







前言
本文主要采取cookie登录的方式爬取企查查网站的公司的基本信息,后期会继续发布关于爬取企查查网站上的公司的裁判文书信息。链接为:企查查 本文中若存在不详细的地方欢迎各位大神网友提问,若有错误的地方,希望大家指正。谢谢!! ? ?
粗略分析
1.进入企查查网站首页,在输入框输入某公司的全名(现在用名或曾用名),点击搜索可以查询结果列表页。如下图所示:
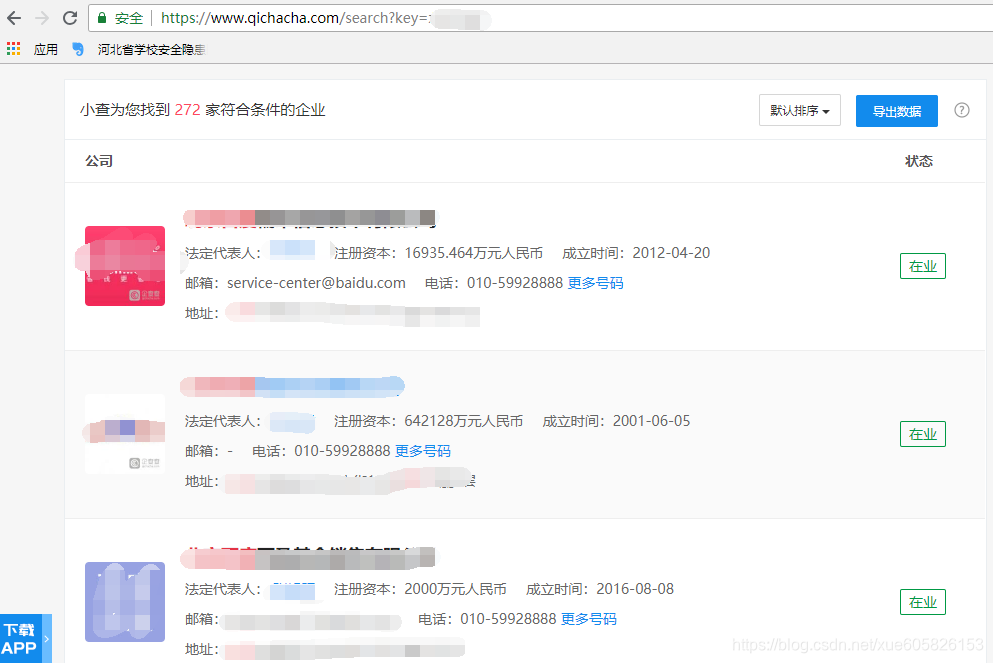
同时可以看到查询时的网页链接为https://www.qichacha.com/search?key=“公司名”。若给出公司全名,刚列表页中第一个即为我们要爬取的公司。写程序时可直接用xpath提取第一项的链接。
2.点击进入要爬取的公司可以看到该公司的具体信息。点击“基本信息”项,可以看到网页的链接变为https://www.qichacha.com/firm_此处为一串数字.html#base。可提取信息如下: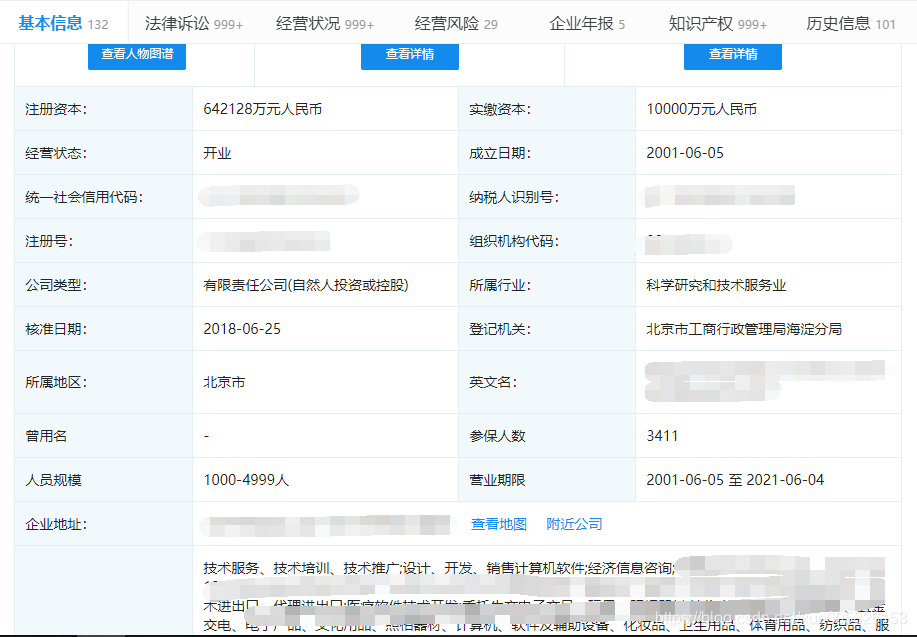
程序分析
1.items
class QichachaItem(scrapy.Item):
name = scrapy.Field()
phone = scrapy.Field()
website = scrapy.Field()
email = scrapy.Field()
address = scrapy.Field()
registered_capital = scrapy.Field() #注册资本
contributed_capital = scrapy.Field() #实缴资本
status = scrapy.Field() #经营状态
establishment = scrapy.Field() #成立日期
social_code = scrapy.Field() #统一社会信用代码
taxpayer_num = scrapy.Field() #纳税人识别号
registrate_num = scrapy.Field() #注册号
organization_code = scrapy.Field() #组织机构代码
company_type = scrapy.Field() #公司类型
industry_involed = scrapy.Field() #所属行业
approval_date = scrapy.Field() #核准日期
registration_authority = scrapy.Field() #登记机关
area = scrapy.Field() #所属地区
english_name = scrapy.Field() #英文名
used_name = scrapy.Field() #曾用名
insured_num = scrapy.Field() #参保人数
staff_size = scrapy.Field() #人员规模
operate_period = scrapy.Field() #营业期限
business_scope = scrapy.Field() #经营范围
2.spiders
码前分析
因为是查询一系列公司的信息,所以在程序中我把公司名称写入了txt文件,遍历查询,并通过cookie登录。最后写入MySQL数据库
代码
class QccSpider(scrapy.Spider):
name = 'qcc'
allowed_domains = ['qichacha.com']
start_urls = ['https://www.qichacha.com/search?key=']
x = 1
def start_requests(self):
#查询公司
f = open('G://task/qichacha/qichacha/spiders/company_list.txt','r',encoding='utf-8')
for link in f:
company = urllib.parse.quote(link).replace('\n','')
url = self.start_urls[0] + company
yield scrapy.Request(url,cookies=COOKIES,callback=self.parse)
def parse(self,response):
#提取列表中第一个公司,进入该页
link = response.xpath('//tbody/tr[1]/td[2]/a/@href').extract_first()
detail_link = response.urljoin(link) + '#base'
#print(detail_link)
yield scrapy.Request(detail_link,cookies=COOKIES,callback=self.page_parse)
def page_parse(self,response):
item = QichachaItem()
#公司名
name = response.xpath('//div[@class="content"]/div[1]/h1/text()').extract_first()
item['name'] = name.strip().replace('\n','') if name else '暂无公司名信息'
#电话
phone = response.xpath('//div[@class="content"]/div[2]/span[1]/span[2]/span/text()').extract_first()
item['phone'] = phone.strip().replace('\n','') if phone else '暂无电话信息'
#官网
website = response.xpath('//div[@class="content"]/div[2]/span[3]/a/@href').extract_first()
