







第七章 大模型实战 第1部分、评测+RAG检索增强生成
总目录
目录
第7章 大模型应用
在前面的章节中,我们系统性地介绍了大规模语言模型的基础理论知识、预训练方法以及各种微调技术。本章将深入探讨大模型在实际应用场景中的关键技术和实现框架,重点涵盖三个核心主题:大模型评测体系、RAG(检索增强生成)技术以及Agent(智能体)系统。
7.1 LLM的评测体系
近年来,随着人工智能技术的迅猛发展,大规模预训练语言模型(Large Language Models,简称LLM)已经成为推动整个AI领域技术进步的核心驱动力。这些大模型在自然语言处理、代码生成、多模态理解等诸多任务中展现出了令人惊叹的能力。然而,要准确、客观地衡量一个大模型的综合性能,必须依靠科学、合理、标准化的评测体系。
什么是大模型评测? 大模型评测是指通过一系列标准化的测试方法、基准数据集和评价指标,对大模型在不同类型任务上的表现进行量化分析和横向比较的过程。
为什么大模型评测如此重要?
- 性能验证:客观揭示模型在各种任务场景中的真实表现
- 弱点识别:暴露模型的潜在问题(偏见、鲁棒性等)
- 标准建立:提供统一的参考基准
- 决策支持:帮助选择合适的模型方案
7.1.1 评测数据集详解
通用评测集
MMLU(Massive Multitask Language Understanding)
MMLU是目前最具影响力的综合性评测集之一,包含57个不同学科领域的选择题,涵盖STEM、人文社科、社会科学等多个大类。
评测指标计算公式:
MMLU Score = ∑ i = 1 n 1 [ answer i = correct i ] n × 100 % \text{MMLU Score} = \frac{\sum_{i=1}^{n} \mathbb{1}[\text{answer}_i = \text{correct}_i]}{n} \times 100\% MMLU Score=n∑i=1n1[answeri=correcti]×100%
工具使用评测集
BFCL V2:用于评测模型在复杂工具使用任务中的表现。
数学评测集
GSM8K:包含8,500道小学数学应用题。
GSM8K评估代码实现:
import json
import re
def evaluate_gsm8k(model_answers, ground_truth):
"""
评估GSM8K数学推理任务的准确率
Args:
model_answers: 模型输出的答案列表
ground_truth: 标准答案列表
Returns:
accuracy: 准确率(百分比)
"""
correct = 0
total = len(ground_truth)
for model_ans, true_ans in zip(model_answers, ground_truth):
model_num = extract_number(model_ans)
true_num = extract_number(true_ans)
if model_num is not None and true_num is not None:
if abs(model_num - true_num) < 1e-5:
correct += 1
accuracy = (correct / total) * 100
return accuracy
def extract_number(text):
"""从文本中提取数值答案"""
pattern = r'[-+]?\d*\.?\d+'
matches = re.findall(pattern, text)
