







MySQL CTE
自mysql8.0+(MariaDB11.0+)以来,就支持了递归查询的CTE功能。这个功能极大的便利了树状结构在sql中的查询。
CTE是什么?
CTE是Common Table Expression的缩写。意为公用表表达式。用程序员的角度看,就是个临时表,只是这个临时表是内存中的表,不真实存储,有点像view视图,只是一次性的,查完就消失。
旧版的sql只能自关联查询,而且查询出的结果也没法按树深排序,一般的做法是数据全部遍历出来,在应用的内存中关联排序,或者在前端显示的树形组件中关联排序。
而CTE的出现,大大提高了SQL复杂查询的效率,也提升了sql可读性。而且还能解决树形查询问题,利用临时表的特性,不断对数据递归查询,从而得到结果集,省去了手动写sql或存储过程的问题。
递归陷阱
递归最怕的就是无限循环(俗称:死循环)导致内存溢出或崩溃的问题,所以我们在做树形数据时,关联的id要做得标准,避免出现无限循环。
而这篇文章的标题《警惕列长度陷阱!!!》又和递归陷阱有什么关系呢?
警惕列长度陷阱!!!
列长度并不是无限的,在设计递归列时要计算好数据的最大长度。
这个问题会出现在递归时的累加列中。为了更直观的感受,给大家看实际的代码示例:
首先创建一个树形表,并创建几条树形数据。博主的数据库是10.6.7-MariaDB(maria看起来和mysql很像,但终归是两个东西。而且,事实上mysql的处理也确实比maria好些,等会看下面的对比就能发现区别)
CREATE TABLE `t_tree` (
`id` varchar(64) NOT NULL,
`parent_id` varchar(64) DEFAULT NULL COMMENT '父级编号',
`name` varchar(10) DEFAULT NULL COMMENT '名称',
`sort` decimal(10,0) NOT NULL COMMENT '排序',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 COMMENT='树形表';
INSERT INTO `t_tree` (`id`, `parent_id`, `name`, `sort`) VALUES ('1', NULL, 'root', '0');
INSERT INTO `t_tree` (`id`, `parent_id`, `name`, `sort`) VALUES ('2', '1', 'n1', '0');
INSERT INTO `t_tree` (`id`, `parent_id`, `name`, `sort`) VALUES ('3', '1', 'n2', '10');
INSERT INTO `t_tree` (`id`, `parent_id`, `name`, `sort`) VALUES ('4', '2', 'n1-c1', '0');
INSERT INTO `t_tree` (`id`, `parent_id`, `name`, `sort`) VALUES ('5', '2', 'n1-c2', '10');
INSERT INTO `t_tree` (`id`, `parent_id`, `name`, `sort`) VALUES ('6', '3', 'n2-c3', '0');
INSERT INTO `t_tree` (`id`, `parent_id`, `name`, `sort`) VALUES ('7', '3', 'n2-c4', '10');
INSERT INTO `t_tree` (`id`, `parent_id`, `name`, `sort`) VALUES ('8', '4', 'n1-c1-l1', '0');