item['website'] = website.strip().replace('\n','') if website else '暂无网站信息'
#邮箱
email = response.xpath('//div[@class="content"]/div[3]/span[1]/span[2]/a/text()').extract_first()
if email:
item['email'] = email
else:
email2 = response.xpath('//div[@class="content"]/div[3]/span[1]/span[2]/text()').extract_first()
item['email'] = email2.strip().replace('\n','')
#地址
address = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[10]/td[2]/text()').extract_first()
item['address'] = address.strip().replace('\n','') if address else '暂无地址信息'
#注册资本
registered_capital = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[1]/td[2]/text()').extract_first()
item['registered_capital'] = registered_capital.replace('\n','').strip() if registered_capital else '暂无注册资本'
#实缴资本
contributed_capital = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[1]/td[4]/text()').extract_first()
if contributed_capital:
item['contributed_capital'] = contributed_capital.replace('\n','').strip()
else:
item['contributed_capital'] = '暂无实缴资本'
#经营状态
status = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[2]/td[2]/text()').extract_first()
if status:
item['status'] = status.replace('\n','').strip()
else:
item['status'] = '暂无经营状态信息'
#成立日期
establishment = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[2]/td[4]/text()').extract_first()
if establishment:
item['establishment'] = establishment.replace('\n','').strip()
else:
item['establishment'] = '暂无成立日期信息'
#统一社会信用代码
social_code = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[3]/td[2]/text()').extract_first()
if social_code:
item['social_code'] = social_code.replace('\n','').strip()
else:
item['social_code'] = '暂无统一社会信息代码信息'
#纳税人识别号
taxpayer_num = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[3]/td[4]/text()').extract_first()
if taxpayer_num:
item['taxpayer_num'] = taxpayer_num.replace('\n','').strip()
else:
item['taxpayer_num'] = '暂无纳税人识别号信息'
#注册号
registrate_num = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[4]/td[2]/text()').extract_first()
if registrate_num:
item['registrate_num'] = registrate_num.replace('\n','').strip()
else:
item['registrate_num'] = '暂无注册号信息'
#组织机构代码
organization_code = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[4]/td[4]/text()').extract_first()
if organization_code:
item['organization_code'] = organization_code.replace('\n','').strip()
else:
item['organization_code'] = '暂无组织机构代码信息'
#公司类型
company_type = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[5]/td[2]/text()').extract_first()
if company_type:
item['company_type'] = company_type.replace('\n','').strip()
