










20211220
 https://developer.mozilla.org/zh-CN/docs/Web/Performance/How_browsers_work#%E8%A7%A3%E6%9E%90
https://developer.mozilla.org/zh-CN/docs/Web/Performance/How_browsers_work#%E8%A7%A3%E6%9E%90 https://xie.infoq.cn/article/21ad6b8269f3eb0674ee1c0b2
https://xie.infoq.cn/article/21ad6b8269f3eb0674ee1c0b220211215
预读和延迟写技术:以大数据块的倍数预先载入数据,以及合并多个小的逻辑写操作成一个大的物理写操作
20211208
浏览器中的javascript 分词
Unicode Segmentation in JavaScript![]() https://h3manth.com/posts/unicode-segmentation-in-javascript/
https://h3manth.com/posts/unicode-segmentation-in-javascript/
CodeMirror(下面简称为cm)是一款基于JavaScript、面向语言的前端代码编辑器。它支持开箱即用,自带了超过100种语言的库,同时还有很多附加功能,目前得到了jetbrains等公司的支持。在这个分类下,能够与cm并驾齐驱的另一个编辑器则是ACE。由于笔者并没有使用过ACE,因此就不对两者做对比了。接下来笔者会分几个章节来具体介绍介绍cm的基本使用方法和高级功能。
CodeMirror官网:CodeMirror

CodeMirror入门教程 - 张恒的网络日志![]() https://blog.gavinzh.com/2020/12/13/codemirror-getting-started/
https://blog.gavinzh.com/2020/12/13/codemirror-getting-started/
20211205
再见了VMware,一款更轻量级的虚拟机!再见了VMware,一款更轻量级的虚拟机!https://mp.weixin.qq.com/s/zMG4R1XrCbI-C71iYd9LMg
如何在Docker容器中运行Docker [3种方法]在docker中运行docker的三种不同方法https://mp.weixin.qq.com/s/i-7uu9Xtty_2bAG-sNBbUw
Docker in Docker - 简书Docker Run Docker? Docker技术目前在DevOps中被广泛使用,我们需要将测试或者构建的代码和自动化脚本打包成Docker镜像,然后部署在各运行环境中。...https://www.jianshu.com/p/43ffba076bc9
Docker技术目前在DevOps中被广泛使用,我们需要将测试或者构建的代码和自动化脚本打包成Docker镜像,然后部署在各运行环境中。而在CI/CD中,我们常用一些CI/CD服务器,比如Jenkins和GoCD来构建与部署我们的应用,从而实现CI/CD的自动化。现在一些CI/CD服务器也被Docker化运行在真实的物理机上。于是我们需要在CI/CD服务器的Docker container里面来构建(build)与运行(run)我们的Docker镜像,这就涉及到"Docker run Docker"的问题。
这种方式会导致内部的docker比外部的docker有更大的访问权限,看似很简单,其实埋了很大的坑!
是的,安全隐患很大,比如自己可以删掉别人的pipeline,之前我们有的同事实践是外部建一个用户进行权限控制,然后让docker里面以这个用户身份运行。这篇文章主要想讲docker in docker所以尽量没扩展,这个的确是很好的point值得提醒大家,我加到文章里面去。
一文搞懂 Kubernetes 日志收集的那些套路你是怎样在 Kubernetes 下收集日志的呢?https://mp.weixin.qq.com/s/wIWJSbec8WuX8yy-Aer40w
4 款超强大易用的管理工具,助你轻松玩转 Kuberneteshttps://mp.weixin.qq.com/s/zrdAzUQ-6c4jWLHRx3q8-A
万字总结,体系化带你全面认识容器网络接口(CNI)https://mp.weixin.qq.com/s/gWPZKz9Z4gCoZRFX8dvr6w
一文搞懂 Kubernetes 中数据包的生命周期你不可能错过的 Kubernetes 万字干货文章!https://mp.weixin.qq.com/s/SqCwa069y4dcVQ1fWNQ0Wg
七步制作一个超级精简的 Docker 镜像,So easyhttps://mp.weixin.qq.com/s/cWSC9hQ6JHCAMRO4jrZ7VQ
