







1. 概述
1.1 定义
栈(stack)又名堆栈,它是一种运算受限的线性表。限定仅在表尾进行插入和删除操作的线性表。这一端被称为栈顶,相对地,把另一端称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
1.2 相关概念
- 栈顶(Top):线性表允许进行插入和删除的一端
- 栈底(Bottom):固定的,不允许进行插入和删除的另一端
- 空栈:不含任何元素
示意图:
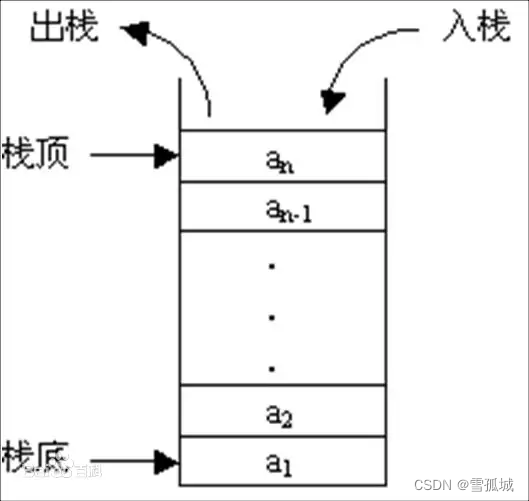
a1为栈底元素,an为栈顶元素。由于栈只能在栈顶进行插入和删除操作,故进栈次序依次为a1,a2,… ,an 。
而出栈次序为an,…,a2,a1。栈的明显的操作特征为后进先出(Last In First Out,LIFO),故又称后进先出的线性表。
1.3 基本操作
- InitStack:初始化空栈
- StackEmpty:判断一个栈是否为空
- Push:进栈,若栈未满,则将新加入的元素使之成为新栈顶
- Pop:出栈,若栈非空,则将栈顶元素移出并返回
- GetTop:读栈顶元素,若栈顶元素非空,则返回栈顶元素
- DestroyStack:销毁栈,并释放栈占用的存储空间
2. 栈的分类
2.1 顺序栈
采用顺序存储(比如数组)的栈称为顺序栈,它是利用一组地址连续的存储单元存放自栈底到栈顶的数据元素。
栈接口:
package com.example.data_structure;
public interface MyStack<E> {
/**
* 入栈
*
* @param e 栈存储元素
*/
void push(E e);
/**
* 出栈
*
* @return 栈顶元素
*/
E pop();
/**
* 栈大小
*
* @return 栈大小
*/
Integer size();
/**
* 判断栈是否为空
*
* @return true:空;false:非空
*/
Boolean isEmpty();
}
数组栈具体实现:
package com.example.data_structure;
/**
* 描述:
* 自定义栈结构
*
* @author XueGuCheng
* @create 2022-09-18 22:10
*/
public class ArrayStack<E> implements MyStack<E> {
// 栈初始化
private E[] initializationStack = (E[]) new Object[2];
// 初始的元素个数
private int stackSize = 0;
public ArrayStack(int cap) {
initializationStack = (E[]) new Object[cap];
}
/**
* 入栈
*
* @param e 栈存储元素
*/
@Override
public void push(E e) {
judgeSize();
initializationStack[stackSize++] = e;
}
/**
* 栈扩容
*/
private void judgeSize() {
// 元素个数已经超出了数组的个数
if (stackSize >= initializationStack.length) {
resize(2 * initializationStack.length);
} else if (stackSize > 0 && stackSize <= initializationStack.length / 2) {
resize(initializationStack.length / 2);
}
}
/**
* 扩容具体实现
*
* @param size 扩容的大小
*/
private void resize(int size) {
E[] tempStack = (E[]) new Object[size];
for (int i = 0; i < stackSize; i++) {
tempStack[i] = initializationStack[i];
}
initializationStack = tempStack;
}
/**
* 出栈
*
* @return 栈顶元素
*/
@Override
public E pop() {
if (isEmpty()) {
return null;
}
E e = initializationStack[--stackSize];
initializationStack[stackSize] = null;
return e;
}
/**
* 栈大小
*
* @return 栈大小
*/
@Override
public Integer size() {
return stackSize;
}
/**
* 判断栈是否为空
*
* @return true:空;false:非空
*/
@Override
public Boolean isEmpty() {
return stackSize == 0;
}
}
2.2 链栈
采用链式存储的栈称为链栈,链栈的优点是便于多个栈共享存储空间和提高其效率,且不存在栈满上溢的情况。通常采用单链表实现,并规定所有操作都是在单链表的表头进行的。
代码实现:
package com.example.data_structure;
/**
* 描述:
* 链栈的具体实现
*
* @author XueGuCheng
* @create 2022-09-18 22:33
*/
public class LinkedStack<E> implements MyStack<E> {
// 首结点
Node node;
public LinkedStack(Node node) {
node = new Node();
}
/**
* 入栈
*
* @param e 栈存储元素
*/
@Override
public void push(E e) {
if (node.object == null) {
node.object = e;
return;
}
// 头插法:每次插入的栈顶元素都在链表的开始位置
node = new Node(e, node);
}
/**
* 出栈
*
* @return 栈顶元素
*/
@Override
public E pop() {
if (node.object == null) {
return null;
}
Node temp = node;
node = node.next == null ? new Node() : node.next;
return (E) temp.object;
}
/**
* 栈大小
*
* @return 栈大小
*/
@Override
public Integer size() {
if (node.object == null) {
return 0;
}
int size = 1;
Node newNode = node;
while (newNode.next != null) {
size++;
newNode = newNode.next;
}
return size;
}
/**
* 判断栈是否为空
*
* @return true:空;false:非空
*/
@Override
public Boolean isEmpty() {
return node.object == null;
}
// 链表节点
class Node {
// 链表元素的值
Object object;
// 下一个值的指针
Node next;
// 初始化
public Node() {
}
public Node(Object object) {
this.object = object;
}
public Node(Object object, Node next) {
this.object = object;
this.next = next;
}
@Override
public String toString() {
return "Node{" +
"object=" + object +
", next=" + next +
'}';
}
}
}
2.3 顺序栈与链栈的区别
- 入栈,出栈的时间复杂度都是O(1)。(顺序栈的入栈操作是直接根据头指针将数据加入到数组指定的下标位置,链栈的入栈则是直接在首结点插入)
- 初始时顺序栈必须确定一个固定的长度,所以有存储元素个数的限制和空间浪费的问题。
- 链栈无栈满问题,只有当内存没有可用空间时才会出现栈满,但是每个元素都需要一个指针域,从而产生了结构性开销。















 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