if matches:
return float(matches[-1])
return None
# 使用示例
model_answers = ["18个苹果", "答案是25", "结果为42.5"]
ground_truth = ["18", "25", "42.5"]
accuracy = evaluate_gsm8k(model_answers, ground_truth)
print(f"GSM8K准确率: {accuracy:.2f}%")
# 输出: GSM8K准确率: 100.00%
MATH:数学竞赛级问题集,涵盖代数、几何、数论等。
推理评测集
- ARC Challenge:科学推理任务
- GPQA:研究生级防搜索问答
- HellaSwag:复杂语境理解
长文本理解评测集
- InfiniteBench/En.MC:长篇科学文献理解
- NIH/Multi-needle:多样本长文档检索
多语言评测集
MGSM:GSM8K的多语言扩展版本。
7.1.2 主流评测榜单
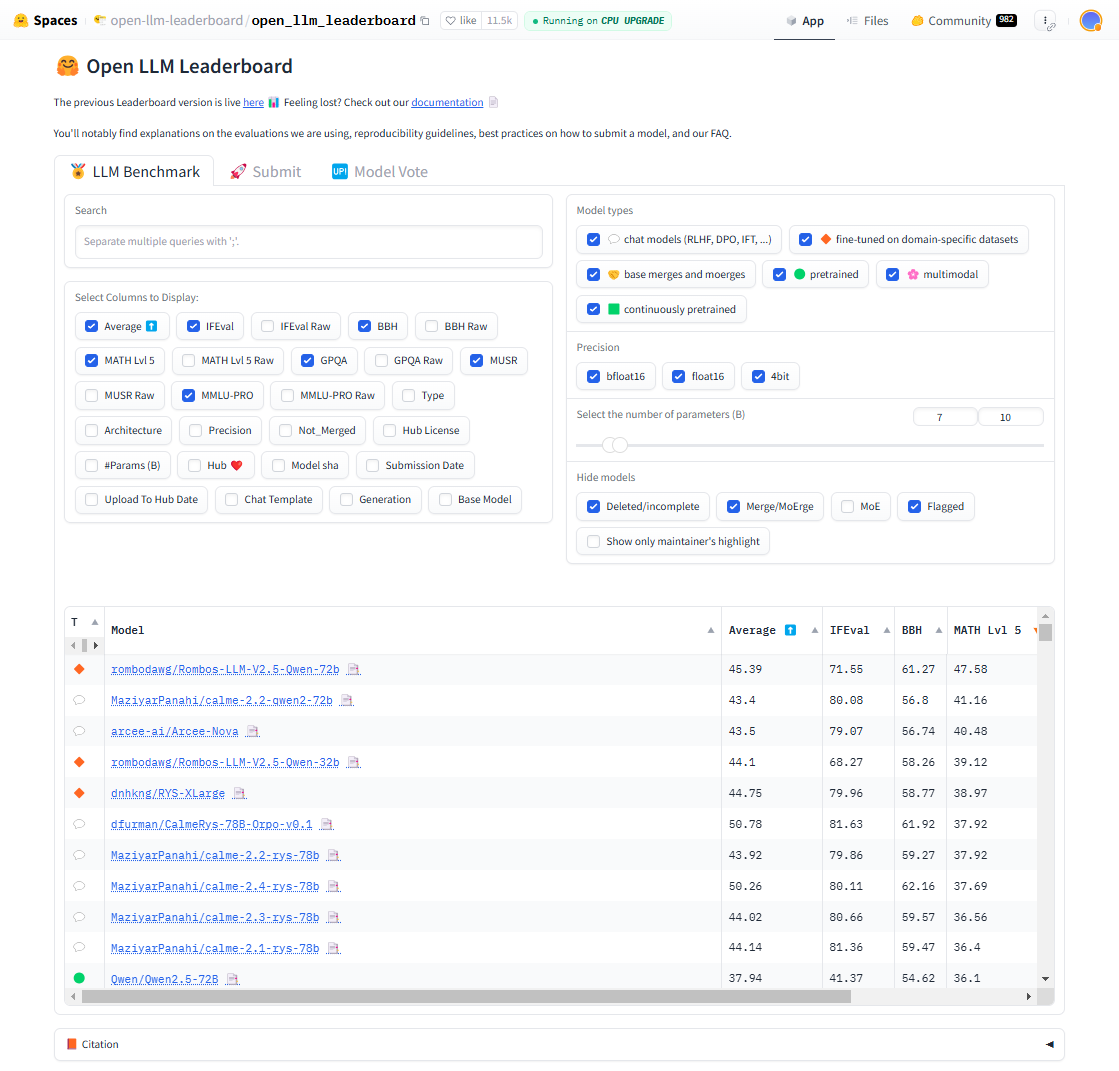
Open LLM Leaderboard
由Hugging Face提供的开放式评测榜单,汇集全球多个开源大模型的评测结果。
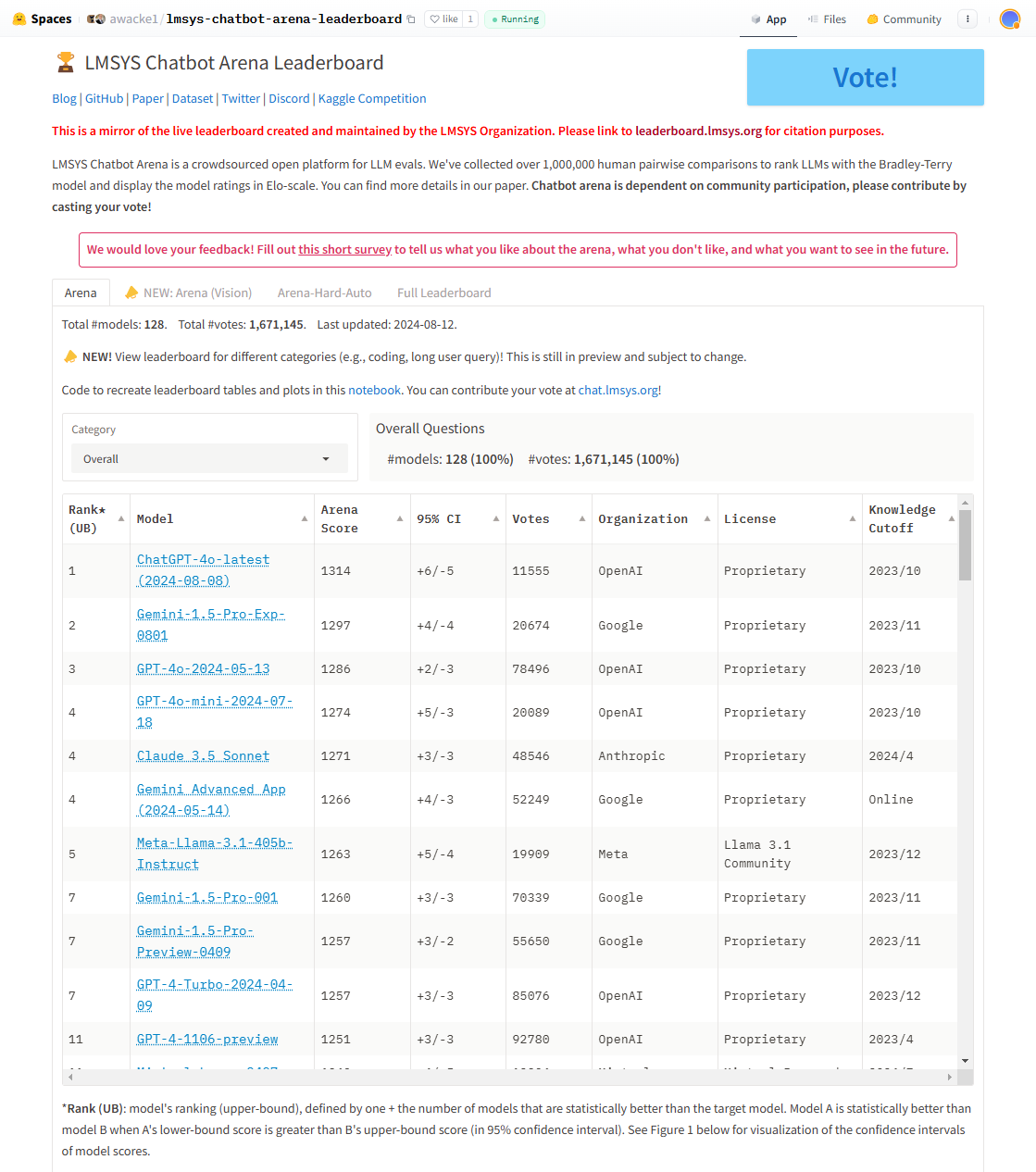
Lmsys Chatbot Arena Leaderboard
采用盲测对战(Blind Pairwise Comparison)方式的聊天机器人评测榜单。
Elo评分系统实现:
import math
class EloRatingSystem:
"""Elo评分系统实现"""
def __init__(self, k_factor=32, initial_rating=1500):
self.k_factor = k_factor
self.initial_rating = initial_rating
self.ratings = {}
def get_rating(self, model_name):
return self.ratings.get(model_name, self.initial_rating)
def expected_score(self, rating_a, rating_b):
"""E_A = 1 / (1 + 10^((R_B - R_A) / 400))"""
return 1.0 / (1.0 + math.pow(10, (rating_b - rating_a) / 400.0))
def update_ratings(self, model_a, model_b, result):
"""R'_A = R_A + K * (S_A - E_A)"""
rating_a = self.get_rating(model_a)
rating_b = self.get_rating(model_b)
expected_a = self.expected_score(rating_a, rating_b)
expected_b = self.expected_score(rating_b, rating_a)
new_rating_a = rating_a + self.k_factor * (result - expected_a)
new_rating_b = rating_b + self.k_factor * ((1 - result) - expected_b)
self.ratings[model_a] = new_rating_a