30 张图带你了解 CPU 制作全过程没有最复杂,只有更复杂。制作 CPU 远比你想像的更困难!https://mp.weixin.qq.com/s/3yvCCIOR1nq8n4Gbo6syAw
深入理解Cache工作原理Cache 在计算机体系架构中有非常重要的地位https://mp.weixin.qq.com/s/pUt_Sg1c8tmd2bm53Z-F4A
28 张图带你体系化全面认识 Kafka你学会 Kafka 了吗?https://mp.weixin.qq.com/s/4ggUHipWRaYKg-aJmtbeXQ
9 张图带你搞懂 Kafka 分区不积跬步,无以至千里。https://mp.weixin.qq.com/s/E9FALuVQuDaIAMVc4CxxiA
linux主机网络流量抓包监控linux主机网络流量抓包监控https://mp.weixin.qq.com/s/gA204bySXmTGq5XEOdzDtw
20211201
通过 unshare 命令,可以快速建立一些隔离的例子,我们拿最简单直观的 pid namespace 来看一下它的效果。
众所周知,Linux 进程号为 1 的,叫做 systemd 进程。但在 Docker 中,我们通过执行 ps 命令,却只能看到非常少的进程列表。
执行下面的命令,进入隔离环境,并将 bash 作为根进程:
unshare --pid --fork --mount-proc /bin/bash5分钟搞定Docker底层原理!不搞虚的!5分钟快速了解Docker的底层原理!https://mp.weixin.qq.com/s/QiWbS4S3t9cj4WjF4qhK7Q
20211130
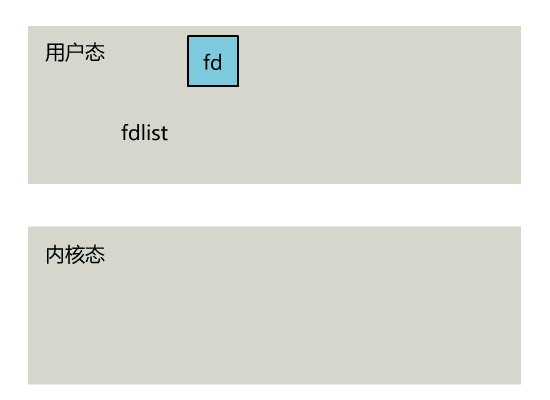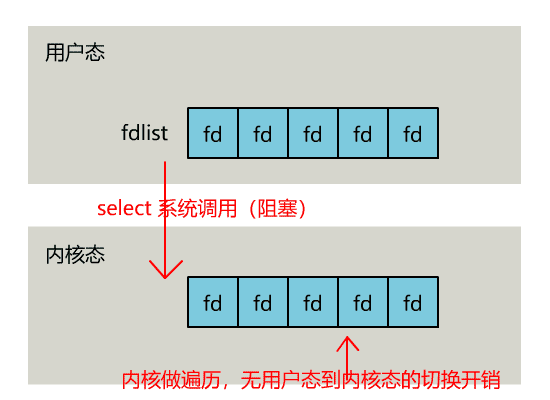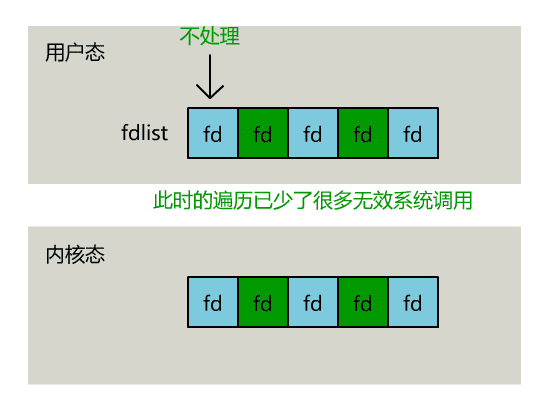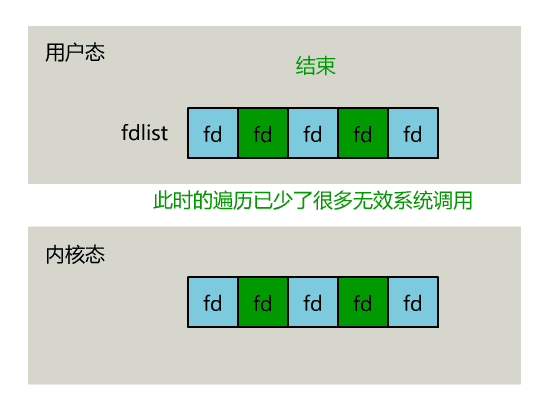

你管这破玩意叫 IO 多路复用?https://mp.weixin.qq.com/s/SuCUybYv4YHn7wY12WBlCQ
20211126
接收对象、返回对象 Receive an Object, Return Object 建成RORO
//入口参数时一个对象解构
async function getItemFromCollection({ id, collectionName }) {
//返回参数也是一个对象
return {id:xxx,name:"xxx"}
};
const {id,name} = await getItemFromCollection({
id: 54391,
collectionName: 'shop',
});为什么要这样做?
如果 const item = await getItemFromCollection(54391, 'shop'); 这样调用函数 你需要明确知道54391的是意思
这种情况下 你需要查看函数原型 后才能知道 54391 是 id
async function getItemFromCollection(id, collectionName) {
同样如果函数的返回值是单个值 而不是对象时,你也需要参数的意义
所以要RORO
Javascript RORO pattern | Blog![]() https://www.tinyblog.dev/blog/2020-07-13-javascript-roro-pattern/
https://www.tinyblog.dev/blog/2020-07-13-javascript-roro-pattern/
20211125
王垠:编程的智慧。https://mp.weixin.qq.com/s/axfjfO92FDs8aOHEb1Mokw
[mysqld] slow-query-log = 1 slow-query-log-file = /var/log/mysql/localhost-slow.log long_query_time = 1 log-queries-not-using-indexes
分析慢查询日志
mysqldumpslow -s at /var/log/mysql/kalacloud-slow.log
20211119
Xterm.js is the frontend component that powers many terminals including
VS Code, Hyper and Theia! 网页shell

Hurl is a command line tool that runs HTTP requests defined in a simple plain text format.
