该技术将备份时间点之后的WAL日志 通过归档进行备份,使用数据库的全量备份再加上后面产生的WAL日志,即可把数据库向前 推到全量备份后的任意一个时间点。
在默认情况下,PostgreSQL是非归档模式。
postgres=# show archive_mode;
postgres=# select * from pg_ls_waldir();
4.5 SysLogger进程
在postgresql.conf里启用 运行日志(pg_log)后,会有SysLogger进程。SysLogger会在日志文件达到指定的大小时关闭当前日志文件,产生新的日志文件。
配置文件中去配置 more $PGDATA/postgresql.conf
log_destination = 'stderr' # 配置日志输出目标,根据不同的运行平台会设置不同的值,Linux下默认为 stderr.。 推荐使用csvlog
logging_collector = on # 是否开启日志收集器,当设置为on时启动日志功能;否则,系统将不产生系统日志辅助进程
log_directory = 'pg_log' #配置日志输出目录
log_filename = 'postgresql-%a.log' # 配置日志文件名称命名规则。
log_rotation_size = 10MB # 保留单个文件的最大尺寸,默认是10M
log_truncate_on_rotation = on # 当设置为ON时,日志文件会在基于时间的旋转时覆盖现有文件的内容。当设置为OFF时,日志消息会追加到现有的日志文件中,不会覆盖旧的内容。这种方式适用于需要保留所有日志记录的情况。
4.6. AutoVacuum自动清理进程
自动清理工作进程。由于PostgreSQL不像Oracle那样有undo的机制,将数据被修改前的信息 写入到undo,然后修改数据。PostgreSQL采取的是在原数据块上进行保留旧的数据,并作标记,等到将来修改提交生效之后,旧的数据(dead tuple翻译为死元组)不需要的话,就得清理, 由该进程来完成。
在PostgreSQL中,被删除或者被更新的元组并没有在物理上从它们的表中移除,它们将一直 存在,直到一次 VACUUM 被执行。因此有必要周期性地做 VACUUM,特别是在频繁被更新的表上。
4.6.1. VACUUM作用
(1) 恢复或重用被已更新或已删除行所占用的磁盘空间。
(2)更新被PostgreSQL查询规划器使用的数据统计信息。
(3) 更新可见性映射,它可以加速只用索引的扫描。
(4)保护老旧数据不会由于事务ID回卷或多事务ID回卷而丢失。
VACUUM 的标准形式可以和生产数据库的操作并行运行。像 SELECT, INSERT, UPDATE, 和 DELETE 将照常运行。
4.6.2 VACUUM的形式
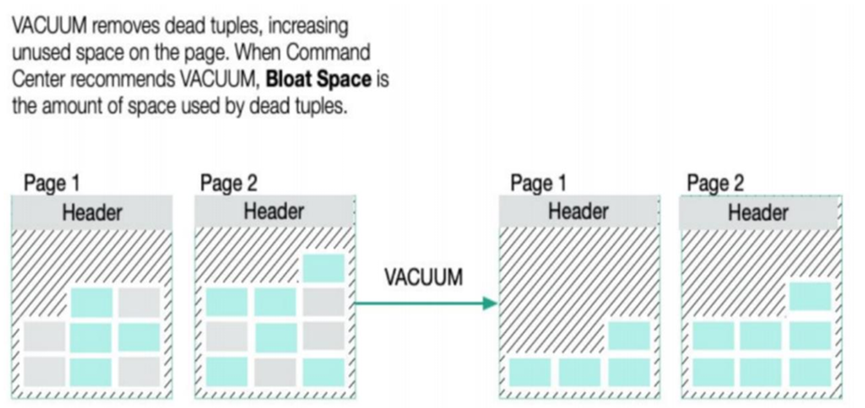
(1)VACUUM
– 对表和索引中没用数据(dead data)做一个标记,以便将来使用。
– VACUUM它不会试图去回收没用的数据(dead data)所占的空间,除非这些没用的空间在表 – 的末尾并且非常容易获得表上的排它锁。
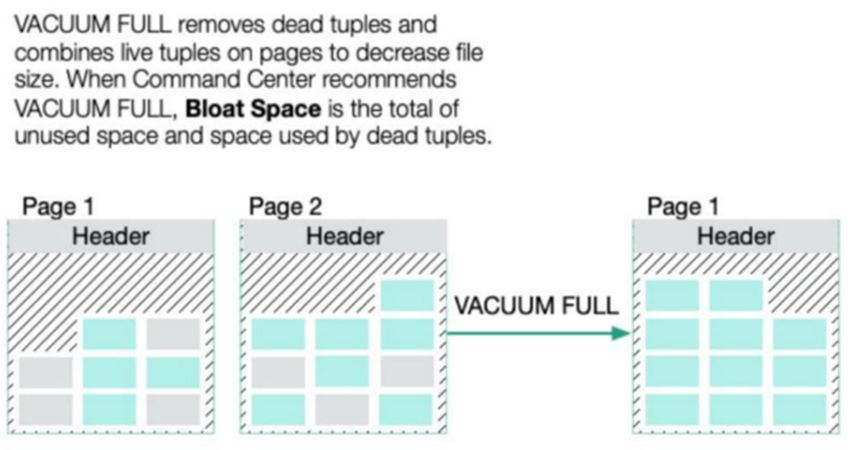
(2)VACUUM FULL
VACUUM FULL 采用了一种更积极的算法来回收没用的数据。
– 被VACUUM FULL释放的空间将立即返回给操作系统。
– 在VACUUM FULL执行的时候,需要对所操作的表加一个排它锁。
语法: VACUUM [ FULL | FREEZE ] [ VERBOSE ] ANALYZE [ table [ (column [, ...] ) ] ]
4.6.3. AutoVacuum 自动清理
对于大型PostgreSQL数据库来说,AUTOVACUUM时必须的,而且优化好AUTOVACUUM。
对于大型PostgreSQL数据库来说至关重要。那么该如何来优化AUTOAVCUUM呢?