self.ratings[model_b] = new_rating_b
return new_rating_a, new_rating_b
# 使用示例
elo_system = EloRatingSystem()
matches = [
("GPT-4", "Claude-3", 1.0),
("GPT-4", "Llama-3", 1.0),
("Claude-3", "Llama-3", 0.5),
]
for model_a, model_b, result in matches:
elo_system.update_ratings(model_a, model_b, result)
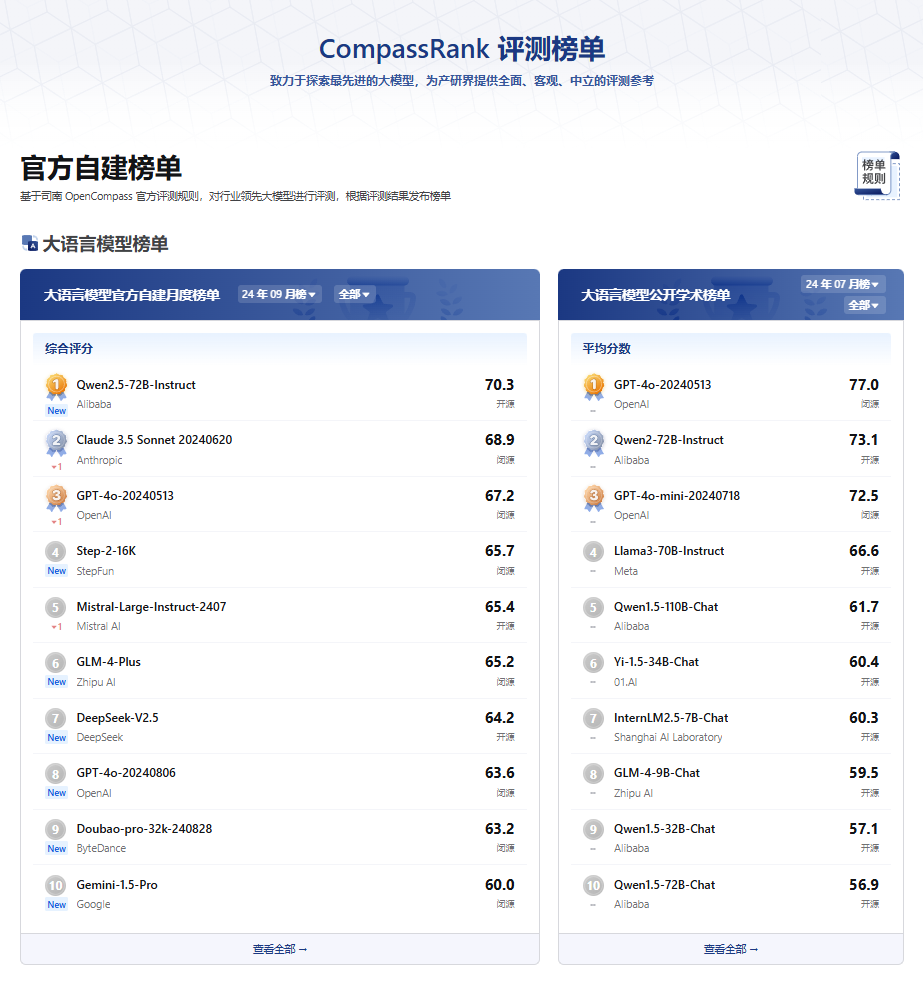
OpenCompass
国内大模型综合评测体系,专门针对中文大模型和本地化需求。
7.1.3 特定领域评测榜单

垂直领域评测榜单:
- 金融榜(CFBenchmark):金融NLP、预测计算、分析与安全
- 安全榜(Flames):公平性、安全性、隐私、鲁棒性、合法性
- 通识榜(BotChat):日常对话能力评测
- 法律榜(LawBench):法律理解、推理和应用
- 医疗榜(MedBench):医学知识问答和伦理理解
法律榜评估示例:
class LegalBenchmarkEvaluator:
"""法律领域评测系统"""
def evaluate_clause_identification(self, model_output, ground_truth):
"""评估合同条款识别任务"""
identified_clauses = set(model_output.get('clauses', []))
true_clauses = set(ground_truth.get('clauses', []))
tp = len(identified_clauses & true_clauses)
fp = len(identified_clauses - true_clauses)
fn = len(true_clauses - identified_clauses)
precision = tp / (tp + fp) if (tp + fp) > 0 else 0
recall = tp / (tp + fn) if (tp + fn) > 0 else 0
f1 = 2 * (precision * recall) / (precision + recall) if (precision + recall) > 0 else 0
return {'precision': precision, 'recall': recall, 'f1_score': f1}
7.2 检索增强生成(RAG)技术
7.2.1 RAG的基本原理与动机
大语言模型面临的挑战:
- 幻觉问题:生成不准确或误导性内容
- 知识时效性:训练数据存在截止日期
- 专业领域局限:深度知识掌握不足
RAG核心思想:在生成答案之前,先从外部知识库检索相关信息。
数学表示:
P ( a ∣ q ) = ∑ d ∈ D k P ( a ∣ q , d ) ⋅ P ( d ∣ q ) P(a|q) = \sum_{d \in \mathcal{D}_k} P(a|q, d) \cdot P(d|q) P(a∣q)=d∈Dk∑P(a∣q,d)⋅P(d∣q)
相似度计算(余弦相似度):