It can perform requests, capture values and evaluate queries on headers and body response. Hurl is very versatile: it can be used for both fetching data and testing HTTP sessions.
# Get home:
GET https://example.net
HTTP/1.1 200
[Captures]
csrf_token: xpath "string(//meta[@name='_csrf_token']/@content)"
# Do login!
POST https://example.net/login?user=toto&password=1234
X-CSRF-TOKEN: {{csrf_token}} https://github.com/Orange-OpenSource/hurl
https://github.com/Orange-OpenSource/hurl20211118
20211117
awk 学习
 https://earthly.dev/blog/awk-examples/
https://earthly.dev/blog/awk-examples/20211116
局部性是事物普遍存在的性质。一个人认识宇宙的范围受限于光速和人的寿命,这是一种局部性;一个人只能认识有限的人,其中天天打交道的熟悉的人更少,这也是一种局部性。局部性在计算机中普遍存在,是计算机性能优化的基础。
体系结构利用局部性进行性能优化时,最常见的是利用事件局部性,即有些事件频繁发生,有些事件不怎么发生,在这种情况下要重点优化频繁发生的事件。当结构设计基本平衡以后,优化性能要抓主要矛盾,重点改进最频繁发生事件的执行效率。作为设计者必须清楚什么是经常性事件,以及提高这种情况下机器运行的速度对计算机整体性能有多大贡献。
利用访存局部性进行优化是体系结构提升访存指令性能的重要方法。访存局部性包括时间局部性和空间局部性两种。时间局部性指的是一个数据被访问后很有可能多次被访问。空间局部性指的是一个数据被访问后,它邻近的数据很有可能被访问,例如数组按行访问时相邻的数据连续被访问,按列访问时虽然空间上不连续,但每次加上一个固定的步长,也是一种特殊的空间局部性。计算机体系结构使用访存局部性原理来提高性能的地方很多,如高速缓存、TLB、预取都利用了访存局部性
计算机体系结构基础计算机体系结构基础![]() https://foxsen.github.io/archbase/
https://foxsen.github.io/archbase/
20211115
ThreadPoolExecutor中提供了以下方法来获取线程池中的指标。
getCorePoolSize():获取核心线程数。
getMaximumPoolSize:获取最大线程数。
getQueue():获取线程池中的阻塞队列,并通过阻塞队列中的方法获取队列长度、元素个数等。
getPoolSize():获取线程池中的工作线程数(包括核心线程和非核心线程)。
getActiveCount():获取活跃线程数,也就是正在执行任务的线程。
getLargestPoolSize():获取线程池曾经到过的最大工作线程数。
getTaskCount():获取历史已完成以及正在执行的总的任务数量。
除此之外,ThreadPoolExecutor中还提供了一些未实现的钩子方法,我们可以通过重写这些方法来实现更多指标数据的获取。
beforeExecute,在Worker线程执行任务之前会调用的方法。
afterExecute,在Worker线程执行任务之后会调用的方法。
terminated,当线程池从状态变更到TERMINATED状态之前调用的方法。
比如我们可以在beforeExecute方法中记录当前任务开始执行的时间,再到afterExecute方法来计算任务执行的耗时、最大耗时、最小耗时、平均耗时等。
20211114
《MySQL8查询性能调优》 中文翻译
项目简介
这是PDF Explained的非官方中文翻译版, 大体已经完成, 还需要完善很多细节部分。 详见ISSUE 希望得到你们的帮助!让项目越来越完善,帮助更多的人入门PDF,在此表示感谢!
原书简介
这是对广泛使用的可移植文档格式的平易近人的介绍。 PDF无处不在,无论是在线形式还是印刷形式,但很少有人利用这些有用的功能或掌握这种格式的细微差别。 这本简明的书籍为程序员,高级用户提供了世界领先的页面描述语言(pdf)的动手实践。以及搜索,电子出版和印刷行业的专业人士, 有大量示例,本书是你完全理解PDF所需的文档。
GitHub - zxyle/PDF-Explained: 《PDF 解析》![]() https://github.com/zxyle/PDF-Explained
https://github.com/zxyle/PDF-Explained
SET GLOBAL innodb_status_output=ON;
SET GLOBAL innodb_status_output_locks=ON;
Directing Standard InnoDB Monitor Output to a Status File
Standard InnoDB Monitor output can be enabled and directed to a status file by specifying the --innodb-status-file option at startup. When this option is used, InnoDB creates a file named innodb_status. in the data directory and writes output to it every 15 seconds, approximately.pid
InnoDB removes the status file when the server is shut down normally. If an abnormal shutdown occurs, the status file may have to be removed manually.