INSERT INTO `t_tree` (`id`, `parent_id`, `name`, `sort`) VALUES ('9', '4', 'n1-c1-l2', '10');
这是一个典型的树形结构,4级树深。
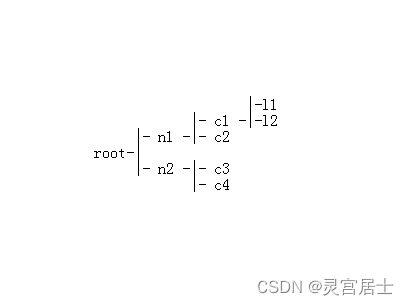
需求:查询出全部的树形并按sort排序
下面来用mysql的CTE递归语法查询数据,先来看错误的:
WITH recursive cte AS (
SELECT
CONCAT(s.sort) AS sk,
s.*
FROM
t_tree s
WHERE
s.id = '1'
UNION ALL
SELECT
CONCAT(cte.sk, ',', s.sort) AS sk,
s.*
FROM
t_tree s
INNER JOIN cte ON s.parent_id = cte.id
) SELECT
*
FROM
cte
ORDER BY
sk
查询结果:
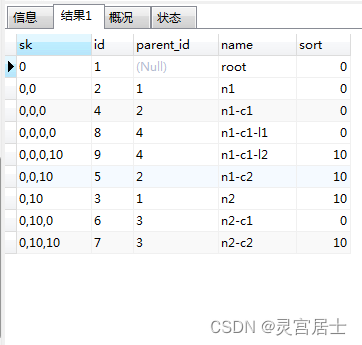
是不是看起来很完美?no,no,no!你被这个假数据骗了!!!下面我们把sk排序列的连接符改成【—>】再看看
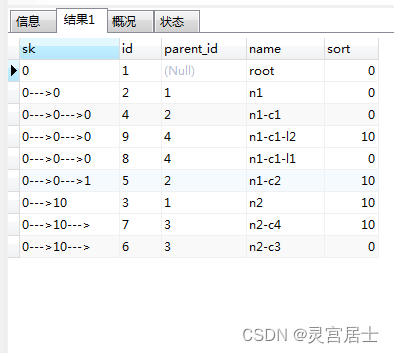
what?我们的sk字段咋变成这样了?但这只是maria中的,mysq(博主的mysql版本是8.0.23)是这样的:
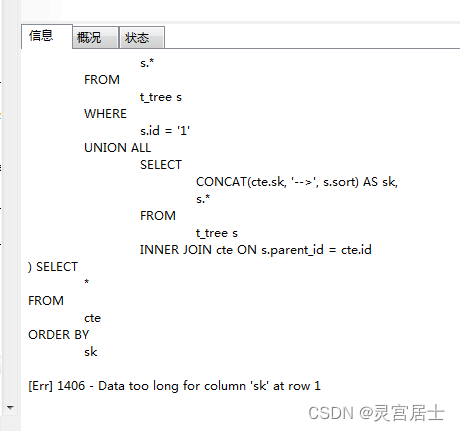
看Err就知道问题出在哪里了吧?sk居然长度不够?sk明明是我们concat转换出来的一个列啊,怎么会有长度限制呢??
事实胜于雄辩,结果就摆在这里!的确,在普通的sql中,确实没这个问题。就算你用union all,也不会有这个问题。只有用了CTE的才会有这个问题!我没有研究mysql和maria的源码,不知道这算不算是一个BUG。但知道了问题,就有了解决方案:
cte根据第一个sql确定列大小的,把我们的第一个sql的sk列设一个固定的,够用的长度,问题就会解决了。
于是,把sk列设置成100长度(sort长度是10,连接符长度是3,4层树深=(10+3)*4 = 52,这回肯定是够用了),sql改成了这样,:
WITH recursive cte AS (
SELECT
cast(s.sort as char(100)) AS sk,
s.*
FROM
t_tree s
WHERE
s.id = '1'
UNION ALL
SELECT
CONCAT(cte.sk, '-->', s.sort) AS sk,
s.*
FROM
t_tree s
INNER JOIN cte ON s.parent_id = cte.id
) SELECT
*
FROM
cte
ORDER BY
sk
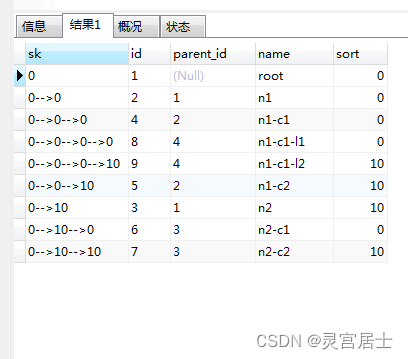
和设想的一致,结果也变得正确了。所以,在做这种CTE递归累加的列时,一定要提前计算数据的最大长度,避免由于长度不够导致的BUG。
总结
没有任何一种技术能真正的支持无限层级,总是有理论上和实际上的最大值。就算软件上可以写出支持无限的程序,但事实上硬件还是不能无限扩展。而且查询效率也会随着数据的增大而增加。所以我们一般在设计系统的树形结构时,要尽量避免数据无限层级的行为,最保底也要设有上限,这样才能计算出最大长度,避免由于无法计算数据最终长度而导致出现BUG。

















 1959
1959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