similarity ( q , d ) = v q ⋅ v d ∣ ∣ v q ∣ ∣ ⋅ ∣ ∣ v d ∣ ∣ \text{similarity}(q, d) = \frac{\mathbf{v}_q \cdot \mathbf{v}_d}{||\mathbf{v}_q|| \cdot ||\mathbf{v}_d||} similarity(q,d)=∣∣vq∣∣⋅∣∣vd∣∣vq⋅vd
7.2.2 构建Tiny-RAG框架实战
Step 1: RAG系统架构
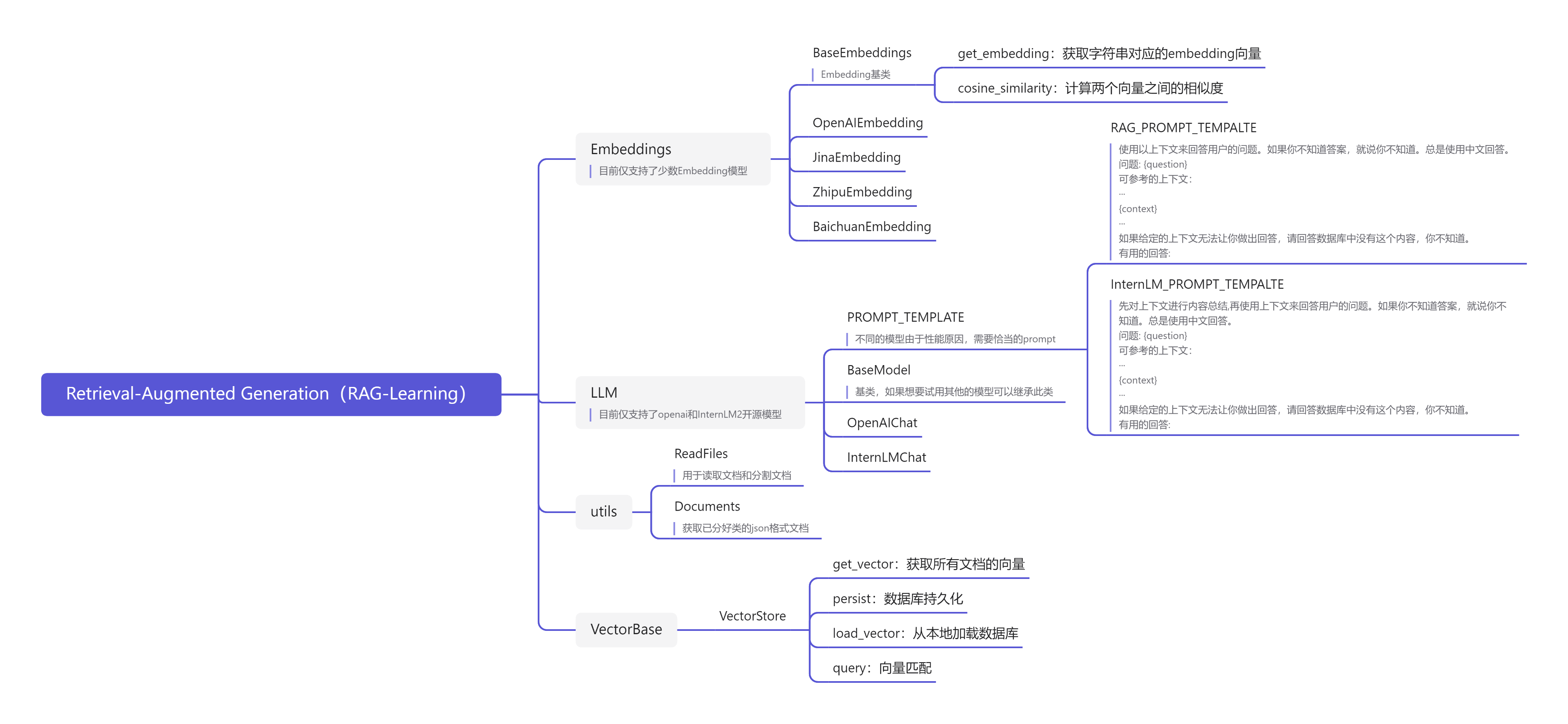
RAG系统核心模块:
- 文档加载和切分模块
- 向量化模块
- 向量数据库
- 检索模块
- 生成模块

Step 2: 文档加载与智能切分
import tiktoken
from typing import List
enc = tiktoken.get_encoding("cl100k_base")
class DocumentProcessor:
"""文档处理类"""
@classmethod
def read_file_content(cls, file_path: str) -> str:
"""根据文件类型读取内容"""
if file_path.endswith('.pdf'):
return cls.read_pdf(file_path)
elif file_path.endswith('.md'):
return cls.read_markdown(file_path)
elif file_path.endswith('.txt'):
return cls.read_text(file_path)
else:
raise ValueError(f"不支持的文件类型: {file_path}")
@classmethod
def read_text(cls, file_path: str) -> str:
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
@classmethod
def get_chunks(cls, text: str, max_token_len: int = 600,
cover_content: int = 150) -> List[str]:
"""智能文档切分"""
chunk_text = []
curr_len = 0
curr_chunk = ''
token_len = max_token_len - cover_content
lines = text.splitlines()
for line in lines:
line = line.strip()
line_len = len(enc.encode(line))
if line_len > max_token_len:
if curr_chunk:
chunk_text.append(curr_chunk)
curr_chunk = ''
curr_len = 0
line_tokens = enc.encode(line)
num_chunks = (len(line_tokens) + token_len - 1) // token_len
for i in range(num_chunks):
start_token = i * token_len
end_token = min(start_token + token_len, len(line_tokens))
chunk_tokens = line_tokens[start_token:end_token]
chunk_part = enc.decode(chunk_tokens)