The --innodb-status-file option is intended for temporary use, as output generation can affect performance, and the innodb_status. file can become quite large over time.pid
20211111
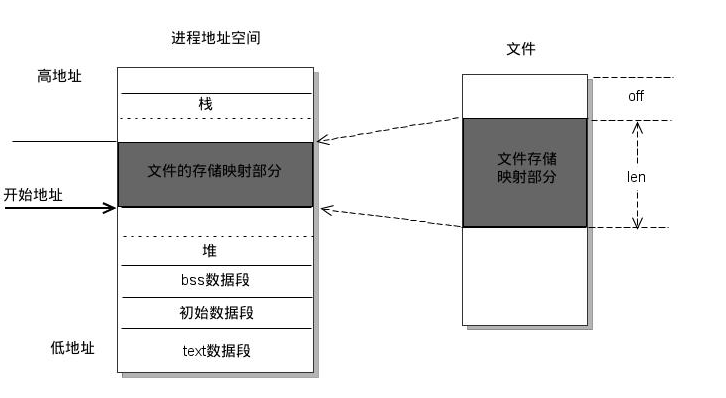
重新认识 Java 中的内存映射(mmap)重新认识 mmaphttps://mp.weixin.qq.com/s/Xi9pQ8g1q8wr37hUGzSB6w
20211101
庖丁解 InnoDB 之 Undolog - 51CTO.COM![]() https://zhuanlan.51cto.com/art/202111/689329.htm
https://zhuanlan.51cto.com/art/202111/689329.htm
go 语言中的 flag 与 cobra
一种命令行解析的新思路(Go 语言描述)![]() https://mp.weixin.qq.com/s/RxpcqBGhUT-5z4N5kRXvBg
https://mp.weixin.qq.com/s/RxpcqBGhUT-5z4N5kRXvBg
20211109
获取rabbitmq重试次数

Dead Letter Exchanges — RabbitMQhttps://www.rabbitmq.com/dlx.html
在业务队列上绑定了死信交换机以及死信路由键,此时调用生产者发送消息,消费者在重试5次后,由于MessageCover默认的实现类是RejectAndDontRequeueRecoverer,也就是requeue=false,又因为业务队列绑定了死信队列,因此消息会从业务队列中删除,同时发送到死信队列中。
注意:
如果ack模式是手动ack,那么需要调用channe.nack方法,同时设置requeue=false才会将异常消息发送到死信队列中
 https://www.cnblogs.com/ybyn/p/13691058.html
https://www.cnblogs.com/ybyn/p/13691058.html20211108
SFU(Selective Forwarding Unit)是最近几年流行的新架构,SFU 的方案跟 MCU 类似,每个客户端都把音视频数据发给服务端,然后由服务端转发给不同的客户端。跟 MCU 不同的地方,SFU 不对音视频进行混流,收到某个客户端的音视频数据后,按需(目标客户端是否订阅)将音视频数据原封不动的转发给目标客户端。它实际上就是一个音视频路由转发器。在这种方案里,所有的混流都是在客户端做的,对服务端的计算要求大大降低。在一些复杂的网络环境,视频的数据源端会使用 Simulcast 或 SVC 发送多层不同分辨率的视频流数据,服务端根据目标客户端的不同网络带宽和网络状况转发最合适的分辨率给目标客户端,使每个客户端的体验达到最佳。
SFU架构中的有选择的数据转发
大家知道,在SFU方案中,音视频数据是全量转发的,也就是说在10个人的会议中,服务端要把每个人的数据转发给其他9个用户(10*9),在用户数小的时候,问题不会太严重,但随着用户量的增加,问题会变的越来越严重。假设会中有100个人,每个人的视频数据是1Mbps,实际服务端需要转发的是100*99 = 9.9Gbps,在现实情况下,这几乎是不可能的。在实际情况中,受屏幕大小的限制,每个人不可能同时去看另外99个用户的视频,最常见的情况是1大+6小,或2*2、3*3、4*4、5*5等几种模式,这样,通过按需转发的方式,数据量可以大幅度的减少。