else:
item['company_type'] = '暂无公司类型信息'
#所属行业
industry_involed = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[5]/td[4]/text()').extract_first()
if industry_involed:
item['industry_involed'] = industry_involed.replace('\n','').strip()
else:
item['industry_involed'] = '暂无所属行业信息'
#核准日期
approval_date = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[6]/td[2]/text()').extract_first()
if approval_date:
item['approval_date'] = approval_date.replace('\n','').strip()
else:
item['approval_date'] = '暂无核准日期信息'
#登记机关
registration_authority = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[6]/td[4]/text()').extract_first()
if registration_authority:
item['registration_authority'] = registration_authority.replace('\n','').strip()
else:
item['registration_authority'] = '暂无登记机关信息'
#所属地区
area = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[7]/td[2]/text()').extract_first()
if area:
item['area'] = area.replace('\n','').strip()
else:
item['area'] = '暂无所属地区信息'
#英文名
english_name = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[7]/td[4]/text()').extract_first()
if english_name:
item['english_name'] = english_name.replace('\n','').strip()
else:
item['english_name'] = '暂无英文名信息'
#曾用名
used = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[8]/td[2]')
used_name = used.xpath('string(.)').extract_first()
if used_name:
item['used_name'] = used_name.replace('\n','').strip().replace('\xa0','')
else:
item['used_name'] = '暂无曾用名'
#参保人数
insured_num = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[8]/td[4]/text()').extract_first()
if insured_num:
item['insured_num'] = insured_num.replace('\n','').strip()
else:
item['insured_num'] = '暂无参保人数信息'
#人员规模
staff_size = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[9]/td[2]/text()').extract_first()
if staff_size:
item['staff_size'] = staff_size.replace('\n','').strip()
else:
item['staff_size'] = '暂无人员规模信息'
#营业期限
operate_period = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[9]/td[4]/text()').extract_first()
if operate_period:
item['operate_period'] = operate_period.replace('\n','').strip()
else:
item['operate_period'] = '暂无营业期限信息'
#经营范围
business_scope = response.xpath('//section[@id="Cominfo"]/table[@class="ntable"][2]/tr[11]/td[2]/text()').extract_first()
if business_scope:
item['business_scope'] = business_scope.replace('\n','').strip()
else:
item['business_scope'] = '暂无经营范围信息'
yield item
- 其它
本程序将爬取信息写入了数据库,此处同settings一样,不再列出。
再次声明
若有错误及改进之处,望大家批评指正。















 1141
1141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