if i > 0 and chunk_text:
prev_chunk = chunk_text[-1]
cover_part = prev_chunk[-cover_content:]
chunk_part = cover_part + chunk_part
chunk_text.append(chunk_part)
curr_chunk = ''
curr_len = 0
elif curr_len + line_len + 1 <= token_len:
if curr_chunk:
curr_chunk += '\n'
curr_len += 1
curr_chunk += line
curr_len += line_len
else:
if curr_chunk:
chunk_text.append(curr_chunk)
if chunk_text:
prev_chunk = chunk_text[-1]
cover_part = prev_chunk[-cover_content:]
curr_chunk = cover_part + '\n' + line
curr_len = len(enc.encode(cover_part)) + 1 + line_len
else:
curr_chunk = line
curr_len = line_len
if curr_chunk:
chunk_text.append(curr_chunk)
return chunk_text
Step 3: 文本向量化
import numpy as np
from typing import List
import os
from openai import OpenAI
class BaseEmbeddings:
"""向量化基类"""
def __init__(self, path: str, is_api: bool):
self.path = path
self.is_api = is_api
def get_embedding(self, text: str, model: str) -> List[float]:
raise NotImplementedError
@classmethod
def cosine_similarity(cls, vector1: List[float], vector2: List[float]) -> float:
"""计算余弦相似度"""
v1 = np.array(vector1, dtype=np.float32)
v2 = np.array(vector2, dtype=np.float32)
if not np.all(np.isfinite(v1)) or not np.all(np.isfinite(v2)):
return 0.0
dot_product = np.dot(v1, v2)
norm_v1 = np.linalg.norm(v1)
norm_v2 = np.linalg.norm(v2)
magnitude = norm_v1 * norm_v2
if magnitude == 0:
return 0.0
return float(dot_product / magnitude)
class OpenAIEmbedding(BaseEmbeddings):
"""OpenAI向量化实现"""
def __init__(self, path: str = '', is_api: bool = True):
super().__init__(path, is_api)
if self.is_api:
self.client = OpenAI()
self.client.api_key = os.getenv("OPENAI_API_KEY")
self.client.base_url = os.getenv("OPENAI_BASE_URL")
def get_embedding(self, text: str, model: str = "BAAI/bge-m3") -> List[float]:
"""使用硅基流动的免费嵌入模型"""
if self.is_api:
text = text.replace("\n", " ")
response = self.client.embeddings.create(input=[text], model=model)
return response.data[0].embedding
else:
raise NotImplementedError
Step 4: 向量数据库
import json
import pickle
from pathlib import Path
class VectorStore:
"""向量数据库"""
def __init__(self, documents: List[str] = None):
self.documents = documents or []
self.vectors = []
def get_vectors(self, embedding_model: BaseEmbeddings) -> List[List[float]]:
"""生成所有文档的向量"""
self.vectors = []
for i, doc in enumerate(self.documents):
vector = embedding_model.get_embedding(doc)
self.vectors.append(vector)
print(f"向量化进度: {i+1}/{len(self.documents)}")
return self.vectors
def persist(self, path: str = 'storage'):
"""持久化保存"""
Path(path).mkdir(parents=True, exist_ok=True)
with open(f'{path}/documents.json', 'w', encoding='utf-8') as f:
json.dump(self.documents, f, ensure_ascii=False, indent=2)
with open(f'{path}/vectors.pkl', 'wb') as f:
pickle.dump(self.vectors, f)
print(f"数据库已保存到: {path}")
def load_vector(self, path: str = 'storage'):
"""从本地加载"""
with open(f'{path}/documents.json', 'r', encoding='utf-8') as f:
self.documents = json.load(f)
with open(f'{path}/vectors.pkl', 'rb') as f:
self.vectors = pickle.load(f)
print(f"数据库已加载: {path}")
def query(self, query: str, embedding_model: BaseEmbeddings, k: int = 1) -> List[str]:
"""检索最相关的文档"""
query_vector = embedding_model.get_embedding(query)
similarities = np.array([
BaseEmbeddings.cosine_similarity(query_vector, doc_vector)
for doc_vector in self.vectors
])
top_k_indices = similarities.argsort()[-k:][::-1]
results = [self.documents[i] for i in top_k_indices]
print(f"\n查询: {query}")
print(f"检索到 {k} 个相关文档")
for i, (idx, sim) in enumerate(zip(top_k_indices, similarities[top_k_indices]), 1):
print(f"{i}. 相似度: {sim:.4f}")
return results
Step 5: 大模型集成
from typing import List, Dict
RAG_PROMPT_TEMPLATE = """
使用以下上下文来回答用户的问题。如果你不知道答案,就说你不知道。总是使用中文回答。
问题: {question}
可参考的上下文:
======================================================================
{context}
======================================================================
如果给定的上下文无法让你做出回答,请回答数据库中没有这个内容,你不知道。
有用的回答:
"""
class BaseModel:
"""大模型基类"""
def __init__(self, path: str = ''):
self.path = path
def chat(self, prompt: str, history: List[Dict], content: str) -> str:
raise NotImplementedError
class OpenAIChat(BaseModel):
"""OpenAI Chat模型"""
def __init__(self, model: str = "Qwen/Qwen2.5-32B-Instruct"):
super().__init__()
self.model = model
def chat(self, prompt: str, history: List[Dict], content: str) -> str:
from openai import OpenAI
client = OpenAI()
client.api_key = os.getenv("OPENAI_API_KEY")
client.base_url = os.getenv("OPENAI_BASE_URL")
rag_prompt = RAG_PROMPT_TEMPLATE.format(question=prompt, context=content)
history.append({'role': 'user', 'content': rag_prompt})
response = client.chat.completions.create(
model=self.model,
messages=history,
max_tokens=2048,