在单向直播的场景中,我们也可以通过第三方CDN网络来扩展会议规模,但这种方案的延迟会比较大,会达到3~10秒的延迟,基本无法互动沟通,只能单向直播,当需要互动沟通的时候,必须切换接入方式到边缘计算节点或中心DC (为了给企业和开发者提供极致的音视频体验,需要采用广布 DC,将服务下沉到最后一公里之外)。
直连方案基本不大适合大会场景,而且无法对网络内容进行审核,直连方案目前市场上基本只有在免费场景中看到。而随着计算成本和带宽成本的大幅度下降,及超大并发的需求,SFU方案的优势变得非常明显(因为SFU 需要转发的数据量比MCU 大),而MCU方案在一些企业内基于音视频终端的通讯等传统应用场景目前还是比较常见的。

无论是中断还是异常,最终都是通过各种方式,让 CPU 得到一个中断号。只不过中断是通过外部设备给 CPU 的 INTR 引脚发信号,异常是 CPU 自己执行指令的时候发现特殊情况触发的,自己给自己一个中断号。
认认真真的聊聊中断就单单是中断如何分类,网上的文章就五花八门https://mp.weixin.qq.com/s/vcC8ePC7YclVO363pwYrKg
缓存基本上来说就是把后面的数据加载到离自己近的地方,对于CPU来说,它是不会一个字节一个字节的加载的,因为这非常没有效率,一般来说都是要一块一块的加载的,对于这样的一块一块的数据单位,术语叫“Cache Line”,一般来说,一个主流的CPU的Cache Line 是 64 Bytes(也有的CPU用32Bytes和128Bytes),64Bytes也就是16个32位的整型,这就是CPU从内存中捞数据上来的最小数据单位。与程序员相关的CPU缓存知识 | 酷 壳 - CoolShell![]() https://coolshell.cn/articles/20793.html7个示例科普 CPU CacheCPU Cache一直是理解计算机体系架构的重要知识点,也是并发编程设计中的技术难点
https://coolshell.cn/articles/20793.html7个示例科普 CPU CacheCPU Cache一直是理解计算机体系架构的重要知识点,也是并发编程设计中的技术难点https://mp.weixin.qq.com/s/5SW4GQxEUtxeTn7oQ-7eAg
试想一下你正在遍历一个长度为 16 的 long 数组 data[16],原始数据自然存在于主内存中,访问过程描述如下
-
访问 data[0],CPU core 尝试访问 CPU Cache,未命中。
-
尝试访问主内存,操作系统一次访问的单位是一个 Cache Line 的大小 — 64 字节,这意味着:既从主内存中获取到了 data[0] 的值,同时将 data[0] ~ data[7] 加入到了 CPU Cache 之中,for free~
-
访问 data[1]~data[7],CPU core 尝试访问 CPU Cache,命中直接返回。
-
访问 data[8],CPU core 尝试访问 CPU Cache,未命中。
-
尝试访问主内存。重复步骤 2
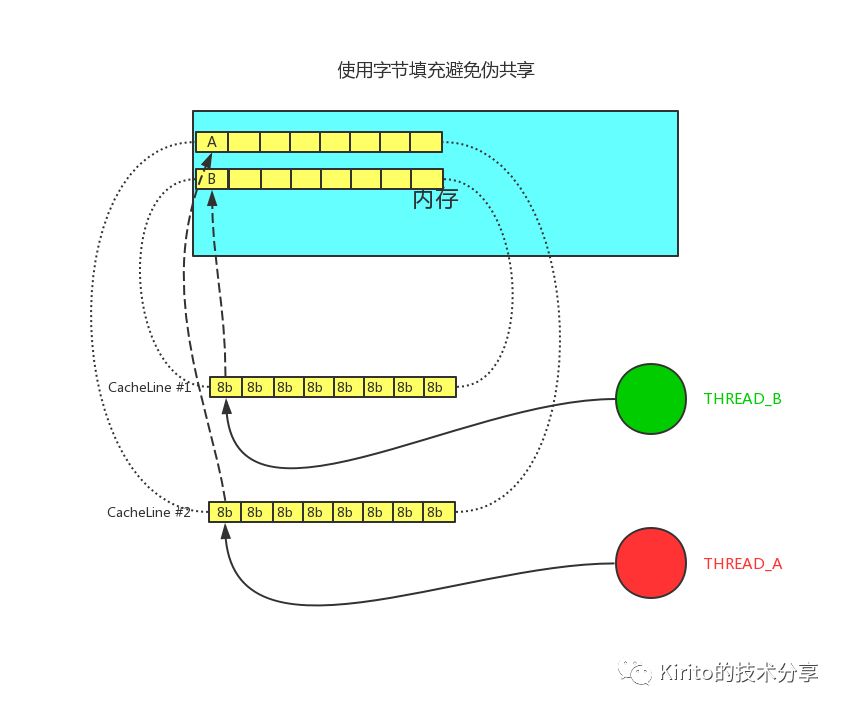
伪共享指的是多个线程同时读写同一个缓存行的不同变量时导致的 CPU 缓存失效。尽管这些变量之间没有任何关系,但由于在主内存中邻近,存在于同一个缓存行之中,它们的相互覆盖会导致频繁的缓存未命中,引发性能下降。
在多核机器上,缓存遇到了另一个问题——一致性。不同的处理器拥有完全或部分分离的缓存。在我的机器上,L1缓存是分离的(这很普遍),而我有两对处理器,每一对共享一个L2缓存。这随着具体情况而不同,如果一个现代多核机器上拥有多级缓存,那么快速小型的缓存将被处理器独占。
当一个处理器改变了属于它自己缓存中的一个值,其它处理器就再也无法使用它自己原来的值,因为其对应的内存位置将被刷新(invalidate)到所有缓存。而且由于缓存操作是以缓存行而不是字节为粒度,所有缓存中整个缓存行将被刷新!