要考虑的是三个基本的参数autovacuum_max_workers、maintenance_work_mem、 autovacuum_freeze_max_age,这三个参数设置的合理,大部分AUTOVACUUM的问题都得到了解决。
(1)autovacuum_max_workers 指定了autovacuum使用的工作进程的数量,最先设置为CPU_COUNT的1/2
(2)maintenance_work_mem 建议maintenance_work_mem 至少设置为 1 GB,1GB的维护工作内存足以一次处理大约1.79亿 个死元组.
(3)autovacuum_freeze_max_age 合理设置此参数可以减少TXID回绕的机会,Max age越大,autovacuum运行的频率就越低。
SELECT
name,
setting
FROM pg_settings
WHERE name like '%vacuum%'
;
Select
relname,
n_live_tup,
n_dead_tup
from pg_stat_user_tables
;
SELECT
relname,
n_tup_ins,
n_tup_upd,
n_tup_del
FROM pg_stat_all_tables
ORDER BY n_dead_tup DESC
LIMIT 20
;
autovacuum_naptime:60s,指的是每两次autovacuum之间要seep多长时间,意味着要idle 60秒的时间。
autovacuum_vacuum scale factor: 在vacuum执行之前,更新或删除的元组的数量在总的元组数量中的百分比.
autovacuum_vacuum_threshold:vacuum之前,update或者delete的元组的绝对数量
当满足下边的条件的时候,autovacuum会被自动触发: n_dead_tup>n_live_tup*autovacuum_vacuum_scale_factor + autovacuum_vacuum_threshold
4.6.4. 辅助进程
为了实现自动清理,PostgreSQL引入了两种类型的辅助进程
autovacuum launcher
autovacuum worker
autovacuum launcher 进程可以理解为 AutoVacuum机制的守护进程,周期性地调度autovacuum worker 进程。
因为AutoVacuum依赖于统计信息,所以只有track_counts=on 且autovacuum=on 时, PostgreSQL 才启动 autovacuum launcher 进程。
4.7. PgStat统计信息收集进程
PgStat进程是PostgreSQL数据库的统计信息收集器,用来收集数据库运行期间的统计信息,,如表、index有多少条记录,数据分布等等。收集统计信息主要是为了让优化器做出正确的判断,选择最佳的执行计划。
postgresql.conf文件中与PgStat进程相关的参数:

4.8. logical replication launcher
逻辑复制进程。用于完成逻辑复制的工作。其主要职责包括:
(1)启动逻辑复制工作者进程:Logical Replication Launcher会启动逻辑复制工作者进程,这些工作者进程实际执行复制任务,每个工作者对应一个订阅。它在数据库服务器启动时就会启动,并且每当检测到有新的订阅或需要维护现有订阅时,就会启动新的工作者进程。
(2)监控工作者进程:它持续监控工作者进程的状态,如果有工作者进程意外退出或失败,它会尝试重新启动新的工作者进程来替代它们。
(3)协调逻辑复制流程:确保在逻辑复制的整个过程中,所有必要的步骤和进程都能够顺利进行,监控并管理逻辑复制相关的资源1。
配置和管理Logical Replication Launcher的一些重要参数包括:
- max_replication_slots:最大的逻辑或物理复制插槽数。复制槽用于跟踪哪些事务的更改需要保留以供复制。
- max_worker_processes:定义了允许启动的最大工作者进程数量。要使用逻辑复制,必须确保该值足够大,以容纳所有需要的工作者进程1。
- max_logical_replication_workers:专门用于逻辑复制工作者的最大进程数。
- max_sync_workers_per_subscription:每个订阅允许的最大同步工作者数量,影响数据同步的并发水平
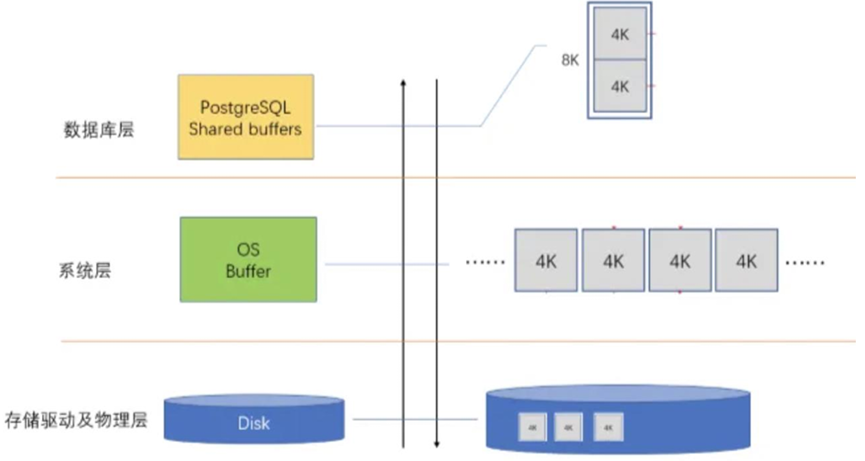
4.9。 双缓存
PostgreSQL 数据库使用双缓存写数据,shared_buffer + OS page cache,下图是 PG 与OS 内存交 互的过程。

















 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