temperature=0.1
)
return response.choices[0].message.content
Step 6: 完整RAG系统
class TinyRAG:
"""Tiny-RAG完整系统"""
def __init__(self, embedding_model, chat_model, vector_store=None):
self.embedding_model = embedding_model
self.chat_model = chat_model
self.vector_store = vector_store or VectorStore()
self.history = []
def load_documents(self, file_path: str, max_token_len: int = 600,
cover_content: int = 150):
"""加载并处理文档"""
processor = DocumentProcessor()
content = processor.read_file_content(file_path)
chunks = processor.get_chunks(content, max_token_len, cover_content)
self.vector_store = VectorStore(chunks)
self.vector_store.get_vectors(self.embedding_model)
def save_database(self, path: str = 'storage'):
self.vector_store.persist(path)
def load_database(self, path: str = 'storage'):
self.vector_store.load_vector(path)
def query(self, question: str, k: int = 3) -> str:
"""RAG问答流程"""
relevant_docs = self.vector_store.query(question, self.embedding_model, k=k)
context = "\n\n".join(relevant_docs)
answer = self.chat_model.chat(question, self.history, context)
self.history.append({'role': 'user', 'content': question})
self.history.append({'role': 'assistant', 'content': answer})
return answer
# 使用示例
embedding_model = OpenAIEmbedding()
chat_model = OpenAIChat()
rag_system = TinyRAG(embedding_model, chat_model)
rag_system.load_documents('./data/document.txt')
rag_system.save_database('storage')
answer = rag_system.query("RAG的原理是什么?", k=2)
print(answer)


















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