原文
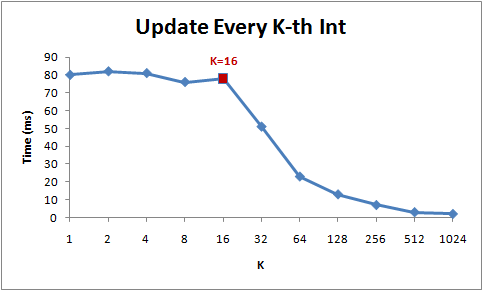
循环执行时间长短由数组的内存访问次数决定的,而非整型数的乘法运算次数
The running time of these loops is dominated by the memory accesses to the array, not by the integer multiplications.
今天的CPU不再是按字节访问内存,而是以64字节为单位的块(chunk)拿取,称为一个缓存行(cache line)。当你读一个特定的内存地址,整个缓存行将从主存换入缓存,并且访问同一个缓存行内的其它值的开销是很小的
The reason behind this is that today’s CPUs do not access memory byte by byte. Instead, they fetch memory in chunks of (typically) 64 bytes, called cache lines. When you read a particular memory location, the entire cache line is fetched from the main memory into the cache. And, accessing other values from the same cache line is cheap!
我本机的cpu和缓存信息如下


我的机器是双核心 所以L1缓存有2个 编号0和1(每个L1缓存包含一个指令缓存 Instrunction Cache 和一个数据缓存Data Cache),L1缓存不是共享缓存,也是就每个核心独享
L2缓存有两个 各256 是共享的(unified cache)
L3缓存3M 也是共享的(unified cache)
直接映射缓存会引发冲突——当多个值竞争同一个缓存槽,它们将相互驱逐对方,导致命中率暴跌。另一方面,完全关联缓存过于复杂,并且硬件实现上昂贵。N路组关联是处理器缓存的典型方案,它在电路实现简化和高命中率之间取得了良好的折中。
Direct mapped caches can suffer from conflicts – when multiple values compete for the same slot in the cache, they keep evicting each other out, and the hit rate plummets. On the other hand, fully associative caches are complicated and costly to implement in the hardware. N-way set associative caches are the typical solution for processor caches, as they make a good trade off between implementation simplicity and good hit rate.
Gallery of Processor Cache Effects![]() http://igoro.com/archive/gallery-of-processor-cache-effects/
http://igoro.com/archive/gallery-of-processor-cache-effects/
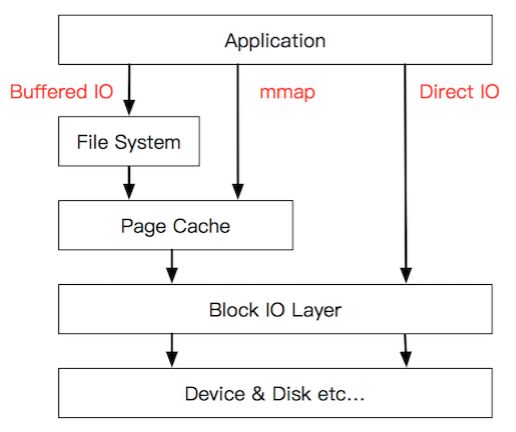
mmap 把文件映射到用户空间里的虚拟内存,省去了从内核缓冲区复制到用户空间的过程,文件中的位置在虚拟内存中有了对应的地址,可以像操作内存一样操作这个文件,相当于已经把整个文件放入内存,但在真正使用到这些数据前却不会消耗物理内存,也不会有读写磁盘的操作,只有真正使用这些数据时,也就是图像准备渲染在屏幕上时,虚拟内存管理系统 VMS 才根据缺页加载的机制从磁盘加载对应的数据块到物理内存进行渲染。这样的文件读写文件方式少了数据从内核缓存到用户空间的拷贝,效率很高
MMAP 并非是文件 IO 的银弹,它只有在一次写入很小量数据的场景下才能表现出比 FileChannel 稍微优异的性能(随机IO次数非常多的时候)
MMAP 使用时必须实现指定好内存映射的大小,并且一次 map 的大小限制在 1.5G 左右,重复 map 又会带来虚拟内存的回收、重新分配的问题,对于文件不确定大小的情形实在是太不友好了
FileChannel 同样是写入内存,但比 MMAP 多了一次内核缓冲区与用户空间互相复制的过程,所以在极端场景下,MMAP 表现的更加优秀。
FileChannel 的示例代码中已经使用到了堆内内存: ByteBuffer.allocate(4*1024),ByteBuffer 提供了另外的方式让我们可以分配堆外内存 : ByteBuffer.allocateDirect(4*1024)
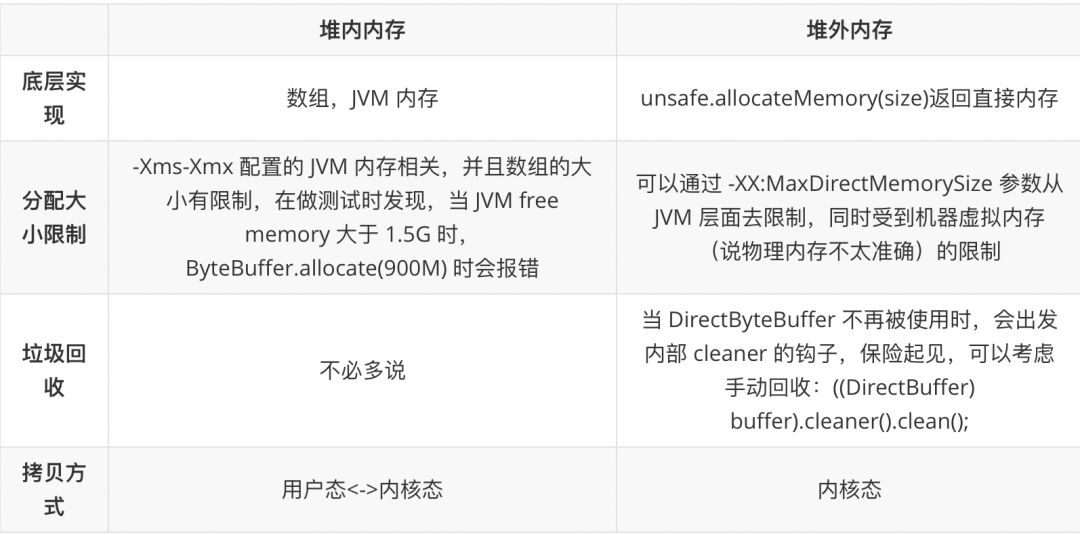
关于堆内内存和堆外内存的一些最佳实践:
-
当需要申请大块的内存时,堆内内存会受到限制,只能分配堆外内存。
-
堆外内存适用于生命周期中等或较长的对象。( 如果是生命周期较短的对象,在 YGC 的时候就被回收了,就不存在大内存且生命周期较长的对象在 FGC 对应用造成的性能影响 )。
-
直接的文件拷贝操作,或者 I/O 操作。直接使用堆外内存就能少去内存从用户内存拷贝到系统内存的消耗
-
同时,还可以使用池+堆外内存 的组合方式,来对生命周期较短,但涉及到 I/O 操作的对象进行堆外内存的再使用( Netty中就使用了该方式 )。在比赛中,尽量不要出现 频繁
newbyte[],创建内存区域再回收也是一笔不小的开销,使用ThreadLocal<ByteBuffer>和ThreadLocal<byte[]>往往会给你带来意外的惊喜~ -
创建堆外内存的消耗要大于创建堆内内存的消耗,所以当分配了堆外内存之后,尽可能复用它。
实现直接内存与内存的拷贝:
-
ByteBuffer buffer = ByteBuffer.allocateDirect(4 * 1024 * 1024); -
long addresses = ((DirectBuffer) buffer).address(); -
byte[] data = new byte[4 * 1024 * 1024]; -
UNSAFE.copyMemory(data, 16, null, addresses, 4 * 1024 * 1024); -
文件IO操作的最佳实践你可能不知道的文件操作的一些知识点和黑科技https://mp.weixin.qq.com/s/101wu0rg4mZWCxD9EuUYeA
图解VXLAN容器网络通信方案![]() https://mp.weixin.qq.com/s/Kl4T4tc1WGTJ4OzQlacXNQ
https://mp.weixin.qq.com/s/Kl4T4tc1WGTJ4OzQlacXNQ
20211105
OverlayFS是一种堆叠文件系统,它依赖并建立在其它的文件系统智商,不直接参与磁盘空间结构的划分,仅将原来文件系统中不同目录和文件进行“合并”。
因此OverlayFS更像是一个粘合剂,输出多个文件系统目录的“合集”。

https://github.com/linjc/smooth-signature![]() https://github.com/linjc/smooth-signature
https://github.com/linjc/smooth-signature
定义input被选中时候的颜色


忘掉 y 轴的截距吧,长远来看,斜率是唯一重要的事情。
如果 x 轴表示时间,y 轴表示你要实现的目标,那么实现目标的过程可以画成一条直线。
这条直线可以用两个变量描述:y 轴截距(直线与 y 轴的交点)和斜率(y 随时间变化的速度)。
如果我们把 y 轴截距看成是你的起点,那么斜率就是你为了实现目标,而适应、学习和付出努力的前进速度。
即使一条线的起点远低于另一条线,只要它的斜率更大,终究会超越前一条线。
你可能听过这样的建议:做一个终身学习者,每天学一点,不断进步。很少有人能够遵循这条建议,因为在开始后的很长时间内,根本看不到有什么效果。时间周期越短,直线看起来越平坦,当你远远落后时,这是非常令人沮丧的。
但是,只要坚持下去,保持向上的斜率,长期以后,你将远远地超越原来的人生道路。
记住,短期总是比我们想象的要长,各种打击足以让你灰心丧气,但是 长期总是比我们想象的要短。
同一个道理,在招聘时,有潜力但经验不足的候选人,长期来看,比经验丰富但潜力不足的候选人,对公司更有帮助。
总之,当事情没有达到你的目标时,不要放弃,每一个伟大的事业都始于一个小小的念头。学习一项新技能,每天进步一点点,短时间内,一切看起来都是老样子,但是随着时间的推移,改进会持续累积起来,进步会越来越明显。
用户研究中,有一个众所周知的事实。如果你询问用户是否需要新功能,他们通常会大叫"是的"。毕竟谁会不想要更多的功能呢?
但是,等到发布以后,你才意识到用户可能不使用这个功能。
理财的核心原则,就是两句话:"增加收入,减少开支"。
但是,这两句话相互矛盾,需要不同的技能。增加收入通常需要花钱,提高获利潜力。减少开支意味着对于投资新事物持有保守态度,这种心态会阻止你赚更多的钱。
-- 《我的十条金钱规则》
科技爱好者周刊(第 182 期):新人优惠的风险 - 阮一峰的网络日志![]() https://www.ruanyifeng.com/blog/2021/11/weekly-issue-182.html
https://www.ruanyifeng.com/blog/2021/11/weekly-issue-182.html
20211102

read(file_fd, tmp_buf, len);基于传统的 I/O 读取方式,read 系统调用会触发 2 次上下文切换,1 次 DMA 拷贝和 1 次 CPU 拷贝。
发起数据读取的流程如下:
-
用户进程通过 read() 函数向 Kernel 发起 System Call,上下文从 user space 切换为 kernel space。
-
CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到 kernel space 的读缓冲区(Read Buffer)。
-
CPU 将读缓冲区(Read Buffer)中的数据拷贝到 user space 的用户缓冲区(User Buffer)。
-
上下文从 kernel space 切换回用户态(User Space),read 调用执行返回。
对于 Kafka 来说, 它主要用来处理海量数据流,这个场景的特点主要包括:
1. 写操作:写并发要求非常高,基本得达到百万级 TPS,顺序追加写日志即可,无需考虑更新操作
2. 读操作:相对写操作来说,比较简单,只要能按照一定规则高效查询即可(offset或者时间戳)
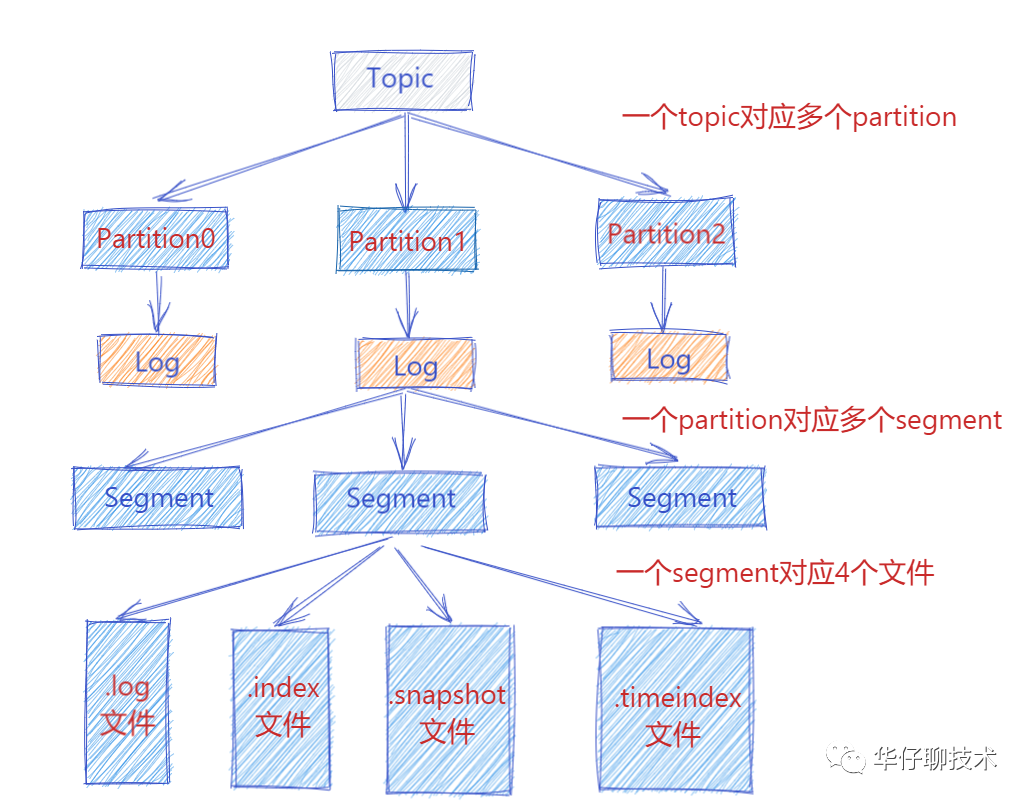
把消息的 Offset 设计成一个有序的字段,这样消息在日志文件中也就有序存放了,也不需要额外引入哈希表结构, 可以直接将消息划分成若干个块,对于每个块,我们只需要索引当前块的第一条消息的 Offset ,这个是不是有点二分查找算法的意思。即先根据 Offset 大小找到对应的块, 然后再从块中顺序查找.
这样就可以快速定位到要查找的消息的位置了,在 Kafka 中,我们将这种索引结构叫做 “稀疏索引”。














 4584
4584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









